 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
The need for extreme scale computing is driven by the seemingly forever fledgling Internet. In abstract, the entire network is already an extreme scale computing engine. The technical difficulty, however, is to harness the dispersed computing powers for a single purpose. An analogy to this would be to build an engine capable of harnessing the combustive power of elements to move people or things. The presence of such an engine could drive transformative changes in technology, society and the economy.
The first requirement for such an extreme scale computing engine is the ability to gain incrementally better performance and reliability while concurrently expanding in size. We expect more from this engine than we do from a sports car. The “cost of doing business” should only include oil changes, tire and bearing replacements, but not re-building the car when a tire bursts or the engine upgrades. Unlike sports cars, technically, the extreme scale computing engine should run faster and more reliably when it expands for solving a bigger problem. While the top deliverable performance of the engine must be capped by the aggregate of available capabilities, there should be no loss in an application’s reliability when expanding in size.
Reliable distributed computing is hard. A 1993 paper entitled “The Impossibility of Implementing Reliable Communication in the Face of Crashes”[i] drew a “line in the sand.” It was proved that given a pair of sender and receiver, reliable communication between them is impossible if either one or the other could crash arbitrarily. It follows immediately that any distributed or parallel application that depends on fixed program-processor bindings must face the increased risk of crashes when the application expands, namely the “scalability dilemma.”
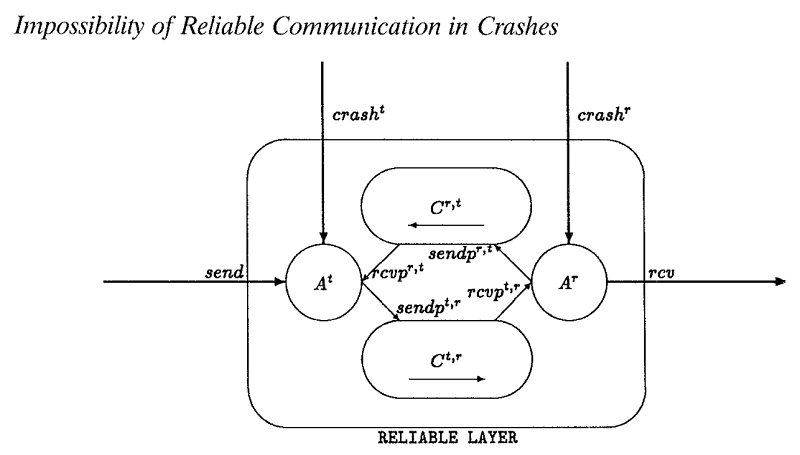 The corollary of the impossibility proof is that reliable failure detection is also impossible. Thus, fault detection/repair/reschedule schemes are technically flawed for extreme scale computing. In this context, “reliability” means “100% application reliability while the system affords greater than the minimal survivable resource set.” For any computing or communication application, the “minimal survivable resource set” includes “at least one viable resource at every critical path at the time of need.”
The corollary of the impossibility proof is that reliable failure detection is also impossible. Thus, fault detection/repair/reschedule schemes are technically flawed for extreme scale computing. In this context, “reliability” means “100% application reliability while the system affords greater than the minimal survivable resource set.” For any computing or communication application, the “minimal survivable resource set” includes “at least one viable resource at every critical path at the time of need.”
Ironically, the possibility of such a highly reliable system using faulty networks was also proved by the same authors[ii]. Today’s Internet is a feasibility study of the correctness of this proof. These two complementary studies somehow seem contradictory to most people. This confusion may be rooted in a widespread faulty assumption in distributed computing communities: the “virtual circuit.” It is widely taught and believed that a virtual circuit is “a reliable, lossless data transmission channel between two communicating programs.” Historically, this term was first created by the network communities to signify a clean “hand-off point” for computing communities. The trouble was that the computing professionals took the liberty to expand the virtual circuit definition to include the reliability of the communicating programs.
This was an unfortunate mistake. It crossed the “line in the sand.” This problem was quickly identified as the first fallacy – “the network is reliable” — in the “Eight Fallacies of Distributed Computing”[iii]. However, in the last three decades, the industry and research communities have continued to ignore the warning signs despite increasing service downtimes and data losses in today’s large scale distributed systems (including all mission critical applications and HPC applications).
The Stateless Parallel Processing (“SPP”) concept [iv]was conceived in the mid-1980s based on a practical requirement of a mission critical project called “Zodiac.” The requirement was very basic: Keep a distributed application running regardless partial component failures. It was inconceivable for national security to rely on any mission critical application that could crash on a single component failure. Technically speaking, mission critical programs and data must be completely decoupled from processing, communication and storage devices. Otherwise, any device failure can halt the entire application and expanding the processing infrastructure will inevitably result in a higher probability of service interruptions, data losses, and runaway maintenance costs. HPC applications are the first non-lethal applications to demonstrate these potentially disastrous consequences. The growing instabilities in large scale simulations have also already played a role in the investigation of the scientific computing reproducibility problems[v].
Methods for building completely decoupled applications are fundamentally different from those for “bare metal” applications. The first difference is in the design of Application Programming Interface (“API”). Technically, Remote Procedure Call (“RPC”), Message Passing Interface (“MPI”), share memory (“OpenMP”), and Remote Method Invocation (“RMI”) are all “bare metal”-inspired APIs. Applications built using these APIs force the runtime systems to generate fixed program-processor dependencies. They have crossed the “line in the sand.” The computing application scalability dilemma is unavoidable.
The <key, value=””>-based APIs, such as Hadoop, Spark, and Scality, aimed to relax the program/data-device dependency by allowing the runtime system to conduct failure detection/repair “magic.” These efforts have already shown significant scalability gains against “bare metal” approaches. Unfortunately, due to the influence of the “virtual circuit” concept, their runtime implementations have also crossed the “line in the sand.” The natural next step is to completely decouple devices from programs and data.
As the “Internet of Things” takes afoot, the “smart big sensing” challenge is on the horizon. In this context, an extreme scale computing engine is merely a necessity for survival. The existing distributed and parallel computing technologies are woefully inadequate.
Fundamentally, all electronics will fail in unexpected ways. “Bare metal” computing was important decades ago but detrimental to large scale computing. It is simply flawed for extreme scale computing.
Albert Einstein defined “Insanity” as doing “the same thing over and over again and expecting a different result”. Without a paradigm shift, we can continue to call anything “extreme scale” while secretly keeping the true extreme scale engine in our dreams.
References
[i] Alan Fekete, Nancy A. Lynch, Yishay Mansour, John Spinelli, “The Impossibility of Implementing Reliable Communication in the Face of Crashes,” Journal of the ACM, 1993.
[ii] John Spinelli, “Reliable Data Communication in Faulty Computer Networks.” Ph.D. dissertation. Dept. Elect. Eng. Comput. Sci., Massachusetts Institute of Technology, Cambridge, Mass., and MIT Laboratory for Information and Decision Systems report LIDS-TH-1882, June 1984.
[iii] Peter Deutsch, “Eight Fallacies of Distributed Computing,” http://www.ibiblio.org/xml/slides/acgnj/syndication/cache/Fallacies.html
[iv] Justin Shi, “Stateless Parallel Processing Prototype: Synergy”. https://github.com/jys673/Synergy30
[v] XSEDE 2014 Reproducibility Workshop Report, “Standing Together for Reproducibility in Large-Scale Computing”. https://www.xsede.org/documents/659353/d90df1cb-62b5-47c7-9936-2de11113a40f

























































