 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
While they may share a number of similar, overarching challenges, data-intensive computing and high performance computing have some rather different considerations, particularly in terms of management, emphasis on performance, storage and data movement. Still, there is plenty of room for the two areas to merged, according to Indiana University’s Dr. Geoffrey Fox.
Fox and his colleagues have been working on offering a basis of comparison for different data-intensive computing paradigms, including blending the “best of both worlds” via an MPI and Hadoop approach. “The success and evolution of the Apache big data stack [which includes Hadoop] into a widely deployed cluster computing framework yields many opportunities for traditional scientific applications,” says the research team. They note that it’s difficult to use both of the paradigms interoperably and the divergence of the two areas will likely continue, especially with so much support from the commercially-driven open source side of the big data stack.
That support from around the globe across over 120 branch open source projects under the Apache umbrella (HBase, Mahout, YARN, Storm, etc.), which is driven by ever-increasing commercial data processing demand at large-scale datacenters, means that even if high performance computing wanted to stake a claim in the momentum, doing so independently would be almost impossible.
 The research efforts underway at the Netflix and Amazons of the world (not to mention many smaller shops) are driving the future of large-scale data-intensive infrastructure. But this doesn’t mean there’s no room for focusing on performance—one area that has hitherto been emphasized in software only and as something of an afterthought for many applications.
The research efforts underway at the Netflix and Amazons of the world (not to mention many smaller shops) are driving the future of large-scale data-intensive infrastructure. But this doesn’t mean there’s no room for focusing on performance—one area that has hitherto been emphasized in software only and as something of an afterthought for many applications.
The goal is to successfully bring the two data-intensive computing paradigms together to share the developments versus “reinvent the wheel” on either side. “It is possible to merge the two and try to produce environments that have the performance of HPC and the usability and flexibility of the commodity big data stack,” says Fox.
He notes that one area that can benefit from this hybrid HPC and big data model is in the area of machine learning—something that might not be HPC specifically, but is used in a number of computer science and commercial contexts. “Most of these algorithms are familiar to HPC because they have linear algebra at their core… Solve large-scale optimization problems like learning networks comes from a different world than HPC but look like HPC because it’s all very large parallel jobs with lots of optimizations for performance,” Fox explained.
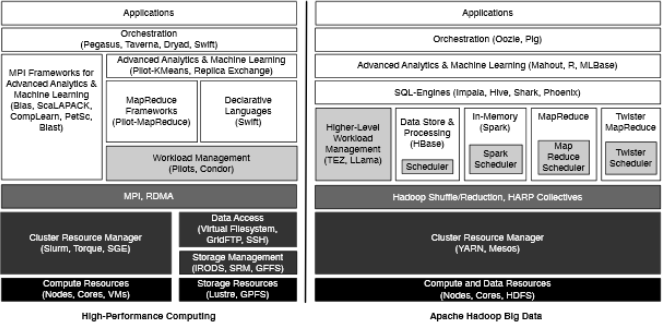
The solution is to find a way to blend Hadoop and MPI into “iterative MapReduce” to these problems. In essence, MPI and MapReduce are not entirely different, there are just different tradeoffs in terms of performance, fault tolerance, flexibility and such, but both are horizontally scalable and revolve around a single program model of data and applications. Fox says that during their comparison of different models, taking Hadoop to the MPI layer and integrating YARN with HPC schedulers represents this “best of both worlds” approach.
Using a K-Means example, MPI definitely outpaces Hadoop, but can be boosted using a hybrid approach of other technologies that blend HPC and big data, including Spark and HARP.
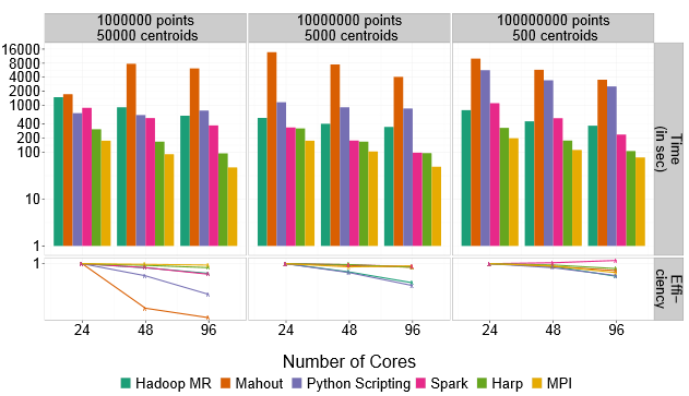
Many of the commercial environments that have already chosen one side of the data-intensive computing coin, however, would be adding an MPI layer of complexity to their Java-based applications. Alternately, this might require HPC to look to Java to run their codes—a potential re-invention of some wheels. However, Fox argues that in his extensive work on high performance Java, there are remarkable performance parallels between C, C++ and C# codes that have been ported to Java, which may mean it’s time for HPC to take an increasingly closer look to the dominant language in commercial big data—as well as to other higher level scripting languages, including Python.
More details about the implementation of the hybrid approaches can be found here: http://arxiv.org/pdf/1403.1528.pdf

























































