 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Deep learning has inspired a gold rush of technology innovation across a wide range of markets from Internet search, to social media, to real-time robotics, self-driving vehicles, drones and more. Spanning the gamut of machine performance, deep learning (and machine learning in general) encompasses floating-point-, network- and data-intensive ‘training’ plus real-time, low-power ‘prediction’ operations. Intel® Scalable System Framework (Intel® SSF) is an approach that customers can use as a tool to identify the right combinations of technology for machine learning and other HPC applications.
Training ‘complex multi-layer’ neural networks is referred to as deep-learning as these multi-layer neural architectures interpose many neural processing layers between the input data and the predicted output results – hence the use of the word deep in the deep-learning catchphrase. While the training procedure is computationally intensive, evaluating the resulting trained neural network is not, which explains why trained networks can be extremely valuable as they have the ability to very quickly perform complex, real-world pattern recognition tasks on a variety of low-power devices including sensors and mobile phones, as well as quickly and economically in the data center.
The Intel® Xeon Phi™ processor is but one part of Intel® SSF that will bring machine-learning and HPC computing into the exascale era. Intel’s vision is to help create systems that converge HPC, Big Data, machine learning, and visualization workloads within a common framework that can run in the data center – from smaller workgroup clusters to the world’s largest supercomputers – or in the cloud. Intel SSF incorporates a host of innovative new and upcoming technologies including Intel® Omni-Path Architecture (Intel® OPA) and Intel® Optane™ SSDs built on 3D XPoint™ technology – plus it incorporates Intel’s existing and upcoming compute and storage products, including Intel® Xeon® processors, Intel Xeon Phi processors, and Intel® Enterprise Edition for Lustre* software.
Computational nodes based on the first generation Intel Xeon Phi processors (code name Knights Landing) promise to accelerate both memory bandwidth and computationally limited machine learning algorithms, because these processors greatly increase floating-point performance while the on-package MCDRAM greatly increases memory bandwidth. In particular, the first generation Intel Xeon Phi processor contains up to seventy two (72) processing cores where each core contains two AVX-512 vector processing units. The increased floating-point capability will benefit computationally intensive deep-learning neural network architectures.
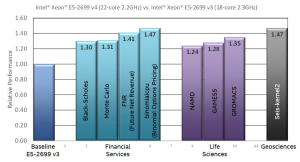
The just announced Intel Xeon processors E5 v4 product family, based upon the “Broadwell” microarchitecture, is the first Intel Xeon processor that is part of Intel SSF and can help meet the computational requirements of organizations utilizing deep learning. This processor family can deliver up to 47%* more performance across a wide range of HPC codes. In particular, improvements to the microarchitecture improve the per-core floating-point performance – particularly for the floating-point multiply and FMA (Fused Multiply-Add) that dominate machine learning runtimes – as well as parallel, multi-core efficiency. For example, a 47% performance increase means far fewer machines or cloud instances are needed to handle a large predictive workload such as classifying images or converting speech to text – which ultimately saves both time and money.
See the March 31, 2016 HPCwire article, “How the New Intel® Xeon® Processors Benefit HPC Applications”, for more information about the floating-point and other thermal, memory interface and virtual memory improvements in these new processors.
The Intel OPA specifications are exciting for machine-learning applications as they promise to speed the training of distributed machine learning algorithms through: (a) a 4.6x improvement in small message throughput over Intel’s previous generation fabric technology, (b) a whopping 70ns decrease in switch latency (think how all those latencies add up across all the switches in a big network)**, and (c) by providing a 100 Gb/s network to speed the broadcast of millions of deep-learning network parameters to all the nodes in the computational cluster (or cloud) plus minimize startup time when loading large training data sets.
Of course, Intel SSF includes software to utilize these hardware capabilities. The Intel Enterprise Edition for Lustre software is intended to help data scientists (and HPC scientists in general) manage their data in a global storage namespace plus utilize both storage and network hardware resources for high-performance and high-reliability so those same data scientists can always access their data quickly. Other products such as Intel® Parallel Studio XE 2016 helps programmers boost application performance by taking advantage of the ever-increasing processor core count and vector register width available in Intel Xeon processors, and Intel Xeon Phi devices.
Learn more about Intel Scalable System Framework >
* Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit http://www.intel.com/performance. Results based on Intel® internal measurements as of February 29, 2016.
** www.intel.com/performance/datacenter


























































