 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetThe Cray XT5 Jaguar supercomputer at Oak Ridge National Laboratory (ORNL) is big in every respect. It’s big physically – the machine’s 284 cabinets sprawl across 5,700 square feet, a space slightly larger than a college basketball court. And it’s powerful – with its 182,000 processing cores, 362 terabytes of memory and a 10 petabyte file system, Jaguar is rated at 1.64 petaflops; making it the fastest machine in the world today for open science.

These impressive computational capabilities also make for a supercomputer that is ravenously hungry for power. Jaguar consumes up to seven megawatts, enough to power a town or small city. About half the power is used to operate the system, the other half to cool it. Right now power bills at supercomputing centers around the world are running into the tens of million dollars annually. But as planned upgrades move these centers into the exascale range, potential spending on power goes off the chart.
You might think that power and cooling problems of this sort is the exclusive domain of the big high performance computing (HPC) machines at major government scientific laboratories. That’s not the case. Smaller clusters operating in the terabyte range are just as prone to power consumption problems. This makes the greening of the data center a daunting challenge that must be addressed.
It’s no wonder that Sumit Gupta, senior manager of the Tesla™ GPU computing business unit at NVIDIA® reports: “Power consumption and the need for more energy efficient computing systems is top of mind for most of our customers.”
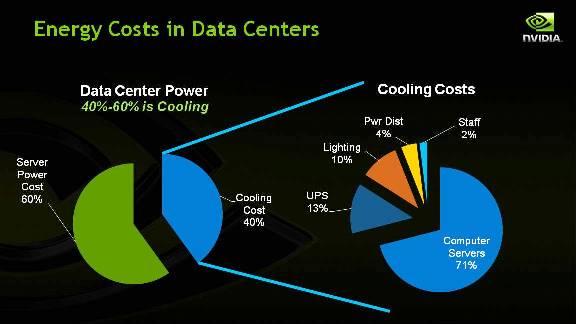
In fact, he emphasizes that the reason for the current intense interest in green computing is that data centers supporting scientific computation and enterprise HPC are in a power crisis. Gupta estimates that between 40% and 60% of the energy costs in these data centers is attributable to cooling (see chart below).
The fact is that traditional architecture for supercomputing just does not scale well. Back in the early 1980s, the first gigaflop machine, a Cray X-MP, required a modest 60 kW. By the mid-1990s, a one teraflop system required 850 kW. Today’s petaflop supercomputers with their megawatt appetites will look positively dainty compared to the 25 MW or more that the next decade’s exascale machines will need if current architectural trends continue unabated.
Supercomputing is a highly skewed field. Of the top 500 supercomputers, only a few, such as the machines at ORNL and Los Alamos National Laboratory, operate in the petaflop range. The vast majority of HPC clusters are all cruising along at less than 30 teraflops. But, pound for pound, their power challenges are just as daunting. For example, a small research cluster with 32 CPU servers valued at about $120,000 requires 21 kW of power for the servers alone. The annual cost for power and cooling runs almost $40,000 annually. The bottom line: In three years, you will have spent as much on these operating costs as you initially paid for the servers themselves.
Gupta notes that the new data center economics are having an impact on the academic community. Professors writing grants for additional HPC horsepower for their investigations are increasingly being asked by the university computing facilities to include power and cooling costs in their grant request. In the past, IT picked up the tab as an overhead expense.
Compounding the power/cooling problem is the fact that the computational capabilities of traditional HPC CPUs – including the latest multi-core CPUs – have not kept pace with the demand for computing performance on the part of researchers in science and industry. The more multi-core CPUs are added to a system, the greater the power and cooling requirements. Given this situation, being green is not only not easy, it’s almost impossible. Fortunately, recent advances in computer architecture point to a way out of this dilemma.
Going Green with GPUs
A promising solution that has recently become very popular is the use of GPUs for scientific computing. Although GPUs were initially designed as fixed function graphics chips, they have, over the years, become increasingly programmable.
In recognizing both a need and an opportunity, NVIDIA introduced a completely new GPU architecture that was designed from the ground up to be fully programmable; and function as both a graphics engine and a general purpose scientific processor. NVIDIA debuted the first GPU based on this new massively parallel architecture, called CUDA™, in 2006. This new architecture also allows developers to program to the GPU using traditional and high-level languages like C and Fortran. Since 2006, NVIDIA’s C language with CUDA extensions has been widely adopted with hundreds of applications and research papers published, many of which can be found on CUDA Zone.
The combination of advanced, programmable GPUs and CUDA has allowed NVIDIA to design processors and entire systems that provide supercomputing capabilities with an outstanding green performance per watt.
For example, one green computing powerhouse is the NVIDIA Tesla Personal Supercomputer (PSC). This supercomputer sits on your desktop and plugs into a standard office power socket. Containing up to four Tesla C1060 GPU computing processors, a Tesla PSC delivers nearly four teraflops of compute capability and provides application performance that is 250 times faster than traditional CPU-based PCs or workstations. This gives computational researchers and technical professionals a dedicated computing resource at their deskside that is much faster and more energy-efficient than a shared cluster in the data center.
The same high performance can be scaled to the data center by building clusters using the Tesla S1070 1U GPU systems. Whether building small research clusters or building out a petaflop cluster, Tesla S1070 GPU-based systems deliver unprecedented performance per watt.
GPU computing provides a co-processing environment that mixes multi-core CPUs and many-core GPUs for optimized performance and energy efficiency. Scientists, engineers and business users can handle the next generation of computing problems using advanced algorithms. The system’s incredible performance per watt means that IT managers can upgrade data center performance without expensive infrastructure modifications for power and cooling, and a big jump in energy bills.
Hybrid clusters with CPUs and GPUs can handle an extensive range of computationally intensive applications for a wide variety of industries. Just a few of the applications areas that can benefit from GPUs include: computational chemistry, fluid dynamics, digital content creation, financial market modeling, genomics, medical imaging, oil and gas exploration, and research and scientific computing.
Tesla Systems at Work – Greening the Data Center
Here are just a few examples of energy efficient NVIDIA Tesla systems at work:
- Temple University – An excellent example of energy efficient supercomputing that leverages a GPU-based solution is provided by Temple University. Researchers are running complex molecular dynamics simulations to devise better shampoos and detergents by discovering surfactants that more effectively attract dirt. Using a workstation powered by Tesla GPUs, they are achieving the same performance as a cluster of 32 dual-socket, quad-core CPU servers. The use of the NVIDIA system is not only generating savings in cost, space and power – in addition, the researchers are enjoying a major boost in productivity by being able to access a personal workstation at all times and reduce their dependency on the HPC cluster.
- Hess Corporation – The Hess Corporation is a leading global independent energy company. Its geophysicists use seismic data collected from the surface of oceans to “read” and interpret the sound waves, which travel at varying velocities as they pass through the different densities of rock, sand, salt, oil and gas.
“The challenge to geophysicists is how to accelerate the very time consuming task of analyzing data presented in flat, two-dimensional images to better understand the three dimensional subsurface geology,” says Mike Zebrowski, manager of Geoscience Development for Hess. “By using more of the data in a 3D visualization manner we can achieve a better understanding of seismic information.”
Using the CUDA parallel architecture, Hess developers were able to port 2D seismic code to a NVIDIA 32-node GPU-based cluster to speed up their explorations. The cluster replaced 2,000 CPU servers, a 20 times saving in capital expense. Savings also extended to the system’s power requirements, with server power requirements dropping from 1340 kWatts to 47 kWatts, a 28 times reduction. Power costs dropped accordingly, making for a much greener data center.
According to Scott Morton, Hess’s manager of geophysical technology, they plan to add another 80 GPU nodes to the cluster.
- BNP Paribas – This European leader in global banking and financial services relies on Tesla S1070 GPUs for their pricing algorithms. With eight Tesla GPUs, the performance matches a 500 CPU server cluster. But according to BNP IT managers, they are most excited about the energy saving that are achieving – one of their primary areas of concern.
A significant portion of the calculations – about one teraflop – performed for Global Equities and Commodity Derivatives is transferred to the NVIDIA GPU-based platform. This allows a 100-fold increase in the amount of calculation achieved per watt. The new NVIDIA platform consuming 2 kW replaces more than 500 traditional CPU cores that required 24 kW for power and cooling.
The massively-parallel, many-core architecture of Tesla GPUs delivers higher performance, and allow researchers and engineers in academia, government and business to tackle some of today’s most demanding applications – applications that previously could only be handled by massive supercomputers or clusters. But an added bonus is that these users can get the results they need without creating a major burden on the environment or the data center’s power and cooling budget.
High density computing allows data center managers to meet the constantly increasing performance demands of their users without corresponding demands on the center’s electrical and thermal capabilities. Because GPU-based systems combine supercomputer-level performance with significantly lower power and cooling costs, the goal of greening the data center is now mission possible.

























































