 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetFor the past few decades, the norm among the large government labs, academic research facilities and top commercial sites has been to deploy one large system per site at a time. However, more recently growing diversity of applications and end user community requirements, combined with non-overlapping budget and expanding technology lifecycles, has been driving a multi-cluster environment approach. Today it is typical to find two, three or even more, large systems at the same facility.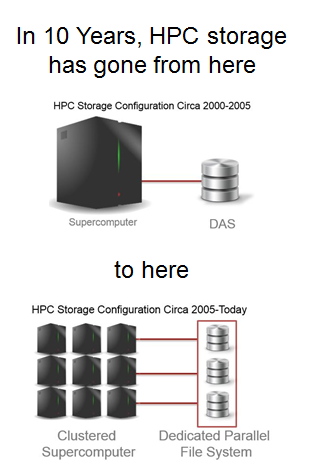
While people and organizations are accepting the need for and the benefits of multi-cluster environments, the storage side of the equation has some catching up to do.
10 to 15 years ago and we had simple DAS. Over the following decade the paradigm changed – the industry moved from simple DAS to a parallel file system, still typically serving just one clustered supercomputer.
After servers, storage is the second highest budget item for HPC sites’ hardware spend. So, if you take the traditional storage approach of one storage system for each cluster in a multi-cluster environment, this is a non-trivial expense. Not only do you wind up with inefficient utilization as well as slow, complex data sharing, backup and provisioning, but you’re also overbuying performance. And that is the biggest issue – performance is a more direct and measurable cost driver than complexity, inefficiencies and the other factors mentioned above.
So, what’s the answer? Well, if you examine the more pioneering HPC sites you will see a definite trend towards site-wide file systems. Even the sites with the most demanding workloads are finding they can meet their diverse application, end user, availability and performance goals more cost effectively with a single site-wide file system that requires them to only buy, grow, network, protect and maintain one central storage repository.
Examples are better than long explanations so let’s look at a site that has three clusters.

Assuming a law of averages, it’s expected that the majority of the peak I/O happens at separate times (randomly), since applications are bursting or doing heavy I/O only a fraction of any application runtime. Considering this fact, as well as other aspects of the HPC workflow, the facility has introduced a number of architectural and workflow inefficiencies into the cluster environment.
Specifically:
- The facility has purchased 100GB/s of combined throughput, where the peak requirement of any one cluster is half the total performance sold
- Performance utilization is low, as the resources are not shared across clusters, and single storage system performance is built for sporadic burst I/O from its dedicated cluster
- Data sharing across HPC clusters requires data copies and wall-clock wait times as applications move data between islands of storage
- The care and feeding of three separate storage resources is more complex and expensive than provisioning and maintaining just one
Leading computing organizations in the US such as TACC, NERSC and ORNL are promoting a new site-wide storage architecture strategy that enables cost savings, faster application burst performance, workflow efficiencies and a much simpler approach to deploying HPC resources.

By deploying a single site-wide file system:
- The customer saves on total storage purchase by sharing resources – you only build for the performance of your one fastest cluster!
- The total bandwidth of any one storage system is now the aggregate performance of all of the storage deployed in the site-wide file system. All of the clusters benefit from the storage cluster to potentially realize massive I/O performance gains (e.g. the smaller clusters above now perform I/O at 2x the prior rate, while also reducing storage cost);
- Applications get instant data access, eliminating needless data copies.
- Simplicity is the fourth dimension of value that comes from a site wide cluster strategy, but this predominantly applies to power users. For organizations that add to their computing environment periodically, it’s a massive benefit for them to not have to validate and test new storage architectures while they are shaking out new clusters – the storage is already online and ubiquitous.
Of course, moving to one site-wide file system means going all-in on one architecture. Organizations undergoing this transition need to take a serious look at the infrastructure before moving forward. They have to ensure that they are selecting storage and file systems that can handle current and projected capacities and throughputs across their application and user requirements, and do so reliably and cost-effectively. Open solutions that support multiple file systems so sites can change as requirements change and work with different types of collaboration, tiering and protection options offer the flexibility to avoid lock-in and dead ends.
The pioneering sites mentioned above, and in many more, have selected DataDirect Networks (DDN) as their storage of choice. Among the reasons:
- Wide and Deep Scaling – Customers can scale out to TB/s of performance, or scale deep capacity behind a small number of SFA storage appliances to always build to the precise levels of performance and capacity required while optimizing the cost of configuration at every step.
- Best-In-Class Performance – DDN supports leadership levels of both throughput and IOPS via its real-time, parallel storage processing architecture. So, whether you’re running DDN’s EXAScaler or GRIDScaler, or building Lustre or GPFS environments, DDN systems accelerate mixed workloads with a cache centric architecture designed for unpredictable I/O.
- Quality of Service – DDN systems mask the impact of drive failures from applications
 while also performing very fast drive rebuilds. As parallel file systems stripe data across 1000s of hard drives, DDN technology ensures the best production performance utilization and performance levels to deliver the highest levels of sustained application performance, thereby circumventing Amdahl’s law.
while also performing very fast drive rebuilds. As parallel file systems stripe data across 1000s of hard drives, DDN technology ensures the best production performance utilization and performance levels to deliver the highest levels of sustained application performance, thereby circumventing Amdahl’s law. - DirectMon™ and SFA APIs – One to 100s of file storage appliances can be managed simply from a single pane of glass. DDN built its platform from the ground up to truly scale in clustered storage environments.
The site-wide file system move is on. For both today’s petascale systems and tomorrow’s exascale machines, site-wide file systems address many of the IO bottleneck and scaling problems of more traditional approaches. DDN, as the storage selected for over 2/3 of the Top100, has the experience and the product portfolio to support site-wide file system projects at any scale.


























































