 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetNVIDIA is once again highlighting some the Kepler hardware goodies that will come with the K20 chip, which is due out later this year. A blog post penned by NVIDIA engineer Stephen Jones, discusses the new ‘Dynamic Parallelism’ feature of the K20, a processor aimed at the supercomputing market.
Dynamic Parallelism enables an application task (called a stream, in GPU parlance) to spawn other tasks inside the GPU. The feature is supported by the presence of a “grid management” unit on the chip that allows tasks to be launched, suspended and resumed natively. Prior GPUs forced the application to return control to the CPU host to start up another kernel task. Essentially this allows more of the application to execute continuously within the GPU without having to bounce back to the CPU.
Jones illustrates how this works with the classic Quicksort program. Basically Quicksort slices up a list of items into sub-lists, and sorts them individually. As Jones writes,” It’s a classic ‘divide-and-conquer’ algorithm because it breaks the problem into ever smaller pieces and solves them recursively.”
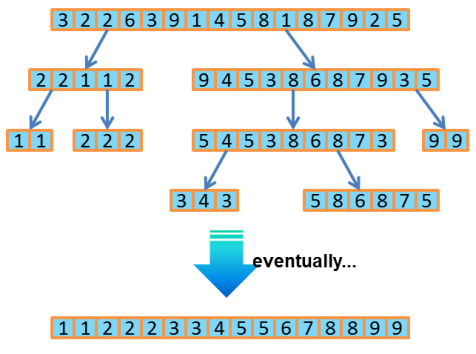
Prior to the K20 Kepler, the GPU would have had to return control to the CPU for each sub-list sort, and the application code would have to manage that back-and-forth rather inelegantly. With dynamic parallelism, the CUDA code is short and sweet, resembling a standard CPU-type implementation.
Not only should this make the programming the application more natural, but it also should increase performance since it eliminates much of the communication and context switching between the CPU and GPU. Also, since the grid management unit enables the tasks to be run concurrently on different parts of the GPU, even more performance can be extracted. Plus, it leaves more of the CPU free to do its own work, which can speed overall execution even further.
Any type of application that uses these divide-and-conquer algorithms can take advantage of this feature. It includes things like branch-and-bound algorithms, graph analytics, and adaptive meshing, to name a few. That encompasses a wide range of common HPC apps: CFD, mechanical stress analysis, weather codes, computational ray tracing — actually the list is rather large.
The only real disadvantage is for existing CUDA codes that were developed on pre-K20 GPUs. In these cases, the programs would have to be tweaked to take advantage of the new feature. For developing or porting new codes, this feature looks to be a no-brainer.

























































