 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
A trio of partner projects based in Europe – Exanest, Exanode and Ecoscale – are working in close collaboration to develop the building blocks for an exascale architecture prototype that will, as they describe, put the power of ten million computers into a single supercomputer. The effort is unique in seeking to advance the ARM64 + FPGA architecture as a foundational “general-purpose” exascale platform.
Funded for three years as part of Europe’s Horizon2020 program, the partners are coordinating their efforts with the goal of building an early “straw man” prototype late this year that will consist of more than one-thousand energy-efficient ARM cores, reconfigurable logic, plus advanced storage, memory, cooling and packaging technologies.
Exanest is the project partner that is focused on the system level, including interconnection, storage, packaging and cooling. And as the name implies, Exanode is responsible for the compute node and the memory of that compute node. Ecoscale focuses on employing and managing reconfigurable logic as accelerators within the system.
Exanest
Manolis Katevenis, the project coordinator for Exanest and head of computer architecture at FORTH-ICS in Greece, explains that Exanest has set an early target of 2016 to build this “relatively-large” first prototype, comprised of at least one-thousand ARM cores.
He says, “We are starting early with a prototype based on existing technology because we want system software to be developed and applications to start being ported and tuned. For the remainder of the two years, there will be ongoing software development, plus research on interconnects, storage and cooling technologies. We also believe that there will be new interesting compute nodes coming out from our partner projects and we will use such nodes.”
In discussing target workloads, Katevenis emphasizes flexibility and breadth, echoing the sentiments we are hearing from across the HPC community. The goal for this platform is to be able to support a range of applications, both on the traditional compute and physics side and the data-intensive side. A look at the Exanest partner list hints at the kind of high-performance applications that will be supported: astrophysics, nuclear physics, simulation-based engineering, and even in-memory databases with partner MonetDB Solutions. Allinea will be providing the ARMv8 profiling and debugging tools.
Although the projects are still in the specification phase, they will be making selections with the aim of overcoming the specific challenges related to exascale. Areas of focus include compact packaging, permanent storage, interconnection, resilience and application behavior. Some of the design decisions were revealed in this poster from Exanest that shows a diagram of the daughterboard and blade design. Note that Xilinx is a key partner.
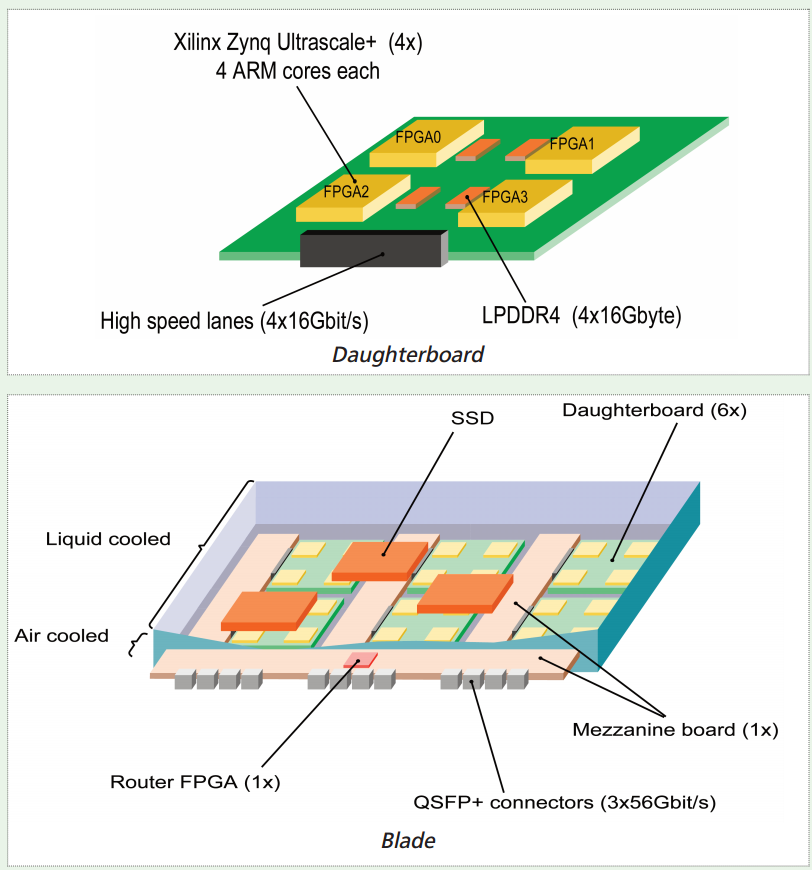
To achieve a complete prototype capable of running real-world benchmarks and applications by 2018, the primary partners are collaborating with a number of other academic groups and industry partners using co-design principles to develop the hardware and software elements. This is a classic public-private arrangement where academic and industrial partners join forces and industrial partners benefit by being able to reuse the technology that is developed.
On the technology side, packaging and cooling is a key focus for Exanest, which will rely on Iceotope, the immersive cooling vendor, to design an innovative cooling environment. The first prototype will employ Iceotope technology and there is the expectation that technology with even higher power density will be developed as the project progresses.
One of the primary criteria for the project partners is low-energy consumption for the main processor. They have chosen 64-bit ARM processors as their main compute engine. Katevenis affirms that having a processor that consumes dramatically less power allows many more cores to be packaged in the same physical volume and within the same total power consumption budget. “One way we will achieve scale is this low-power consumption,” says the project lead, “but another is by having accelerators to provide floating point performance boost to appropriate applications.”
As for topology, the Exanest team is discussing the family of networks that includes fat trees and Dragonfly topology. They will be linking blades through optical fibers that they can plug and unplug allowing them to experiment with more than one topology. Exanest will also be using FPGAs for building the interconnection network so they can experiment with novel protocols.
Exanode
Denis Dutoit, the project coordinator for Exanode, tells HPCwire the goal of that project is to build a node-level prototype with technologies that exhibit exascale potential. The three building blocks are heterogeneous compute elements (ARM-v8 low-power processors plus various accelerators, namely FPGAs although ASICs and GPGPUs may also be explored); 3D interposer integration for compute density; and, continuing the efforts of the EUROSERVER project, an advanced memory scheme for low-latency, high-bandwidth memory access, scalable to exabyte levels.
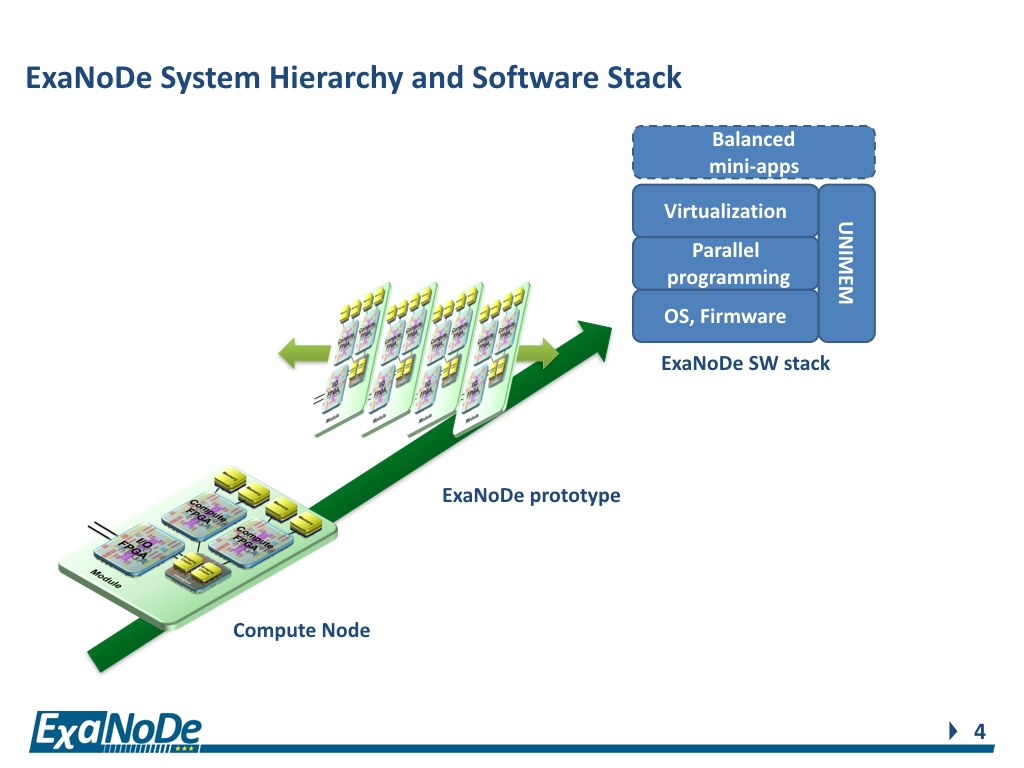
Dutoit, who is the strategic marketing manager, architecture, IC design and embedded software division at CEA-Leti, notes that this is a technology driven project at the start, but on top of this prototype, there will be a complete software stack for HPC capability. Evaluation will be done first will be done on the node level, explains Dutoit. They will utilize emulated hardware first and representative HPC applications to evaluate at the level nodes, but after that, Exanest will reuse these compute nodes and integrate them into their complete machine to do the full testing and evaluation with real applications.
There will be a formal effort to productize the resulting technology through a partnership with Kaleao, a UK company that focuses on energy-efficient, compact hyperconverged platforms.
Ecoscale
Iakovos Mavroidis, project coordinator for Ecoscale, says that while there are three main projects, he sees it as one big project with Ecoscale dedicated to reconfigurable computing.
A member of Computer Architecture and VLSI Systems (CARV) Laboratory of FORTH-ICS and a member of Telecommunication Systems Institute, Mavroidis notes that the main problem being addressed is how to improve today’s HPC servers. Simple scaling without improving technologies is unfeasible due to utility costs and power consumption limitations. Ecoscale is tackling these challenges by proposing a scale-out hybrid MPI+OpenCL programming environment and a runtime system, along with a hardware architecture which is tailored to the needs of HPC applications. The programming model and runtime system follows a hierarchical approach where the system is partitioned into multiple autonomous workers (i.e. compute nodes).
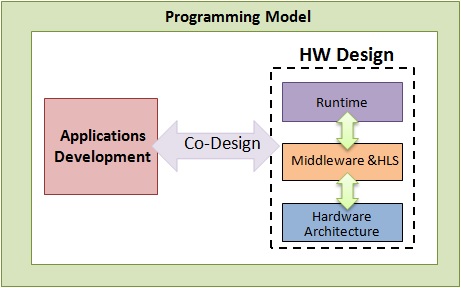
“The main focus of Ecoscale is to support shared partitioned reconfigurable resources, accessed by these compute nodes,” says Mavroidis. “The intention is to have a global notion of the reconfigurable resources so that each compute node can access remote reconfigurable resources not only its own local resources. The logic can also be shared by several compute nodes working in parallel.” To accomplish this, workers are interconnected in a tree-like structure in order to form larger Partitioned Global Address Space (PGAS) partitions, which are further hierarchically interconnected via an MPI protocol.
“The virtualization will happen automatically in hardware and it has to be done because reconfigurable resources are very limited unless remote access is enabled,” states Mavroidis. “The aim is to provide a user-friendly way for the programmer to use all the reconfigurable logic in the system. This requires a very high-speed low-latency interconnection topology and this is what Exanest will provide.”
Mavroidis explains there must be means for the programmer to access the system and at a higher-level the run-time system has to be redefined to understand the needs of the application so it can reconfigure the machine. He believes that in order to fully implement this, there will need to be innovation in all the layers of the stack, and also the programming model itself will also need to be redefined. The partners are aiming to support most of the existing and common HPC libraries in order to make this architecture available to most of the existing applications.
The main focus of Ecoscale is to automate out the complexity of FPGA programming. Anyone who has watched FPGAs struggle to get a foothold in HPC knows this is not an easy task, but the need for low-power performance is driving interest and innovation. “The programmer should not have to be aware that the machine uses reconfigurable computing, but rather be able to write the program using high-level programming model such as MPI or Standard C,” states Mavroidis.
On a related note, Exanest project partner BeeGFS has just announced that the BeeGFS parallel file system is now available as open source from www.beegfs.com. “Although BeeGFS can already run out of the box on ARM systems today, this project [Exanest] will give us the opportunity to make sure that we can deliver the maximum performance on this architecture as well,” shares Bernd Lietzow, BeeGFS head for Exanest.

























































