 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
It’s been nearly a year since the Intel Xeon Phi Coprocessor debuted at SC12, and in that time, it has experienced strong acceptance from the community. But as this is a relatively new technology, research into its usefulness is still forthcoming.
Adding to the growing body of research on the Phi is “Understanding the Costs of Many-Task Computing Workloads on Intel Xeon Phi Coprocessors,” written by a team of Illinois-based computer scientists and presented at the 2nd Greater Chicago Area System Research Workshop (GCASR) in May 2013.
The paper focuses on the opportunities for Many-Task Computing (MTC) to leverage the Intel Xeon Phi architecture. The programming paradigm that is Many-Task Computing (MTC) serves as a bridge between high-performance computing (HPC) and high-throughput computing (HTC). As the name implies, Many-Task Computing reflects the practice of running many computational tasks (dependent or independent) over a brief period of time. In MTC, metrics are most often measured in seconds (i.e., FLOPS, tasks/s, MB/s I/O rates), as opposed to operations (i.e., jobs) per month.
The impetus for the endeavor was explained thusly by the research team: “MTC has been well supported on Clouds, Grids, and Supercomputers on traditional computing architectures, but the abundance of hybrid large-scale systems using accelerators has motivated us to explore the support of MTC on the new Intel Xeon Phi accelerators.”
The crux of the researchers’ proposal is the creation of a new framework that “provides fine granularity for executing MTC applications across large scale compute clusters.” Integrating this capability into their existing graphics card framework, GeMTC, would “provide transparent access to GPUs, Xeon Phis, and future generations of accelerators to help bridge the gap into Exascale computing.”
The Intel Xeon Phi chip, aimed at highly parallel number-crunching, is the first product of Intel’s Many Integrated Core (MIC) architecture. In simple terms, the Phi coprocessor is an x86 based processor glued onto a PCIe 8x expansion card. The chip sports 60 cores, 4x hyper-threaded, for a total of 240 hardware threads, and stuffs just over 1 teraflop of double-precision performance in a single accelerator.
The first petascale adoption of Intel Xeon Phi coprocessors is Texas Advanced Computing Center’s Stampede system, which leverages 6,880 of these chips to arrive at 7.4 additional petaflops of peak computational performance. One of the most powerful supercomputers in the world, Stampede tops out at a total peak performance of 9.6 petaflops.
The paper seeks to provide a deep understanding of MTC on the Intel Xeon Phi architecture. The researchers test the performance of several different workloads using pre-production Intel Xeon Phi hardware and the Intel-provided SCIF protocol for communicating across the PCI-Express bus. With this setup, they achieve over 90 percent efficiency, a result that is close to or better than using OpenMP for offloading tasks over 300 uS.
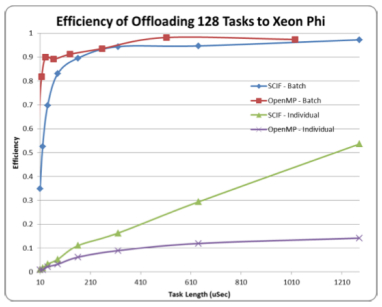
Comparison between OpenMP and SCIF with individual
offloads and batch offloads.
They write: “This performance opens the opportunity for the development of a framework for executing heterogeneous tasks on the Xeon Phi alongside other potential accelerators including graphics cards for MTC applications.”
The Intel Xeon Phi coprocessor is similar to other hardware accelerators such as general-purpose GPUs (GPGPUs) but there are important distinctions. Graphics cards, specifically GPGPUs, have become a popular means of providing parallelism for HPC applications. But extracting performance gains from GPUs means a retooling of the code, which can be time-consuming and requires considerable expertise. The claim from Intel is that the Phi provides a more familiar environment, which makes it easier to program.
The experiment employed a pre-production Xeon Phi – a 61-core version featuring 8GB of GDDR5 connected to the host via a PCI Express bus. One of these cores is reserved for the Linux OS. The authors note that with this platform, “it is possible to use OpenMP, POSIX threads, OpenCL, Intel Math Kernel Library, MPI, or other popular libraries to develop and offload applications to the accelerator.”
When the researchers compared the efficiency of offloading 128 tasks to Xeon Phi between OpenMP and SCIF with individual offloads and batch offloads, they found that jobs over 320 uS benefit from the SCIF framework when sent in this length of a batch with performance that was slightly above OpenMP.
The experiment shows it’s possible to achieve minimum overhead with the Xeon Phi by directly communicating between the host and accelerator via SCIF across the PCI Express bus. The preliminary results suggest that under the authors’ proposed framework, “the resources of a Xeon Phi could be shared across multiple processes and users in a large scale computing environment while maintaining high performance through the use of specialized microkernels.”
Just like GeMTC, the new framework would include three types off operations: Push/Poll for sending and receiving jobs, Malloc/Free for preparing device memory, and a memory copy operation to copy data to or from the accelerator. A tie-in to Swift/T could be used for multi-node configurations.
In the future, the research team will turn their attention to using the Phi for other science codes, including Molecular Dynamics applications, Protein Simulators and more.
Authors on this paper include Jeffrey Johnson, Scott J. Krieder, Benjamin Grimmer – all from the Illinois Institute of Technology – and Justin M. Wozniak (from Argonne National Laboratory), Michael Wilde (Argonne and the University of Chicago) and Ioan Raicu (Illinois Institute of Technology and the University of Chicago).
























































