 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
For any large-scale datacenter, be it a scientific supercomputer or hyperscale web farm, the constant battles of “defensive I/O” and “offensive I/O” take their toll on overall efficiency and productivity. From checkpointing to pushing performance on long-running applications, one set of technologies is pushing its way onto the frontlines. The “burst buffer” concept, as Los Alamos National Laboratory’s Gary Grider called it five years ago, is taking aim at both dueling I/O concerns and proving itself worthy at massive scale.
Although not a new concept, the noise around burst buffers has been growing, especially at this past November’s supercomputing show where numerous vendors, from DDN, EMC, NetApp and others demonstrated their wares in the form of flashy arrays with on-board compute to handle both checkpoint and recovery in addition to boosting application performance and efficiency. The promise is multi-facted; in addition to serving as a pure storage option, these flash+compute-equipped dedicated nodes can also make storage smarter and more active—eventually to the point where this layer is built into the overall workflow in both capacity and compute terms.
“This is all based on pure economics,” Grider said. “And we predicted that all of this was coming several years ago when we did our first spreadsheet analysis that showed what was happening with bandwidth and capacity in disk drives versus flash.” The report, which can be found here, basically showed how even then, in 2009, right about now it was going to be far more economical to do checkpointing in flash then move it into disk later.
It’s worth noting that Grider was spot-on during his original economic analysis back in 2009 with where this might go. The original chart below shows the projected trajectory:
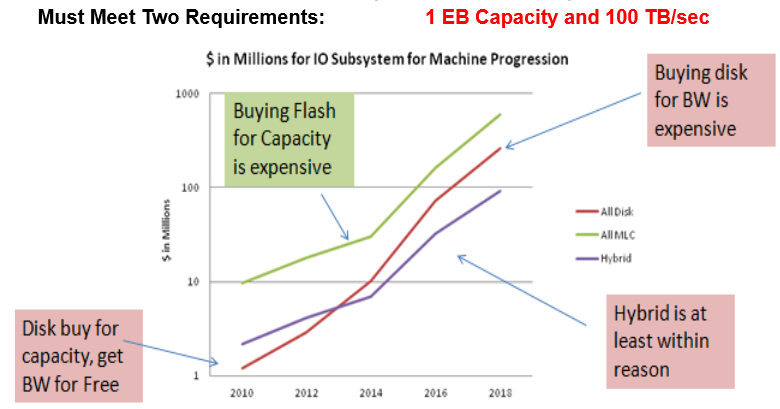
Despite some fluctuations in flash prices, the general trend is downward, which pushes this possibility, although it’s not just about large-scale datacenters having a cheaper route to reliable checkpointing. As the team continued to investigate burst buffers to tackle reliability, it became clear how many other uses were possible with flash and compute on a dedicated set of nodes. From debugging, data analysis, throwing in dynamic load modules and more, Grider and fellow researchers began to the see the light—the full spectrum of it. Since that time, much of his career has been devoted to moving the burst buffer message forward—but not without a few caveats.
As more research is pushed toward the idea, Grider and others hope it will be even more practical to look at burst buffers for supercomputers as more than pure storage and checkpointing devices. Eventually, as his pending work on the storage-focused Exascale I/O Fast Forward program reveals, it will be possible to ship function with the data that is shuttled over to the burst buffers, meaning that all of that structure that gives deeper meaning and possibility to otherwise idle data will no longer be squelched out by the file system’s serial bit tendencies. Instead, a complex (and still immature) software paradigm will let users take advantage of the smart, active nodes of the burst buffer to handle executables while at rest between data dumps.
Grider’s graphic showing how this plays out economically (and to some degree, practically) s in one of the newest systems, Trinity, adds some real-world context to what’s needed (not to mention possible).

While this makes sense at Trinity and future pre-exascale and exascale system levels, these same economics don’t exactly translate into the wider world. “This isn’t for everyone,” Grider said bluntly. “This is the biggest misconception, which often leads to the most questions.” He notes that while the vendor community and now, general technology masses, are being told that burst buffers can solve the world’s problems. Quite simply, unless it’s at very large scale, investing in burst buffers for general checkpointing isn’t often economically sound since far more nodes means way more failure (and many more checkpoint halts). Besides, many smaller IT shops aren’t dealing with multiple terabyte (or petabyte soon enough) dumps to make this reasonable. However, if they’re taking advantage of the active component of a smart storage approach (i.e. leveraging the compute on the nodes) it could be useful. He urged caution about this, but did note that it’s not rocket science to figure out if you’re going to benefit from it, especially for checkpointing.
Another host of questions Grider says he often encounters revolves around where burst buffers should live. His answer speaks more to what the next generation of supercomputing nodes will likely look like when the software troubles are smoothed, which will probably be flash-heavy servers that perform the same active, smart storage tasks. Currently, however, they reside in a separate set of nodes inside the supercomputer since centralizing minimizes complexity. Having more integrated flow between the flash, compute, disk, and applications is probably going to take around 5 years or more, says Grider. But again, his current research work (as well as the work of others on the programming side) is addressing some of this. In comparison to the other software challenges needed for exascale, however, he notes, solving the little burst buffer problem is nothing.
Government-funded labs are getting the I/O economics message, if nothing else. As Grider told us, this is really the first time that an RFP round has focused on anything other than compute and capacity. Storage and data movement are active parts of the discussion, which is no surprise since so much productivity is lost due to failures—and on point here, the checkpointing and dumping required to make those less painful.
“The dumps we’re doing on systems now are in the hundreds of terabytes range. In about two years, lots of machines are going to be doing this in the 2-5 petabyte range. If you dump that even at today’s sizes, you’re talking about over an hour to dump all the memory—and this is every four hours or so. That means every four hours you’ve lost an hour or more—and ultimately, that’s 25% of the machine that’s not being used for science. That’s the real economics argument just for checkpoint,” he said.
As reported this week, the new NERSC-8 “Cori” system had an option for a burst buffer built in to explore these possibilities and the other half of the joint RFP (the Trinity system) has the same goal of pushing to 90% efficiency. Since this can’t be done by adding cores and reducing power, minimizing the impact of checkpointing while eventually taking advantage of that time between bursts by doing meaningful work on that otherwise idle data promises a significant boost.
Just as Nick Wright and Katie Antypas told us this week during the NERSC-8 system announcement (okay, “Cori”), which was the other side of this RFP (Trinity announcement expected later this year), this will very likely be a component of exascale systems going forward. There is quite a bit of software work to be done, which will decide where these live and how they interface with the file system. Meanwhile, as the next generation of Lustre is being stapled together with this in mind by Grider and many others, we await news about which vendors are pushing burst buffers forward–and what the ultimate efficiency story will be.
























































