 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street Our HPC cloud research stories are hand-selected from leading science centers, prominent journals and relevant conference proceedings. The top piece this week lays out a lightweight approach to implementing virtual machine monitors. Other items explore an innovative parallel cloud storage system, HPC-to-cloud migration, anywhere-anytime cluster monitoring, and a framework for cloud storage.
Our HPC cloud research stories are hand-selected from leading science centers, prominent journals and relevant conference proceedings. The top piece this week lays out a lightweight approach to implementing virtual machine monitors. Other items explore an innovative parallel cloud storage system, HPC-to-cloud migration, anywhere-anytime cluster monitoring, and a framework for cloud storage.
A Lightweight VMM for a Multicore Era
While traditional virtualization, using virtual machine monitors (VMMs) holds many efficiency advantages, the HPC community has generally shied away from the technology because of the associated performance overhead and the increased potential for bugs and other vulnerabilities. A team of researchers from Xi’an Jiaotong University in China is tackling these challenges with a novel lightweight approach to the creation of VMMs.
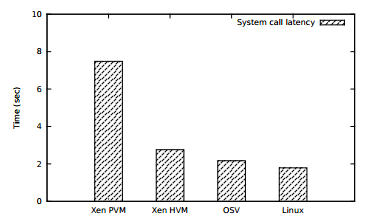 They note: “As resources in a multi-core server increase to more than adequate in the future, virtualization is not necessary although it provides convenience for cloud computing. Based on the above observations, this paper presents an alternative way for constructing a VMM: configuring a booting interface instead of virtualization technology.”
They note: “As resources in a multi-core server increase to more than adequate in the future, virtualization is not necessary although it provides convenience for cloud computing. Based on the above observations, this paper presents an alternative way for constructing a VMM: configuring a booting interface instead of virtualization technology.”
Their paper, Lightweight VMM on Many Core for High Performance Computing,” describes their experience with a lightweight virtual machine monitor they call OSV.
“Rather than virtualizing resources in the computer, OSV only virtualizes the multiprocessor and memory configuration interfaces,” they state. “Operating systems access the resources allocated by OSV directly without the intervention of the VMM, and OSV just controls which part of the resources are accessible to an operating system.”
OSV has the ability to host multiple Linux kernels with very little impact on performance, the team explains. It uses only 6 hyper-calls, while Linux, running on top of OSV, is intercepted only for inter-processor interrupts. The resource isolation is carried out with hardware-assist virtualization and the resource sharing is controlled by distributed protocols embedded in the operating systems.
Their test cases uses a prototype of OSV on 32-core Opteron-based servers with SVM and cache-coherent NUMA architectures. The setup supports up to 8 Linux kernels on the server with less than 10 lines of code modifications to the Linux kernel. With only 8,000 lines of code, OSV supports a streamlined tuning and debugging process. The final result of the experiment showed a 23.7 percent performance increase over Xen VMM.
HPC Clouds – Cloud Storage with OpenStack Swift
A team from Los Alamos National Laboratory has revealed how they used the Swift Object Store from OpenStack as their disk-based cloud storage system. For the team, Swift has provided an “open source software for creating redundant, scalable object storage using clusters of standardized servers to store petabytes of accessible data.”
 At the heart of this effort is to address growing HPC requirements on the archiving side. They note that just buying more tape or hard drives to keep up with demand is not a viable solution and they believe that “merging advanced features from both HPC systems and cloud systems is a promising direction.”
At the heart of this effort is to address growing HPC requirements on the archiving side. They note that just buying more tape or hard drives to keep up with demand is not a viable solution and they believe that “merging advanced features from both HPC systems and cloud systems is a promising direction.”
They reiterate that this is not a file system or real-time storage approach, but rather a “long term storage system for a more permanent type of static data that can be retrieved, leveraged and then updated if necessary.”
As the team behind the project states,
At LANL, we have worked on high-performance computing (HPC) systems for many years. The LANL parallel log file system (PLFS) has demonstrated its superior capability for the conversion of logical N-to-1 parallel I/O operations into physical N-to-N parallel I/O operations on HPC production systems. In this article, we describe the leveraging of the scaling capability of cloud object storage systems and the transformative parallel I/O feature (Fig. 1) of the LANL PLFS and the building of a parallel cloud storage system.
Bioinformatics in the Cloud
A new case study at IBM developerWorks lays out the steps involved in porting a massively parallel bioinformatics pipeline to the cloud. The transferring, stabilizing, and managing of massive data sets are all addressed by the team of IBM architects and engineers as are the architectural decisions that were necessary for this transformation.
 “
“Recent breakthroughs in genomics have significantly reduced the cost of short-read genomic sequencing (determining the order of the nucleotide bases in a molecule of DNA),” they write. “Therefore, to a large extent, the task of full genomic reassembly – often referred to assecondary analysis (and familiar to those with parallel processing experience) – has become an IT challenge in which the issues are about transferring massive amounts of data over WANs and LANs, managing it in a distributed environment, ensuring stability of massively parallel processing pipelines, and containing the processing cost.”
In describing their experience porting a commercial HPC workload for genomic reassembly to a cloud environment, the authors say it’s like going from a pure HPC environment to a more big data type of approach.
The impetus for the move is a familiar one: the HPC infrastructure was approaching capacity and the volume of the analysis work was expected to rise substantially. So the goal of the project was to test the feasibility of a massively scalable cloud infrastructure while keeping costs down.
Anywhere Anytime Cluster Monitoring
A trio of computer scientists from Shandong University in Jinan, China, are exploring the feasibility of anywhere, anytime cluster monitoring. More specifically, they are working to design and implement a cluster monitoring system based on Android.
 The team starts with the view that high performance computing (HPC) has been democratized to the point that HPC clusters have become an important resource for many scientific fields, including graphics, biology, physics, climate research, and many others. Still, depending on local funding realities, the availability of such machines is almost universally constrained. In light of this, monitoring becomes an essential task necessary for the efficient utilization and management of limited resources. However, as the researchers observe, traditional cluster monitoring systems demonstrate poor mobility, which stymies proper management.
The team starts with the view that high performance computing (HPC) has been democratized to the point that HPC clusters have become an important resource for many scientific fields, including graphics, biology, physics, climate research, and many others. Still, depending on local funding realities, the availability of such machines is almost universally constrained. In light of this, monitoring becomes an essential task necessary for the efficient utilization and management of limited resources. However, as the researchers observe, traditional cluster monitoring systems demonstrate poor mobility, which stymies proper management.
The authors are seeking to improve the flexibility of monitoring systems and improve the communication between administrators. They assert that the mobile cluster monitoring system outlined in their paper “will make it possible to monitor the whole cluster anywhere and anytime to allow administrators to manage, diagnose, and troubleshoot cluster issues more accurately and promptly.”
The system they developed is based on the Android platform, the brainchild of Google, and built on open source monitoring tools, Gaglia and Nagios. The design uses a client-server model, where the server probes the data via monitoring tools and produces a global view of the data. The mobile client gets the monitoring packages by Socket. Then, the cluster’s status is displayed on the Android application.
Their work was published as a chapter in the book, Pervasive Computing and the Networked World.
A Framework for Cloud Storage
UK computer scientists Victor Chang, Robert John Walters and Gary Wills set out to explore the topic of cloud storage and bioinformatics in a private cloud deployment. They’ve written a paper about their experience to serve as a resource for other researchers with data-intensive compute needs who are interested in analyzing the benefits of a cloud model.
 Among the many benefits of the cloud model are its cost-savings potential, agility, efficiency, resource consolidation, business opportunities and possible energy savings. Despite the inherent attractiveness, there are still barriers to overcome, and one of these, according to the authors is the need for a standard or framework to manage both operations and IT services.
Among the many benefits of the cloud model are its cost-savings potential, agility, efficiency, resource consolidation, business opportunities and possible energy savings. Despite the inherent attractiveness, there are still barriers to overcome, and one of these, according to the authors is the need for a standard or framework to manage both operations and IT services.
They write that “this framework needs to provide the structure necessary to ensure any cloud implementation meets the business needs of industry and academia and include recommendations of best practices which can be adapted for different domains and platforms.”
Their work examines service portability for a private cloud deployment. Storage, backup and data migration and data recovery are all addressed. The paper presents a detailed case study about cloud storage and bioinformatics services developed as part of the Cloud Computing Adoption Framework (CCAF). In order to illustrate the benefits of CCAF the authors provide several bioinformatics examples, including tumor modeling, brain imaging, insulin molecules and simulations for medical training. They believe that their proposed solution offers cost reduction, time-savings and user friendliness.


























































