 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Geospatial data is critical in a variety of applications – including transportation planning, hydrological network and watershed analysis, environmental modeling and surveillance, emergency response, and military operations. As the availability of geospatial data has expanded, its volume has accelerated, creating a variety of challenges and complexities that render traditional desktop-based geographical information systems (GIS) and remote-sensing software incapable of providing the requisite processing power.
Intel’s Many Integrated Core (MIC) architecture and the graphics processing unit (GPU) employ parallelism to achieve scalability with high performance for data-intensive computing over high-resolution spatial data. Our research has demonstrated that hybrid computer clusters equipped with the latest Intel MIC processors and NVIDIA GPUs can achieve a significant performance improvement for a range of typical geospatial applications, with Kriging interpolation, ISODATA, and Cellular Automata as examples. Details of our study are contained in a paper titled “Accelerating Geospatial Applications on Hybrid Architectures” in the proceedings of the 2013 IEEE International Conference on High Performance Computing and Communications & 2013 IEEE International Conference on Embedded and Ubiquitous Computing. The co-authors of the paper were Chenggang Lai, Miaoqing Huang, and Xuan Shi of the University of Arkansas, and Haihang You of the National Institute for Computational Sciences.
Coprocessor architecture
GPU architecture has been evolving for many years. Nvidia is a case in point, having gone through many generations, from G80 to GT200, Fermi, and today’s Kepler. The Kepler GPU architecture contains 15 streaming multiprocessors (SMXes), each of which consists of 192 single-precision cores and 64 double-precision cores. The Kepler architecture provides three advanced features to efficiently share the GPU resources among multiple host threads or processes (i.e., Hyper-Q), flexibly create new kernels on a GPU (i.e., dynamic parallelism), and reduce communication overhead across GPUs through GPUDirect. GPUs are normally used as accelerators in high-performance computer clusters. In a typical MPI-based parallel application, the MPI process executes on a host CPU that in turn allocates the computation to one or more client GPUs.
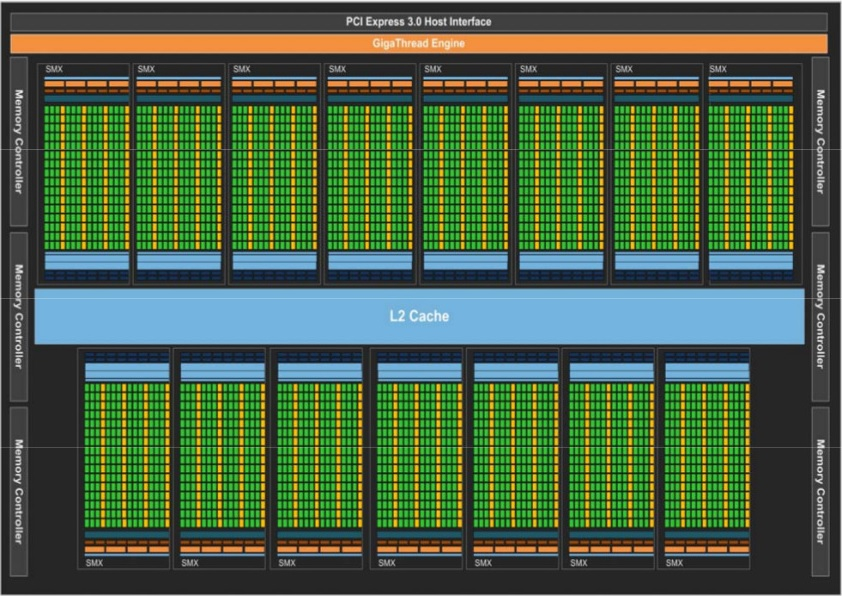
NVIDIA’s Kepler GPU architecture. Image source: Lai et al., “Accelerating Geospatial Applications on Hybrid Architectures,” Proceedings of the 2013 IEEE International Conference on High Performance Computing and Communications & 2013 IEEE International Conference on Embedded and Ubiquitous Computing, 1545–1552, 2013.
The first commercially available Intel coprocessor based on MIC architecture is Xeon Phi. It contains up to 61 scalar processors with vector processing units. Direct communication between MIC coprocessors across different nodes is also supported through MPI. The following images show two approaches to parallelizing applications on computer clusters equipped with MIC processors. The first approach is to treat the MIC processors as clients to the host CPUs. The MPI processes will be hosted by CPUs, which will offload the computation to the MIC processors. Multithreading programming models such as OpenMP can be used to allocate many cores for data processing. The second approach is to let each MIC core directly host one MPI process. In this way, the 60 cores on the same die are treated as 60 independent processors while sharing the 8 GB on-board memory on the Xeon Phi 5110P.

Offloading approach to implementing parallelism on the MIC cluster. Image source: Lai et al., “Accelerating Geospatial Applications on Hybrid Architectures,” Proceedings of the 2013 IEEE International Conference on High Performance Computing and Communications & 2013 IEEE International Conference on Embedded and Ubiquitous Computing, 1545–1552, 2013.

Direct-host approach to implementing parallelism on the MIC cluster. Image source: Lai et al., “Accelerating Geospatial Applications on Hybrid Architectures,” Proceedings of the 2013 IEEE International Conference on High Performance Computing and Communications & 2013 IEEE International Conference on Embedded and Ubiquitous Computing, 1545–1552, 2013.
Benchmarks
Three different types of use case served as the benchmarks for this study: Kriging interpolation (embarrassingly parallelism), the Iterative Self-organizing Data-analysis Technique Algorithm (ISODATA) (loose communication in the computation), and Cellular Automata (intense communication).
Kriging is a geostatistical estimator that infers the value of a random field at an unobserved location, and can be viewed as a point interpolation that reads input point data and returns a raster grid with calculated estimations for each cell.
ISODATA is one of the most frequently used algorithms for unsupervised image classification algorithms in remote sensing applications. In general, it can be implemented in three steps: (1) calculate the initial mean value of each class; (2) classify each pixel to the nearest class; and (3) calculate the new class means based on all pixels in one class. The second and third steps are repeated until the change between two iterations is small enough. When multiple processors are used, only one summation from all processors is required in each iteration.
Cellular Automata are commonly used in a variety of geospatial modeling and simulation. Game of Life (GOL), invented by British mathematician John Conway, is a well-known generic Cellular Automaton that consists of a collection of cells that can live, die or multiply based on a few mathematical rules. The universe of the GOL is a two-dimensional orthogonal grid of square cells, each of which is in one of two possible states, alive (‘1’) or dead (‘0’). Every cell interacts with its eight neighbors, which are the cells that are horizontally, vertically, or diagonally adjacent.
Experiment setup
We conducted our experiments on two platforms, the National Science Foundation-sponsored Keeneland supercomputer and Beacon supercomputer. Keeneland Initial Delivery System (KIDS) is a 201 Teraflop, 120-node HP SL390 system with 240 Intel Xeon X5660 CPUs and 360 Nvidia Fermi GPUs, with the nodes connected by a QDR InfiniBand network. Each node has two 6-core 2.8 GHz Xeon CPUs and 3 Tesla M2090 GPUs. The Nvidia M2090 GPU contains 512 CUDA cores and 6 GB GDDR5 on-board memory. The Beacon system (a Cray CS300-AC Cluster Supercomputer) offers access to 48 compute nodes and 6 I/O nodes joined by an FDR InfiniBand interconnect providing 56 Gb/s of bi-directional bandwidth. Each compute node is equipped with 2 Intel Xeon E5-2670 8-core 2.6 GHz processors, 4 Intel Xeon Phi (MIC) coprocessors 5110P, 256 GB of RAM, and 960 GB of SSD storage. Each I/O node provides access to an additional 4.8 TB of SSD storage. For each benchmark, we had three parallel implementations on two clusters. i.e., MPI+CPU, MPI+MIC, MPI+GPU.
Results



Performance of benchmarks on four different configurations: (a) Kriging, (b) ISODATA, (c) GOL. Image source: Lai et al., “Accelerating Geospatial Applications on Hybrid Architectures,” Proceedings of the 2013 IEEE International Conference on High Performance Computing and Communications & 2013 IEEE International Conference on Embedded and Ubiquitous Computing, 1545–1552, 2013.
We want to show the strong scalability of the parallel implementations. Therefore, the problem size is fixed for each benchmark while the number of participating MPI processes is increased.
In the Kriging interpolation benchmark, the source dataset is evenly partitioned among all MPI processes along the row-major. The computation in each MPI process is purely local, i.e., there is no cross-process communication. The problem size of this benchmark is 171 MB consisting of 4 datasets. The output raster grid for each dataset has a consistent dimension of 1,440×720. The performance of the GPU cluster with K20 is projected based on the speedup of the single K20 vs. M2090 and we assume that the other specifications of the K20 GPU cluster is same to the Keeneland KIDS. From this figure, it can be found that all hybrid implementation can easily outperform the parallel implementation on CPU with GPU further better than MIC.
The input of the ISODATA is a high-resolution image of 18 GB with a dimension of 80,000×80,000 for three bands. The objective of this benchmark is to classify the image into 15 classes. For this benchmark, it can be found that the gap between the MIC processor and GPUs becomes quite small. One reason is that the FDR InfiniBand network on Beacon provides much higher bandwidth than the QDR InfiniBand network on Keeneland KIDS. The advantage of more efficient communication network on Beacon is further demonstrated when the number of participating processors is increased from 100 to 120.
In the Game of Life benchmark, the grid size is 32,768×32,768. The status of each cell in the grid will be updated for 100 iterations. By observing the performance results, it can be found that the strong scalability is demonstrated for MPI implementations on both CPUs and GPUs. For the MPI+MIC implementation, it is found that the performance does not scale quite well due to the communication overhead among MPI processes. Therefore, it is critical to keep a balance between computation and communication for achieving the best performance.
Conclusion
In our study, we have shown the potential for accelerating geospatial applications using parallel implementation on hybrid computer clusters. MPI+GPU and MPI+MIC parallel implementations of representative geospatial applications achieve significant performance improvement compared with the traditional MPI+CPU parallel. It is also found that the simple MPI-direct-host programming model on Intel MIC cluster can achieve a performance equivalent to the MPI+GPU model on GPU clusters when the same number of processors are allocated. An efficient cross-node communication network is still the key to achieve the strong scalability for parallel applications running on multiple nodes. In general, geospatial computation consists of the functional modules to process (1) vector geometric data, (2) network and graph data, (3) raster grid data, and (4) imagery data. A variety of research challenges remain in deploying heterogeneous computer architecture and systems to handle different data structure and geospatial computation problems in the future.
The paper on this research can be accessed at http://www.csce.uark.edu/~mqhuang/papers/2013_gis_hpcc.pdf.
Research Team Bios
Miaoqing Huang is an Assistant Professor at the Department of Computer Science and Computer Engineering, University of Arkansas. His research interests include operating system and infrastructure design for manycore computer system, hardware acceleration technologies (such as FPGA and GPU), and on-board cache design in nonvolatile memory-based solid-state drives (SSDs). He earned his doctoral degree in computer engineering from The George Washington University in 2009. He can be reached at [email protected].
Xuan Shi is an Assistant Professor at the Department of Geosciences, University of Arkansas. His research interests include Geoinformatics, Geospatial Cyberinfrastructure, High performance geocomputation among others. He earned his doctoral degree in geography from the West Virginia University in 2007. He can be reached at [email protected].
Haihang You is a Computational Scientist at the National Institute for Computational Sciences, University of Tennessee. Prior of joining NICS, he was a research associate at Innovative Computing Laboratory, Dept. of Electrical Engineering and Computer Science, University of Tennessee. His research interests are High Performance Computing, Performance Analysis and Evaluation, Compiler & Automatic Tuning and Optimization System, Linear Algebra, Iterative Adaptive Discontinuous Galerkin Finite Element Methods, Parallel I/O Tuning on Lustre and System Utilization Analysis and Improvement on a Supercomputer. He can be reached at [email protected].
























































