 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetIf you’ve been following the US exascale roadmap, then chances are you’ve been following the work of William (“Bill”) J. Harrod, Division Director for the Advanced Scientific Computing Research (ASCR), Office of Science with the US Department of Energy (DOE). In January, Harrod asserted that the DOE’s mission to push the frontiers of science and technology would require extreme-scale computing with machines that are 500 to 1,000 times more capable than today’s computers, albeit with a similar size and power footprint.
In line with Harrod’s assessment, DOE officials established a 10-year roadmap for achieving exascale computing. An associated study laid out the top 10 technical challenges, including – number one – energy efficiency that is 40 times better than today, and – number two – interconnect technology that fosters more efficient data movement.
A revised version of this report, Big Data and Scientific Discovery, zeros in on the challenges of the post-petascale era as they relate to the ubiquitous data explosion. As Alok Choudhary has observed, “Very few large scale applications of practical importance are NOT data intensive.” This new paradigm calls for major new advances in computing technology and data management.
In this updated report, Harrod maintains that it is no longer possible to handle computing and data challenges simply by scaling up from or modify existing solutions. The issue is further compounded by the need to share data and research across national and international borders. “Collaboration is inherently a ‘big data’ issue,” notes Harrod.
The DOE Office of Science outlines the four main scientific data challenges as follows:
- Workflows for computational science must drive fundamental changes in computer architecture for exascale systems.
- Breaking with the past: traditional scientific workflow – simulate or experiment, saving the data to disk for later analysis.
- Worsening I/O bottleneck and energy cost of data movement combine to make it impossible to save all of the data to disk.
- in situ data analysis, occurring on the supercomputer while the simulation is running.
To address these challenges as they relate to data management, analysis and visualization, DOE computer scientist Lucy Nowell has compiled a twelve-point approach, reproduced below:
1. Data structures and traversal algorithms that minimize data movement.
2. Methods for data reduction/triage that support validation of results and data repurposing.
3. Maintaining the ability to do exploratory analysis to discover the unexpected despite severe data reduction.
4. Knowledge representation and machine reasoning to capture and use data provenance.
5. Coordination of resource access among running simulations and data management, analysis and visualization technologies that run in situ.
6. Methods of in situ data analysis that minimize reliance on a priori knowledge
7. Data analysis algorithms for high-velocity, high-volume multi-sensor, multi-resolution data.
8. Methods for comparative and/or integrated analysis of simulation and experimental/observational data.
9. Design of sharable in situ scientific workflows to support data management, processing,
analysis and visualization.
10. Maintaining data integrity in the face of error-prone systems.
11. Methods of visual analysis for data sets at scale and metrics for validating them.
12. Improved abstractions for data storage that move beyond the concept of files to more richly represent the scientific semantics of experiments, simulations, and data points.
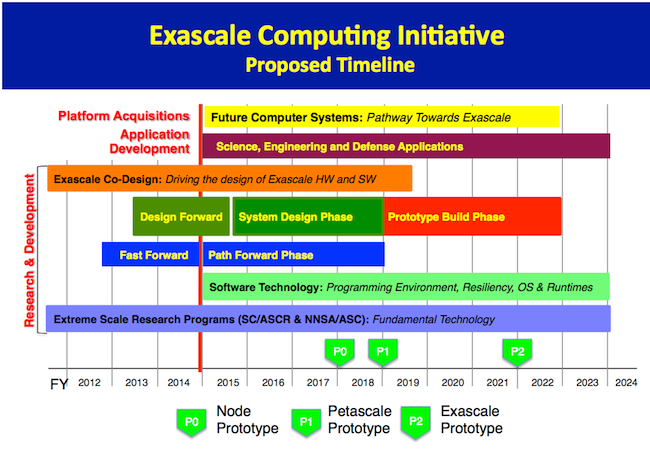
The proposed exacale computing initative timeline has also been enhanced to include more precise deliverables with a node prototype (P0) planned for early 2018, a petascale prototype scheduled for early 2019, and an exascale prototype on track for 2022.
























































