 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetThe case for utility supercomputing just got a lot bigger, literally. Cycle Computing has created a 50,000 core virtual supercomputer to assist in the development of novel drug compounds for cancer research. The cluster, codenamed Naga, sits in the Amazon infrastructure and is the biggest utility supercomputer yet. Using this mega-cluster, computational chemistry outfit Schrödinger was able to analyze 21 million drug compounds in just 3 hours for less than $4,900.
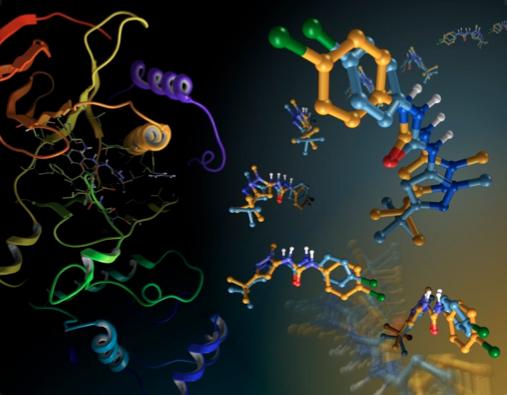
Developing a real compound, or assay, is very expensive, so before you do this you need to test all leads on a computer. Schrödinger and research partner Nimbus Discovery are working to identify important targets that have so-far been unsuccessful. They are looking for “hits” – a process that occurs very early on in the drug discovery cycle. After the hit stage comes the hit-to-lead phase and then lead optimization. Lead optimization produces a development candidate for human trials. But the process has to start somewhere, and that’s where virtual screening comes in. It’s the foundation for 2 to 5 years of discovery.
Schrödinger uses its proprietary docking application, Glide, to virtually screen different compounds against a potential cancer drug target. Out of a huge number of compounds, the computer model will whittle the initial pool down to the most worthy candidates. With Glide, as with most computer models, there’s a trade-off between accuracy and speed. Shortcuts are commonly employed to accommodate resource and time limitations.
Glide employs a series of progressive refinements, each an order of magnitude more computationally-intensive than the last. The first pass is performed with the fastest, least-accurate Glide algorithm, HTVS, which stands for, high-throughput virtual screening. About 10 percent of the initial candidates make it through to the next round, which is called SP, for standard precision. The third and final phase is XP for extra precision. This round takes 10 percent of the compounds from the previous run and outputs only the most worthy drug candidates, the ones most capable of affecting the targeted disease proteins.
The same tradeoff that allows researchers to analyze more compounds at a faster rate also leads to a significant number of false negatives and positives because the lower-quality algorithm may fail to identify good candidate compounds, while letting false positives slip by. The greater risk here is that potential blockbuster drugs are just passed over.
The utility nature of the Amazon supercomputer allows the scientists to skip the first step and move right to the second, more accurate mode. It also allows them to increase their compound set by a factor of three. So while normally they input 6 to 7 million compounds, they can now start with 21 million. Applying the higher-quality algorithm to a larger compound set reduces the problem of false negatives. The researchers are then able to identify the active compounds that would otherwise fall through the cracks.
While Schrödinger makes heavy use of its internal clusters, it requires additional resources for particularly compute-intensive workloads. With the Naga cluster, Schrödinger researchers were able to run this exceptionally large workload in record time, 21 million compounds and confirmations in just 3 hours. By comparison, running the same job on their internal 400-core cluster would take about 275 hours. Initial data sets are on the order of tens of gigabytes of molecule data, and depending on Internet bandwidth, uploading the data can take about 5 to 6 hours. Since the library of compounds is largely a static data set, it only needs to be updated once every six months or so.
“This project reflects the major trends we are seeing in medicine today. It’s the age of analytics and simulation, meaning big data and big compute,” remarks Cycle Computing CEO Jason Stowe. “We’re also seeing requirements on time-to-market and being capital-efficient. Building a 50,000 core infrastructure is a $20-30 million endeavor,” he adds.
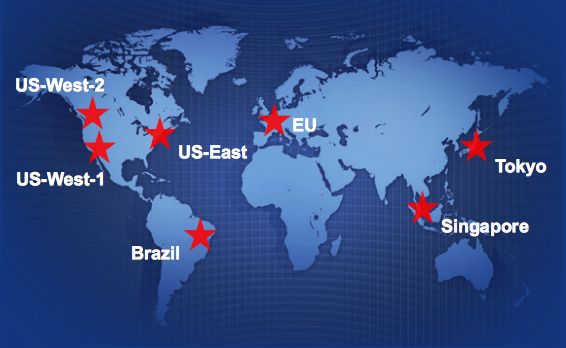
A map of the AWS compute resources harnessed during the Naga run
Next page >>>
A cutting-edge scientific research outfit, Schrödinger still has to face the economic realities that go along with being a small business. CEO Ramy Farid agrees that purchasing a system like this outright would be extremely expensive. Even more to the point, virtual screening is done sporadically. Farid estimates that over the course of a year, they do maybe 25 virtual screens at 3 hours each. While they do have other computational work to perform, it’s not enough to justify additional in-house resources, and certainly not a supercomputer of this ilk.
Farid points out that this dramatic increase in the number of processors lets you do better science. “It’s been like that since computing started,” he notes. As an example, Farid recalls the days when scientists had to intentionally omit hydrogen atoms on structures because computers just weren’t fast enough.
Schrödinger also uses the Cycle-based Amazon cloud to offload some of its lead optimization work, which involves doing calculations to predict binding affinity. Although not at the scale of the virtual screening process, lead optimization is still quite compute-intensive. Farid characterizes this work as the holy grail of computational chemistry, and using the Cycle setup, they’ve been able to take work that would require several months on a cluster down to a weekend on the cloud.
This speaks to the paradigm shift that Stowe is so passionate about. Despite the exponential advances in compute power driven by Moore’s Law, access to HPC resources is still one of the biggest constraints in research. Utility computing is creating a new dynamic by providing virtually unlimited computing power on-demand, and the user only has to pay for what they use. Researchers are accustomed to having to frame their questions according to the resources they have available, but the new model allows researchers to ask the most important questions, the ones that will actually move the science forward.
This 50,000-core cloud is the largest Cycle has constructed for a client, but the HPC software company has created a number of notable clusters. Last year, they did a 10,000-core run with Genentech, and a 30,000-core run with a top 5 pharmaceutical firm. Stowe points out that those organizations, however, were quite large, so theoretically-speaking, could have purchased a cluster of that size outright. What makes Schrödinger such an ideal use case, according to Stowe, is how Cycle and Amazon were able to provide a resource that otherwise would have been out of reach.
“Cycle Cloud automates the process of turning raw infrastructure into usual HPC environments,” says Stowe. “It’s like using a TOP500 supercomputer for a few hours and then turning it off.”
| Naga: Facts and Figures | |
| Metric | Count |
| Compute Hours of Work | 109,927 hours |
| Compute Days of Work | 4,580 days |
| Compute Years of Work | 12.55 years |
| Ligand Count | ~21 million ligands |
| Run Time | ~3 hours |
| Grand Total Cost at Peak: $4,828/hour ( $0.09 / core / hour ) | |
























































