 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street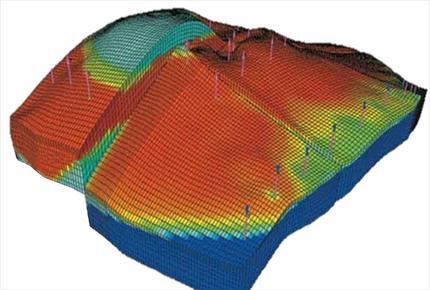
Danish energy company, Maersk Oil, has seen a number of technology trends evolve since its founding in 1962, particularly in terms of its ability to stay ahead of the unending race to new sources of hydrocarbons. The company’s research and technology team hasn’t been immune to the promises of cloud computing in its evaluations of potential options for powering critical simulations.
In a recent experiment in conjunction with the software company behind one of their core codes, Eclipse, which is a product from Schlumberger and Amazon Web Services, Maersk put the cloud to the test for its reservoir simulation runs.
While this experiment didn’t yield a great deal in terms of surprises performance-wise, it did raise some important questions about critical side topics in cloud for high performance computing codes. License models, overall cost, and the potential for “cloud gateway” services as delivered by companies like Panzura made this test use of public cloud resources noteworthy, even if the goal was not to come up with a world class-level infrastructure alternative.
In a recent conversation with Maersk’s head of server infrastructure, Thomas O’Reilly, he told us the intention of what the team did “was not to move our production HPC stuff into the cloud.” Rather, he says, “the point was to open a conversation about the possibilities of cloud in general and use this as an example of what might be possible.” The company provided a diagram to highlight their effort, emphasizing the differences between their bare metal environment, the cloud with multiple options in terms of configuration. He noted that the limitations to their test were Schlumberger’s requirements for running the code on certain CPUs, network cards, etc. as well as running before the newest generation of Amazon Ivy Bridge-based servers were available.

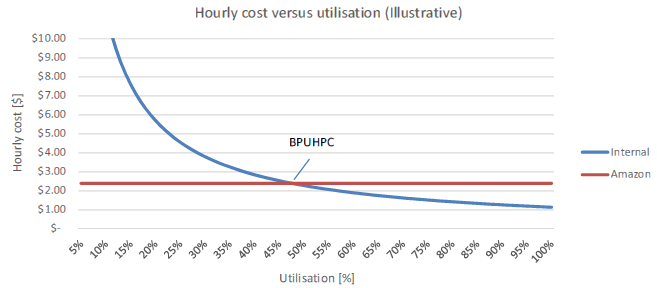
O’Reilly stressed that their collaborators, Schlumberger, whom allowed them to use limited code for the test runs, learned some important lessons about license modeling. The benefit here, says O’Reilly, is that can understand firsthand the possible value of a model that goes beyond per-core pricing.
In addition to being one of the most popular reservoir simulation codes, Eclipse is also one of the most expensive, with license costs in the millions if its deployed across a large cluster given its per core pricing structure and additional required modules. Ultimately, the test case proved the well-known concept that, for smaller companies, it’s possible to secure lower startup and maintenance costs. It also proved that for these users, especially with the newest Generation 3 upgrades with Xeon E5s and enhanced networking, reasonably good performance can be extracted for applications like Eclipse at a cost model that is palatable—as long as they’re not running 24/7. The problem is, most major oil companies are cycling through Eclipse or their code of choice endlessly.
With cost, performance, and licensing in mind, one might wonder why anyone would bother running a code like this on a large system if it doesn’t scale to high CPU counts. O’Reilly says these simulations can take probabilistic approaches where it runs every scenario to look for trends or deterministic simulations, which tap the knowledge of an expert reservoir engineer to point them to the best possible location for solid results to run a more focused simulation. In either case, they’re running “batches” against very large datasets and meshing the results together–divide and conquer style. This means two things for running these jobs in a cloud environment—first, these smaller runs can be nicely handled on cloud-based resources and held together within appliances like their Panzura boxes for access and sharing.
The team tried to keep the cloud configuration and use as close to real production as possible. On site they’re running the same Eclipse code around the clock with little to no downtime. Interestingly, they only have a three HP blades in their Infiniband-connected cluster with around 40 CPUs, says O’Reilly. This is because the code doesn’t scale well past that—something he says Schlumberger has an alternative to meet, called Intersect, but that they haven’t adopted.
This limitation in scalability frees them from maintaining massive clusters devoted to the code (and makes accelerators less appealing), there is no way around the need for ultra high bandwidth and low latency. That also sounds counter-intuitive to choosing cloud, but as we’ll get to in a moment, the team’s experiences were positive on the performance front, albeit at the small scale and without the real production demands for compute that a large house like Maersk requires.
All of this also means that the recent advances cloud providers like Amazon have put forth to beef up their network story could mean more customers since codes like this require Inifiniband connections (although O’Reilly pointed to some details that in the right situation, 10GbE could be effective).
























































