 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetAndrey Vladimirov of Stanford University has run a set of arithmetic benchmarks for HPC system provider Colfax International, comparing Intel’s new Sandy Bridge Xeon CPU with its Westmere predecessor. Although most tests show performance gains for the newest Xeon, some tasks showed little or no change at all. The results are provided in a white paper on Colfax’s website.
The study took a low-level approach to understanding the specific capabilities of each chip. Vladimirov focused on explaining how much performance to expect from each model of CPU and how users could achieve those numbers without delving into assembly code.
The benchmarks pitted an 8-core 2.7 GHz Sandy Bridge CPU against a 6-core 3.46 GHz Westmere processor. Here is the equipment used in the benchmarks:
|
System |
Westmere |
Sandy Bridge |
|
Processor |
6-Core X5690 |
8-Core E5-2680 |
|
Frequency |
3.46 GHz |
2.70 GHz |
|
Turbo Frequency |
3.73 GHz |
3.50 GHz |
|
Memory |
12GB |
64GB |
|
Memory Modules |
6 x 2GB |
8 x 8GB |
All tests were conducted using the Linpack and CIAO (Colfax Individual Arithmetic Operations) benchmarks, with the exception of the ‘Copy to/from RAM’ test, which was measured through the STREAM benchmark. Both systems were tested on scalar operations and SSE2 instruction sets, the Sandy Bridge system was also tested with the its new AVX (Advanced Vector Extensions) instruction set. Code was compiled using Intel’s C++ compiler
Using a single core, Sandy Bridge delivered 24.6 gigaflops for LINPACK versus 12.7 gigaflops by the Westmere chip. Utilizing all CPU cores for LINPACK, Sandy Bridge outperformed the Westmere 157.7 gigaflops to 71.8 gigaflops, respectively. Integer codes also performed better on the Sandy Bridge CPU, by a factor of 1.5 to 3.0, which apparently was a surprise since integer arithmetic is not able to use the AVX feature.
Vladimirov noted that performance gains provided by the Sandy Bridge processor depends on the type of application code. In general, the AVX instruction set, with its double-wide vector registers, is responsible for a lot of the floating point performance gains on Sandy Bridge. Also, additional performance is available thanks to its larger cache and higher RAM bandwidth. Notably though, division and square root operations were found to actually perform slightly worse than the Westmere chip.
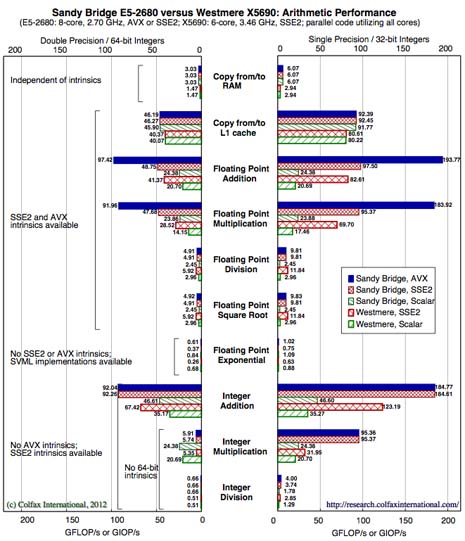
As long as the source code is available and was written with auto-vectorization in mind, users should be able to port their arithmetic codes to Sandy Bridge rather easily. And, unless the algorithm is heavily dependent on division and square root operations, at least some performance increase should be expected. In cases where the code is able to take maximum advantage of AVX and the better memory subsytem, application performance gains could easily be in the double digit range.
























































