 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetIn high-speed computing (HPC), there are a number of significant benefits to simplifying the processor interconnect in rack- and chassis-based servers by designing in PCI Express (PCIe). The PCI-SIG, the group responsible for the conventional PCI and the much-higher-performance PCIe standards, has released three generations of PCIe specifications over the last eight years and is fully expected to continue this progression in the future with even newer generations, from which HPC systems will continue to see newer features, faster data throughput and improved reliability.
The latest PCIe specification, Gen 3, runs at 8Gbps per serial lane, enabling a 48-lane switch to handle a whopping 96 GBytes/sec. of full duplex peer to peer traffic. Due to the widespread usage of PCI and PCIe in computing, communications and industrial applications, this interconnect technology’s ecosystem is widely deployed and its cost efficiencies as a fabric are enormous. The PCIe interconnect, in each of its generations, offers a clean, high-performance interconnect with low-latency and substantial savings in terms of cost and power. The savings are due to its ability to eliminate multiple layers of expensive switches and bridges that previously were needed to blend various standards. This article explains the key features of a PCIe fabric that now make clusters, expansion boxes and shared-I/O applications relatively easy to develop and deploy.
Figure 1 illustrates a typical topology of building out a server cluster today, in which, while the form factors may change, the basic configuration follows a similar pattern. Given the widespread availability of open-source software and off-the-shelf hardware, companies have successfully built large topologies for their internal cloud infrastructure using this architecture.
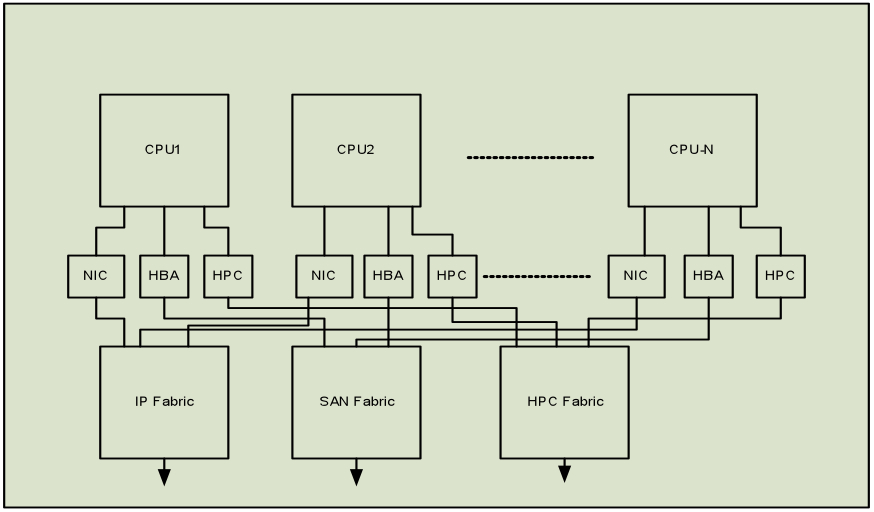
Figure 1: Typical Data Center I/O interconnect
Figure 2 illustrates a server cluster built using a native PCIe fabric. As is evident, the usage of numerous adapters and controllers is significantly reduced and this results in a tremendous reduction in power and cost of the overall platform, while delivering better performance in terms of lower latency and higher throughput.

Figure 2: PCI Express-based Server Cluster
Key Features of a PCI Express Fabric
Bandwidth and performance
The width of a PCIe port can range from one to 16 lanes. The 16-lane port configurations are primarily used in graphic applications, while the one-lane configurations are used in USB, wireless and other bridge applications. On a 16-lane port with each lane operating at Gen 3’s 8Gbps, a design can effectively achieve a data transfer rate of 15 GBytes/second and with a cut-through latency on the order of about 120ns.
Non-transparency
In a typical system, the PCIe device hierarchy is owned by a single host, and the operating system/BIOS allocates and controls all the memory resources to the devices within the system. If two PCIe hierarchies are connected, there is conflict and the system resources are allocated over one other. To avoid this problem, the system will use non-transparency, allowing address isolation between the two hosts. Each host allocates resources in the normal manner and when it discovers the PCI device with the NT port, it allocates resources as it would with any end-point based on the BAR memory setup. This address window can be used to tunnel and communicate between various hosts in the system. There is a mechanism built into the device that translates the address window on the receiving host system to a non-overlapping address space.
DMA
DMA engines are now available on PCIe switches, such as those from PLX Technology, which are quite versatile and have the standard descriptor fetch -> move data -> descriptor fetch approach with a lot of programmable pre-fetch options that allow efficient data movement directly between the memory of one host to that of another. The DMA engine in a PCIe switch serves a function similar to that of a DMA resource on a network or host-bus card, in that it moves data to and from the main memory. Figure 3 illustrates how an integrated DMA engine is used to move data, thus avoiding the need for using CPU resources in large file transfers. For low-latency messaging, the CPU can be used to directly use programmable IOs to write into the system memory of a destination host using an address window over NT.
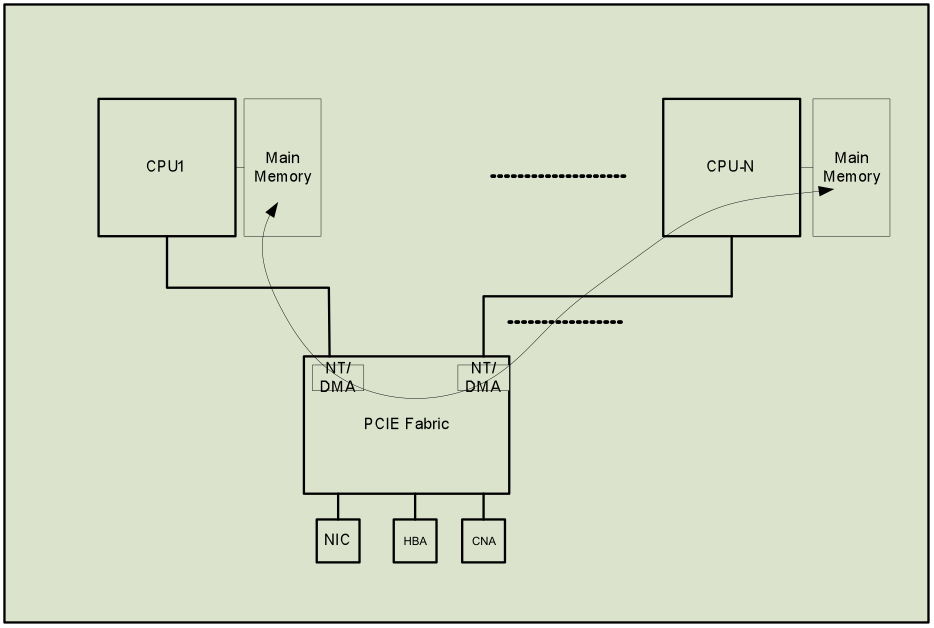
Figure 3: DMA engine embedded in a PCIe Fabric enables efficient data transfer
Spread spectrum isolation
Most systems turn on spread spectrum on the clock sources to reduce electro-magnetic interference on certain frequencies. All PCIe devices are required support spread spectrum clock sources, as long as the all the connected PCIe devices reference the same clock source the system will work. However, with PCIe cluster topologies, multiple domains need to support different spread-spectrum clocks and, hence, the need for spread-spectrum isolation. This feature allows two PCIe ports on different spread-spectrum domains to be connected through an isolation port.
Data integrity
The PCIe specification provides extensive logging and error reporting mechanisms. The two key data-integrity features are link cyclic redundancy check (LCRC) and end-to-end cyclic redundancy check (ECRC), with LCRC protecting link-to-link packet protection and ECRC providing end-to-end CRC protection. For inter-processor communication, ECRC augmented with protocol-level support provides excellent data protection. These inherent features, coupled with the implementation-specific robustness in the data path, provide excellent data integrity in a PCIe fabric. Data protection has been fundamental to the protocol, given ever-increasing requirement in computing, storage and chip set architectures.
Lossless fabric
A PCIe link between two devices guarantees delivery of packets with a rigorous ACK/NAK acknowledgment protocol. This eliminates the need for higher-level protocol per packet acknowledgement mechanism. The protocol does not allow for any device to drop a packet in transmission without notification. The situations where this could occur are primarily silicon/hardware failures and with the right Error Correction and Parity protection schemes the probability of such occurrence is statistically insignificant.
Congestion management and scaling
There is no inherent fabric-level congestion management mechanism built into the protocol, hence the topologies where PCIe shines is in the area of small- to medium-scale clusters of up to 200 nodes. For scaling beyond these numbers of nodes, a shared I/O Ethernet controller or converged adapter could be used to connect between the mini-PCIe clusters over a converged Ethernet fabric, as shown in Figure 4. Within the PCIe cluster, congestion management could be achieved by using simple flow control schemes among the nodes.

Figure 4 : Scaling a PCIe Fabric
Shared I/O
The basic concept in shared I/O is that the same I/O device is virtually shared between the many virtual managers (VMs) on a given host. This allows more of the software overhead that is currently being done in the hypervisor to be offloaded with native support onto the hardware. The PCI-SIG workgroup involved in this has defined both the single-root IO virtualization (SR-IOV) and multi-root IO virtualization (MR-IOV) requirements in the end-points, switches and root complexes. There is more traction in the industry on SR-IOV-compatible end-points than on MR-IOV. It is now possible to share I/O controllers among multiple hosts on a PCIe fabric by several different schemes.
Software
PCIe devices have been designed such that their software discovery is backward-compatible with the legacy PCI configuration model — an approach that’s been critical to the success of the interconnect technology. This software compatibility works well within the framework on a single host, however for multiple hosts there is a layer of software needed to enable communication between the hosts. Given that many clustering applications are already available for standard APIs from Ethernet and InfiniBand, there is active, ongoing development to build similar software stacks for PCIe that leverage the existing API thus reusing existing infrastructure.
Power and cost reduction using PCIe
With the elimination of protocol adapters at every node in a cluster, a reduction in I/O interconnect power consumption of up to 70 percent can be achieved. Due to the widespread usage and ubiquity of PCIe, the cost of switches, on a per-lane basis, is significantly lower than comparable performance-level switches. The protocol provides excellent power management features that allows for system software to dynamically shut down and bring up lanes by monitoring the usage and traffic flows. Additionally, active state power management (ASPM) allows for the hardware to automatically shut down the lanes when there is no traffic.
Flexibility and Interoperability
Each of the ports on a PCIe fabric can automatically negotiate to x16, x8, x4 or x1 widths based on a protocol handshake. In addition an x16 port can be configured as 2 x8s or 4 x4s which enables the systems designer complete flexibility on how he allocates his resources and can customize based on usage. Interesting techniques for acceleration and storage open up on a PCIe fabric since the graphics adapters and flash storage cards have PCIe interfaces that can directly connect to the fabric.
In summary, there are well over 800 vendors developing various kinds of solutions around the PCIe interconnect standard’s three generations. This has led to broad, worldwide adoption of the protocol and to a large percentage of the CPUs available in the market now having PCIe ports native to the processor. Given the low-cost emphasis on PCIe since its initial launch, the total cost of building out a PCIe fabric is an order of magnitude lower than comparable high-performance interconnects. As this I/O standard has evolved and become ubiquitous, the natural progression has been to use the fabric for expansion boxes and inter-processor communication. Dual-host solutions using non transparency have been widely used in storage boxes since 2005 but now the industry is pushing the fabric to expand to larger-scale clusters. Both hardware and software enhancements now make this possible to build reasonably sized clusters with off-the-shelf components. With the evolution of the converged network and storage adapters, there is an increased emphasis to pack more functionality into them, which pushes against the power and cost thresholds when every computing node needs a heavy adapter. A simple solution would be to extend the existing PCIe interconnect on the computing nodes to address the inter-processor communication.
Vijay Meduri is vice president of engineering for PCI Express switching at PLX Technology, Sunnyvale, Calif. He can be reached at [email protected].


























































