 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetARM Holdings, along with seven other academic and industrial partners, is ramping up a European research project designed to bring accelerator programming to mainstream developers. Known as CARP (Correct and Efficient Accelerator Programming), the effort is focused on developing hardware-independent programming tools around OpenCL, the industry standard parallel computing environment for GPUs and other accelerators.
CARP is aimed primarily at mobile and embedded applications, but given the program’s emphasis on power efficiency, performance, and hardware independence, the work should have some cross-over into high performance computing, especially in areas like medical imaging and other types of scientific visualization.
Funded by the European Commission (EC), which kicked in $3.5 million, CARP is already up and running. Although the effort is designed to expire in three years, the hope is that the software and tools developed under the project will get some industry traction and be adopted more generally, or at least in Europe. One way to do that was to bring in commercial partners, who could potentially garner wider support. In ARM Holdings, they certainly have that partner.
Although ARM is most widely known for its CPU portfolio, it also develops GPU designs, the Mali family of graphics engines, which it wants to pair up with its Cortex CPUs. Since mobile and embedded platforms are extremely sensitive to power usage, the energy-efficient GPUs is increasingly the architecture of choice for a variety of visual computing and data streaming applications. In some cases, the GPU is a separate chip on the board, but in the mobile space especially, the graphics engine is now sharing silicon with the CPU on the same die.
That makes for a somewhat more natural programming model compared to having to deal with discrete processors for the host and accelerator. But ARM, and the mobile/embedded ecosystem in general, have the same problem with GPUs as everyone else, namely a developer community that is loathe to program in the low-level industry standard for accelerators: OpenCL. The CARP approach is to map domain specific languages (DSL) to OpenCL, using a translation layer, called portable intermediate language or PIL. The PIL compiler is the secret sauce here since it glues the high-level, programmer-friendly DSLs to the low-level OpenCL API. It also encompasses performance and power optimizations.
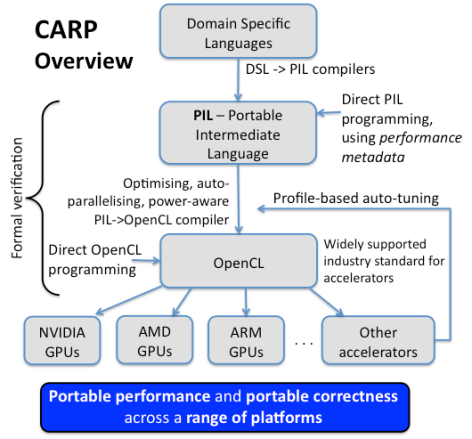
Once the OpenCL code is generated, the application should be able to run on any GPU or accelerator with the appropriate driver and compiler support. Since AMD, NVIDIA, and ARM all support OpenCL, that toolchain will encompass nearly every accelerator-equipped platform on the planet.
Along with ARM, CARP brings in three commercial European software firms (Realeyes, Monoidics, and Rightware), and four research partners (Imperial College London, INRIA, RWTH Aachen University, and the University of Twente).
As a first cut, the CARP technology will be demonstrated on the real-time eye-tracking algorithms of Realeyes, whose purpose is to discern peoples’ emotions by reading their faces. (Realeyes fancies itself the “Google Analytics of eye movements and emotions.”) While that may seem like an esoteric application, apparently there is an 800M€ market for such software. The goal here is to be able to use the CARP language tools to compute these algorithms in real-time across a variety of GPU-equipped platforms, including mobile devices.
ARM and Monoidics, which provides tools for formal verification, memory safety analysis, and security of software, will also be able to incorporate the resulting CARP technology into their own software development stacks. However, since the EC is funding this, the idea is for at least some of the tools to be made publicly available for other vendors and organizations.
Because of the mobile/embedded focus, energy efficient computing is a top priority for the compiler technology, as is runtime performance. And since this is not just an academic exercise, the resulting toolchain must also support portability, programmer productivity, and software correctness. In fact, the project has set some high goals for itself, including:
- Order-of-magnitude improvement in productivity of accelerator software development
- Performance of compiled code competitive with that of hand-optimized code, on multiple accelerator platforms
- Lower energy consumption by accelerated software, leading to greener systems, improved battery life in mobile devices, and wider availability on economical platforms
Whether CARP yields an accelerator technology acceptable to the industry or just becomes another brick in the Tower of Babel remains to be seen. It bodes well that ARM is involved since it embodies a large slice of the of the mobile/embedded computing ecosystem. The EC rules probably prevented it, but it would have been even better to sign up AMD, NVIDIA, and even Intel to the project, inasmuch as any widespread industry buy-in will eventually need all three. In the meantime, it will be interesting to see what Europe’s $3.5 million investment buys.

























































