 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetHPC Architectures
Current computer architectures have developed along two different branches, one with distributed memory with separate address domains for each node with message passing programming model and another with global shared memory with a common physical address domain for the whole system. The first category is present in massively parallel processors (MPPs) and clusters and the latter is present in the common servers, workstations, personal computers and symmetrical multiprocessing systems (SMPs) through multicore and multi-socket implementations. These two architectures represent distinctly different programming paradigms. The first one (MPP) requires programs that are explicitly written for message passing between processes where each process only has access to its local data. The second category (SMP) can be programmed by multithreading techniques with global access to all data from all processes and processors. The latter represents a simpler model that requires less code and it is also fully equivalent with the architecture and programming model in common workstations and personal computers used by all programmers every day.
Since clusters are composed of general purpose multicore/multisocket processing nodes, these represent a form of a hybrid of the two different architectures described above.
Numascale’s approach to scalable shared memory
Numascale’s NumaConnect extends the SMP programming model to be scaled up by connecting a larger amount of standard servers (up to 4096 with the current implementation) as one global shared memory system (GSM). Such a system provides the same easy-to-use environment as a common workstation, but with the added capacity of a very large shared physical address space and I/O all controlled by a single image operating system. This means that programmers can enjoy the same working environment as their favorite workstation and system administrators have only one system to relate to instead of a bunch of individual nodes found in a cluster. Besides, the SMP model also allows efficient execution of message passing (MPI) programs by using shared memory as communication channel between processes.
Distributed vs shared memory
In distributed memory systems (clusters and MPPs), the different processors residing on different nodes in the system have no direct access to each other’s memories (or I/O space). Data on a different node cannot be referenced directly by the programmer through a variable name like it can in a shared memory architecture. This means that data to be shared or communicated between those processes must be accessed through explisit programming by sending the data over a network. This is normally done through calls to a message passing library (like MPI) that invokes a software driver to perform the data transfer. The data to be sent was (most probably) produced by the sending process and such it resides in one of the caches belonging to the processor that runs the process. This will normally be the case since most MPI programs tend to communicate through relatively short messages in the order of a few bytes per message. The communication library will need to copy the data to a system send buffer and call the routine to setup a DMA transfer by the network adapter that in turn will request the data from memory and transfer it to a buffer on the receiving node. All-in all this requires a number of transactions across system datapaths as depicted in figure Figure 1.
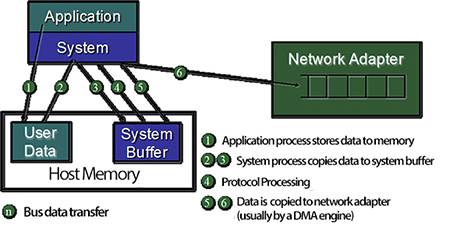
Figure 1, Message passing with traditional network technology, showing sending side only
In a shared memory machine, referencing any variable anywhere in the entire dataset is accomplished though a single standard load register instruction. For the programmer, this is utterly simple compared to the task of writing the explisit MPI calls necessary to perform the same task.
The same operation for sending data in the case of running a message passing (MPI) program on a shared memory system only requires the sender to execute a single store instruction (preferably a non-polluting store instruction to avoid local cache pollution) to send up to 16 bytes (this is the maximum amount of data for a single instruction store in the x86 instruction set as of today). The data will be sent to an address that is pointing to the right location in the memory of the remote node as indicated in figure Figure 2.
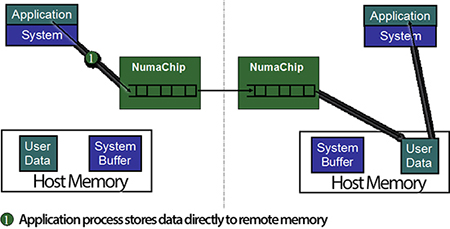
Figure 2, Message Passing with shared memory, both sender and receiver shown
Numascale’s technology is applicable for applications with requirements for memory and processors that exceed the amount available in a single commodity unit. Applications for servers that can benefit from NumaConnect span from HPC applications with requirements for 10-20TBytes of main memory for seismic data processing with advanced algorithms through applications in life sciences to Big Data analytics.
Deployment
Numa systems are available from system integrators world-wide based on the IBMx3755 server system and Supermicro 1042 or 2042 servers. Numascale operates a demo system where potential customers can run their tests. See Numascale website http://numascale.com for details, the request form for access to the demo system is http://numascale.com/numa_access.php.


























































