 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street Big data is all the rage these days. It is the subject of a recent Presidential Initiative, has its own news portal, and, in the guise of Watson, is a game show celebrity. Big data has also caused concern in some circles that it might sap interest and funding from the exascale computing initiative. So, is big data distinct from HPC – or is it just a new aspect of our evolving world of high-performance computing? Should we care? Can we all get along together?
Big data is all the rage these days. It is the subject of a recent Presidential Initiative, has its own news portal, and, in the guise of Watson, is a game show celebrity. Big data has also caused concern in some circles that it might sap interest and funding from the exascale computing initiative. So, is big data distinct from HPC – or is it just a new aspect of our evolving world of high-performance computing? Should we care? Can we all get along together?
Distinct or Different Aspects of the Same Thing?
The distinction made between big data and HPC may arguably be attributed to events that transpired in the days when computers were people – that is, people using mechanical calculating engine. Statistics, probability, differential equations, numerical analysis, number theory and discrete mathematics all have different roots. While we think of them collectively as simply part of math, their practitioners see them, at best, in distinct clusters. The clusters have distinct traditions, lore, professional societies, meetings, journals and sometimes, distinct academic departments.
At this point in time, digital computation as we know it is deeply entrenched in the number- and data-crunching applications based on this math. Science and engineering rely heavily on differential equations and numerical analysis; code making and breaking depend on number theory and discrete mathematics; data-intensive applications use statistics and (perhaps) probability.
However, not all applications look the same computationally. Science & engineering applications deal mostly with continuous mathematics and focus on solving partial differential equations. Cryptography & cryptanalysis deal mostly with discrete mathematics. While both applications areas place serious demands on HPC architectures, those demands have been viewed as distinct enough to merit separate development paths. Both areas have been continuously at the forefront of HPC since the Second World War.
Until recently, “data-intensive” applications have been viewed from a computational perspective as not being all that intense. Much of the computation in this applications area has played out on workstations or clusters, using spreadsheets or relational databases. From an HPC perspective, data was a backwater – important, to be sure, but uninteresting computationally.
Now, things appear to be changing. Contemporary processor technologies, on the one hand, and the great expense of developing and fielding trans-petascale computers, on the other, seem to be blurring the boundaries between the “continuous” and “discrete” mathematics camps. Distinctions remain, but cooperation prevails.
At the same time, data has become “big” and its growth rates indicate that it will get much bigger very soon. Interest in this area has also increased dramatically. Traditional data applications have grown very large and are straining the limits of their technology. Meanwhile, a whole new class of applications for which relational databases don’t work well has sprung up – think social networking, counterterrorism, eScience. So, now big data is both important and interesting.
Now all of our HPC applications areas are interesting, two of them are pushing the limits of computer architectures, and the third – big data – is rapidly catching up. So maybe we should think of them as not so distinct, but simply as different aspects of the same thing. Let’s take a closer look at big data to see if this view is justified.
Advent of Big Data
Since the creation of the Web twenty years ago, data-intensive applications have slowly but inexorably become important. These early phases of digital data and data intensive applications developed outside the sphere of interest of those concerned with advancing numerically-intensive applications of science and engineering, except, perhaps, for a small group in the intelligence community. By and large, data-intensive applications were for transaction processing and customer relationship management – important to commerce but not challenging to the intellects of the science community.
Ten years ago, the age of social networks began with Friendster. The table below, based on Wikipedia data, shows the current sizes of a few of the currently more popular social networks (note recent news reports that Facebook has now passed 1,000,000,000 users).
|
Social Network |
Year Launched |
Active Users |
|
|
Number of Users |
Date of User Count |
||
|
|
2003 |
161,000,000 |
February 2012 |
|
|
2004 |
901,000,000 |
April 2012 |
|
|
2006 |
500,000,000 |
April 2012 |
|
Google+ |
2011 |
250,000,000 (registered) |
June 2012 |
The collection of all social networks and related services, such as cloud-based email and photo and video sharing, is sometimes called the geosocial universe. The rise of social networks and the geosocial universe is significant for many reasons. To name just a few:
- It marks a transition from a world with a few data/information providers to one where virtually anyone can be a provider;
- It exploits cognitive surplus and allows large numbers of people to collaborate, interact with, exchange, and analyze data, and publish their outcomes; and
- It has enhanced interest in and facilitated the development of:
- Open publication (e.g. arXiv, PLoS)
- Citizen Science (e.g. Fold.it)
- Social Network Analysis (e.g. LinkedIn Maps)
- Publicly funded research (e.g. Petridish)
- Publicly funded creative projects (e.g. Kickstarter)
- eGovernment and transparency (e.g. transparent-gov).
The advent of digital information from traditional sources, combined with that flowing from the geosocial universe, leads to predictions of enormous future data volumes in our digital universe. A recent CSC study cites a 4,300 percent increase in annual data generation by 2020 – by which time the global data volume is predicted to reach 35 zettabytes (or 35 billion terabytes). The claim is also made that, by 2020, more than 70 percent of the digital universe will be generated by individuals. But enterprises will have responsibility for storing, protecting and managing 80 percent of it.
So, the world of data-intensive computing has become intellectually rich, is poised to grow explosively, and needs all the help it can get.
Next >> Big Data Challenges
Big Data Challenges
The short version of the “challenges” story is: How do we design, develop and field an infrastructure to capture, curate, analyze, visualize, and use all of this data?
First, we distinguish among three different kinds of data:
- Observational Data – uncontrolled events happen and we record data about them.
- Examples include astronomy, earth observation, geophysics, medicine, commerce, social data, the internet of things.
- Experimental Data – we design controlled events for the purpose of recording data about them.
- Examples include particle physics, photon sources, neutron sources, bioinformatics, product development.
- Simulation Data – we create a model, simulate something, and record the resulting data.
- Examples include weather & climate, nuclear & fusion energy, high-energy physics, materials, chemistry, biology, fluid dynamics.
A useful summary of the current state of the “data deluge” has been provided by Fox, Hey and Trefethen and is drawn upon here. Since most data is yet to be collected, we focus here on data rates rather than absolute amounts. A very high level summary of some of the current or expected data rates in the three data categories is contained in the table below.
|
Data Type |
Data Rate |
Timing |
|
Observational |
|
|
|
Astronomy: Square Kilometer Array |
>100Tb/sec |
2016-2022 |
|
Medicine: Imaging |
>1EB/year |
now |
|
Earth Observation |
4PB/year |
now |
|
|
now |
|
|
Experimental |
|
|
|
Particle Physics: Large Hadron Collider |
15PB/year |
now |
|
Photon Sources: Advanced Light Sources |
7TB/hour |
2015 |
|
Bioinformatics: Human Genome Sequencing |
700Pb/year |
now |
|
Bioinformatics: Human Genome Sequencing |
10Eb/year |
future |
|
Simulation |
|
|
|
Fusion Energy |
2PB/time step |
now |
|
Fusion Energy |
200PB/time step |
2020 |
|
Climate Modeling |
400PB/year |
now |
One immediately notices that the data are hard to compare. The rates for observational data are probably the clearest. For example, if we assume that the Square Kilometer Array was to operate continuously at its full capability, then in the 2022 time frame it would be generating just under 400 exabytes per year. This would appear to make it the world’s largest single data generator.
But medical imaging, social data, or the Internet of Things might be larger by 2022. As for the Internet of Things, it is interesting to note the recent publicity about project TrapWire, which is purported to be networking a very large nationwide collection of security cameras and combining this with a predictive software system designed to detect patterns indicative of terrorist attacks or criminal operations. While data rates for this project are not available, it is reasonable to assume that they are very high.
Big Data Computing Platforms
Two HPC companies have been very visible in big data: IBM and YarcData (a Cray company). IBM has captured the big data high ground through its thrust to bring these applications to the enterprise and by using Watson to cleverly exploit large datasets and bring analytics to the foreground.
With its recent creation of YarcData, Cray has clearly stated its intention to focus on big data and to provide platforms (e.g. uRiKA, “a big data appliance for real time graph analytics”) and graph analytics solutions to the world. YarcData has also gained substantial visibility in the data analytics community through its Graph Analytics Challenge.
While specialized computers clearly have a role, for the immediate future most big data can probably be exploited on existing hardware. For example, note that the latest Graph 500 List includes five Blue Gene/Q systems in its top 10, shown below. (There are actually 11 systems in the “top 10,” since Mira and Sequoia, the Blue Gene/Q systems at Argonne and Livermore, are tied for first place.)
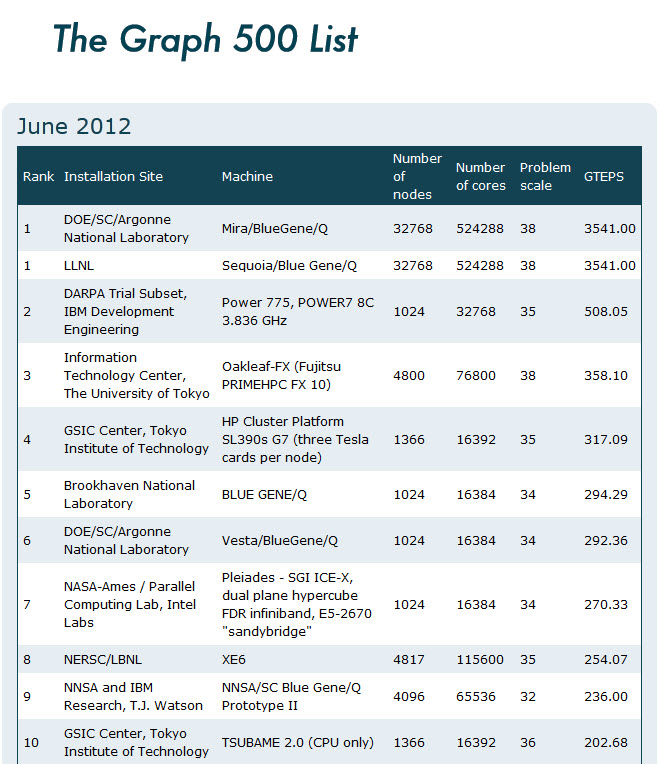
Also recall that the current TOP500 list contains four Blue Gene/Q systems in its top 10, including the number one machine, Sequoia. Furthermore, none of the machines listed in the top 10 on the Graph 500 list are specialized, data-crunching engines. That could, of course, change. A new Graph 500 list should be published next month, so we’ll have an opportunity to review the situation.
As big data applications succeed and grow, they will eventually need petascale and exascale computing resources. Thus, it would be useful to explore key big data applications in depth and extract an understanding of those attributes that place unique demands on system architectures. The benefits of doing this would be twofold:
- It would provide a firm basis for tuning or adapting system architectures to big data at the exascale; and
- It would provide the means to clarify the similarities and differences of number- and data-crunching at extreme scales to the broader HPC community.
Next >> Big Data Analytics Is Key
Big Data Analytics
The current key to success in big data is analytics. Data archiving, provenance, curation, protection and movement are serious issues, but they are currently known, under active study, and will probably be addressed in a more or less similar fashion across the globe. The discriminator for big data will be the hardware and software architecture and tools for analyzing the data efficiently and effectively. Note, in particular, that:
- Big data will live in the cloud – either the cloud as we currently see it, or an evolved cloud, shaped to meet the needs of big data.
- eScience will become a dominant mode of science and it will be a significant big data producer and consumer.
- Visual analytics will be a must for big data.
- While structured searches will remain a staple, unstructured searches and graph analytics applications may come to swamp them.
- Although software like MapReduce and Hadoop and their embellishments are probably here to stay, new approaches and programming models for big data analytics will need to be developed and implemented for many applications – especially those involving unstructured queries and graph analytics.
- Since big data will be impractical to move, the analytics may need to be pushed to the data, rather than pulling the data to the analytics, as is currently common practice.
- Compute engines may need to live inside the data (and thus inside the cloud). In fact, depending on the nature of the end-user application, this could turn some big number crunching computers into also being big, dedicated, data-crunchers, using in-situ analytics.
- While big data applications and exascale number-crunching applications may have some common requirements, like large memories and high bandwidth communications, computer architectures for big data will also need to accommodate unique requirements, like efficient non-local memory references and code execution that is difficult to predict.
Big Data Solutions for eScience
As defined by Wikipedia, eScience is computationally intensive science that is carried out in highly distributed network environments, or science that uses immense data sets that require grid or cloud computing. Current eSciences include particle physics, bioinformatics, earth sciences and social simulations.
In particular, particle physics has a well-developed eScience infrastructure because of its need for adequate computing facilities for the analysis of results and storage of data originating from the CERN Large Hadron Collider.
An excellent example of a big data solution for eScience is NASA’s new NASA Earth Exchange (NEX).
This new facility is a virtual laboratory that will allow scientists to tackle global Earth science challenges with global high-resolution satellite observations. NEX combines Earth-system modeling, remote-sensing data from NASA and other agencies, and a scientific social networking platform to deliver a complete research environment. Users can explore and analyze large Earth science data sets, run and share modeling algorithms, collaborate on new or existing projects and exchange workflows and results within and among other science communities.
NEX will be based around the NASA Ames Pleiades system, the world’s largest SGI Altix ICE cluster.
As science applications continue to evolve, it is to be expected that other disciplines will acquire significant eScience aspects. Thus, eScience is a key area for providing big data solutions.
Big Data Solutions for Dispersed Data
As mentioned previously, 70 percent of future big data is expected to be generated by individuals. Some currently known sources for such data include:
- Citizen Science – where individuals use their cognitive surplus to carry out science activities at home.
- Quantified Self – where individuals gather and analyze extensive amounts of data about their bodies and well-being.
- Aging at Home – where individuals use advanced sensor technologies to collect, analyze and make available to others that data which empowers them to remain in their homes rather than in an assisted living facility.
The whole area of dispersed data applications seems ripe for growth through the introduction of more intelligent nodes (in many varieties) and the local and remote big data computing, analytics and visualization to back them up.
Big Data is HPC
If your eyes haven’t glazed over by now, hopefully you’ve been persuaded that big data is another aspect of our rich and evolving world of HPC. Holding it at arm’s length makes a distinction that is increasingly without a difference. Furthermore, big data is rich in challenges that complement those posed by our usual science & engineering and cryptography & cryptanalysis applications. At the same time, HPC’s big iron is becoming very big and heterogeneous at many levels. Surely there’s room in there for big data.
About the Author
 Gary M. Johnson is the founder of Computational Science Solutions, LLC, whose mission is to develop, advocate, and implement solutions for the global computational science and engineering community.
Gary M. Johnson is the founder of Computational Science Solutions, LLC, whose mission is to develop, advocate, and implement solutions for the global computational science and engineering community.
Dr. Johnson specializes in management of high performance computing, applied mathematics, and computational science research activities; advocacy, development, and management of high performance computing centers; development of national science and technology policy; and creation of education and research programs in computational engineering and science.
He has worked in Academia, Industry and Government. He has held full professorships at Colorado State University and George Mason University, been a researcher at United Technologies Research Center, and worked for the Department of Defense, NASA, and the Department of Energy.
He is a graduate of the U.S. Air Force Academy; holds advanced degrees from Caltech and the von Karman Institute; and has a Ph.D. in applied sciences from the University of Brussels.


























































