 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
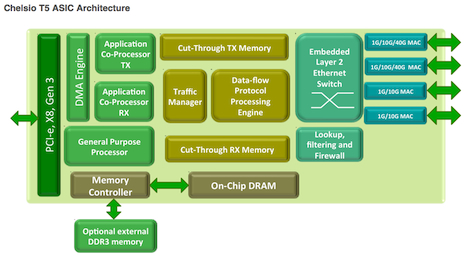
HPC & AI Wall StreetThis week Chelsio Communications unveiled its latest Ethernet adapter ASIC, which brings 40 gigabit speeds to its RDMA over TCP/IP (iWARP) portfolio. The fifth-generation silicon, dubbed ![]() Terminator T5, brings bandwidth and latency within spitting distance of FDR InfiniBand, and according to Chelsio, will actually outperform its IB competition on real-world HPC codes. According to Chelsio CEO and president Kianoosh Naghshineh, “the gap is essentially closed.”
Terminator T5, brings bandwidth and latency within spitting distance of FDR InfiniBand, and according to Chelsio, will actually outperform its IB competition on real-world HPC codes. According to Chelsio CEO and president Kianoosh Naghshineh, “the gap is essentially closed.”
Chelsio T5 ASIC sales are expected to ramp starting in Q2, while adapters based on the new silicon will roll out sometime later in the year. No pricing was given.
The T5, like its T4 predecessor, incorporates a TCP Offload Engine (TOE), iSCSI support, Fibre Channel over Ethernet (FCoE) and Network Address Translation (NAT) into hardware. But it’s the iWARP capability that is of special interest to HPC. While officially known as Internet Wide Area RDMA Protocol, iWARP is essentially RDMA over Ethernet, built on top of the ubiquitous TCP/IP protocol.
And like all RDMA-based technology (which includes HPC’s go-to interconnect, InfiniBand), iWARP has the ability to bypass the CPU for data copies that tend to bottleneck the system. Done right, iWARP can offer performance on par with that of InfiniBand, and is eminently suitable for HPC clustering. And since it’s running atop TCP, iWARP is general-purpose enough to work in much larger and more heterogenous networks.
Better yet, since it’s supported by the OpenFabrics Enterprise Distribution (OFED), Linux applications written for InfiniBand can run seamlessly on iWARP-compatible gear. There’s no need to write codes specific to the protocol. The OpenFabrics group appears to be committed to maintaining this support in its software stack for the foreseeable future.
As an industry standard ratified by the Internet Engineering Task Force (IETF), iWARP is now backed by Intel, Broadcom, and Chelsio. Although Chelsio is the smallest of the three vendors, at this point it appears to be out ahead of its larger competitors. With the introduction of the T5, it is the only vendor that has married 40 Gig bandwidth and microsecond-level latencies to iWARP-style RDMA. Both Intel and Broadcom have 10 Gig implementations, but they are based on somewhat older technologies.
Intel, which inherited its 10GbE iWARP technology and expertise via its acquisition of NetEffect in 2008 hasn’t talked much about the product roadmap. However, along with Chelsio and Broadcom, Intel has been a driver in the most recent IETF extensions to the iWARP standard.
That suggests the chipmaker is going to move the NetEffect technology into the 40G realm (and beyond) at some point. And since Intel has outlined a network fabric strategy that integrates adapter logic into the CPU, it’s reasonable to assume that iWARP silicon could show up on x86 processors in the not-too-distant future.
None of that seems to worry Chelsio’s Naghshineh. According to him, their TCP offload technology leads the pack, which is probably why they sold 100,000 iWARP ports just in the last 12 months. What the market needs now though is a broader ecosystem, and that includes a reasonable number of iWARP providers committed to the technology. If Intel and Broadcom move ahead with their plans, that could provide the needed critical mass. “I’m very happy they are entering this market,” Naghshineh told HPCwire.
Thus far, most of Chelsio’s success has come from deployments in storage and virtualized servers, where the various network offloads supported by the adapter ASICs are used to save CPU cycles and boost performance. Chelsio’s penetration into the HPC space has been less sure – just a few university and commercial HPC installation to date. That’s due to a variety of factors, including delays in deployment of 10GbE technology overall and a perceived lack of iWARP performance relative to InfiniBand.
From Naghshineh’s perspective, the latter is just a marketing problem. There have been a number of studies that demonstrate even 10G iWARP performance is comparable to InfiniBand on typical HPC applications. One such analysis, performed by Chelsio, shows the its older T4 technology can perform as well or better than Mellanox’s FDR InfiniBand on typical MPI apps: LAMMPS (molecular dynamics), LS-DYNA (finite element analysis), WRF (weather forecasting), and HPL (Linpack).
Despite the FDR gear delivering four times the network bandwidth and half the latency of the Chelsio hardware, the study showed that the T4 iWARP implementation held its own across this application set. And the results seem to indicate that as the application scales up, the advantage starts to tilt in favor of iWARP. Since the newer T5 silicon brings the adapter bandwidth nearly up to FDR speeds (40Gbps versus 56Gbps) and latencies into the coveted sub-microsecond realm, Naghshineh expects the newer silicon to outperform the latest and greatest InfiniBand technology.
According to him, once they reach 100G iWARP in 2015, there will be no difference in performance between that and EDR InfiniBand, even at the hardware level. Naghshineh says that’s because the underlying SerDes (Serializer/Deserializer) architecture is converging across the different network technologies and that will become the common denominator determining performance.
Since Ethernet has the much larger ecosystem of switches, cables, optical modules, and software relative to InfiniBand, the economies of scale will naturally favor the high-volume solution, he maintains. And if performance and price are truly no longer differentiators between the two technologies, HPC users will come around. “InfiniBand has been a good solution to date, says Naghshineh. “It made sense to use it, but now the gap is essentially closed.”


























































