Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Exploiting the capabilities of HPC hardware is now more a matter of pushing into deeper levels of parallelism versus adding more cores or overclocking. What this means is that the time is right for a revolution in programming. The question is whether that revolution should be one that torches the landscape or that handles things “diplomatically” with the existing infrastructure.
While some argue for a “rip and replace” approach to rethinking code for the new era of computational capability, others, including Intel’s Director of Software, James Reinders, are advocating approaches that blend the old and new—that preserve the order of existing programming models while still permitting major leaps ahead for parallelism.
To these ends, Reinders described the latest release of Intel’s Parallel Studio XE 2015 for us this week, pointing to the addition of new explicit vector programming capabilities as well as the many features inside OpenMP 4.0., which is a significant part of the new release.
It’s not difficult to imagine the arguments in favor of holding steady with a consistent programming model for a manycore world, but few expect that slope will be simple to scale. At the heart of Intel’s approach to meshing the old and new approaches are some key features inside OpenMP 4.0, which Reinders says still amount to “hidden charms” that haven’t been fully explored by the HPC world yet. More specifically, he notes that three key elements to exploiting new hardware capabilities—tasking, vectorization, and offload—are not just present in OpenMP 4.0, they work together in unison and represent a turning point in how we will view the possibilities of preserving programming models and bases for the future generation of codes.
“The question is, can we keep the challenges limited to scaling across cores and vectorization to evolve into this new era instead—can we make that set of challenges the programming problem to solve versus learning exotic languages or abandoning the strong code base we have?” Reinders asked. In answer to this, he pointed to some new work his team at Intel, as well as partners around the world, are doing to enhance this possibility via OpenMP 4.0. in addition to their other Intel-specific math libraries and tools.
The issue right now with OpenMP 4.0 isn’t that the capabilities to achieve the new parallelism/existing programming environment goals. It’s still a matter of knowledge, training, and actual examples that show how the three goals of tasking, vectorization, and offload are working inside the same box with this newest release. Reinders says that the most frequent questions he’s getting now revolve around what’s inside the standard in general—it’s still in a “kicking the tires” phase that he hopes the community can move past, especially in this era of 244-way parallelism potential with the Xeon Phi.
He says some specific examples of the hidden charms of OpenMP 4.0 are contained within the new Collapse directive, which essentially lets the compiler handle the tasking across the cores in addition to vectorization at the same time. In another scenario, it would be possible to do offload and have a loop that addresses tasking and vectorization. In other words, users are doing messy things out of necessity to manage these aspects of performance gains with individual approaches instead of potentially tackling all three of the problems at the same time. The benefit of this is profound, Reinders argued, but said it’s still lost in the overwhelming early experimentation phase many are working through now.
The main addition to the release is explicit vector programming, which Reinders says is of increasing importance. This is an important feature because vectorizing will offer some profound performance improvements for HPC code, which also adds to overall efficiency since it can compute faster with the CPU being set at a lower power state. “The question these days is, how do we start getting codes to take full advantage of vector instructions in modern instruction sets. Languages like C and Fortran weren’t written with this in mind, so there have been a lot of hacks to hint to the compiler to vectorize over the years that aren’t so dissimilar to those were doing to get more parallelism in the 80s and 90s.”
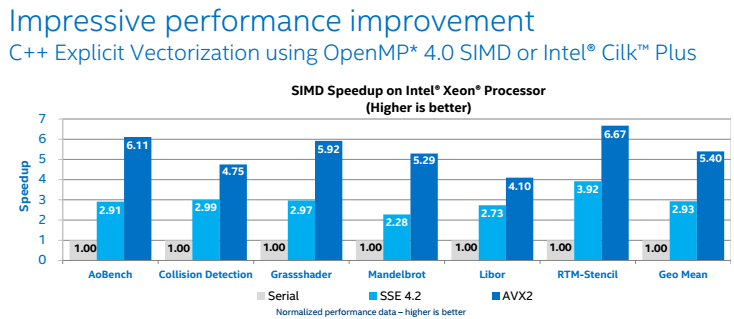
Now, instead of going back and forth with the compiler to get it to auto-vectorize, the goal is to extend the languages so they still look like C and Fortran and let the compiler know that you’re ready to vectorize a loop even if there are some problems embedded in the language itself. In OpenMP 4.0, this is achieved through Pragma OMP SIMD, which is designed to minimize code changes when vectorizing code. It can be used to vectorize loops that the compiler normally wouldn’t auto-vectorize without all the hacks. The graphic below highlights the minimal code change required with the associated performance boost.

“If you think about SSE, which we introduced more than a decade ago, it could do 2 double-precision numbers at a time or four single—and that was cool, said Reinders. “Then AVX comes along, which could do 8 single or 4 double precision floating point operations–but now we’re looking at Phi with AVX 512 and you can do 16 single floating point computations or 8 double-precision. It’s an incredible difference.
In other words, the hardware keeps finding ways to do more, but the difference between not doing vectorization versus doing it can be 16 to 1 with the Phi, for instance.”I’ve taught vectorization for a decade—it was one thing to get people excited about doubling code performance, but when it’s 16x it’s a big difference, too much to ignore.”
For those hoping to see what those performance improvements look like for other code, see the graphic below or find more details about the new updates in Parallel Studio here: https://software.intel.com/en-us/intel-parallel-studio-xe/