 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetIn this series of articles, Kevin D. Franklin and Karen Rodriguez’G examine computational tools and approaches at the interface of humanities, arts and social science.
Cultural Analytics
Hypertext. Hypermedia. High Performance Computing. It’s enough to make a humanities scholar hyperventilate. A debate has raged in the last decade (at least) about whether or not the Digital Age will see the death of The Book, The Library and perhaps, The Humanities more broadly. Part of the debate resides in the historical separation that began with Erasmus and the Renaissance, where “hard” was divorced from the “soft” sciences and arts — a division that is still visible both geographically and intellectually on university campuses, as well as amongst scholarly disciplines themselves. But some see the reciprocal and perhaps limitless possibilities of emergent technologies and humanities scholarship – how digital technology cuts across disciplines, creates new ways of looking at artifacts, as well as producing new forms itself.
Lev Manovich, Professor of Visual Arts at UCSD, and Director of the Software Studies Initiative at California Institute of Telecommunications and Information Technology (Calit2), is well versed in the revolutionary possibilities that lie at the intersection of the arts, humanities, social science and digital technologies. Author of Info-Aesthetics (in progress), Soft Cinema: Navigating the Database (2005), Black Box-White Cube (2005), The Language of New Media (2001), over 90 articles published in 30 countries, and a prolific lecturer on digital culture, Manovich’s own professional evolution presents a narrative on breaking down disciplinary divides. Born in Moscow, he received his M.A. in Cognitive Science in 1988 from NYU, and his Ph.D. in Visual and Cultural Studies from the University of Rochester in 1993. In his most recent project, Manovich asks: How do we create quantitative measures of cultural innovation? Can we visualize cultural flows and how cultural trends change over time? Here, Manovich speaks to these (and other) questions:
What is meant by/do you mean by “Big Humanities”?
Manovich: “Big Humanities” (the term I coined in 2007) is one of the ways I use to characterize a new approach for the study of culture made possible by a convergence of a number of forces. Other terms that can be also used are “Cultural Datamining,” “Culture as Data,” or (my preferred term) “Cultural Analytics.”
Today sciences, business, governments and other agencies rely on computer-based analysis and visualization of large data sets and data flows. They employ statistical data analysis, data mining, information visualization, scientific visualization, visual analytics, and simulation. We believe that it is time that we start applying these techniques to cultural data. The large data sets are already here, the result of the digitization efforts by museums, libraries, and companies over the last ten years (think of book scanning by Google and Amazon) and the explosive growth of newly available cultural content on the Web. (For instance, as of February 2008, Flickr had 1.2 billion images, together with tags created by users and other metadata automatically logged by Flickr servers.)
The envisioned highly-detailed interactive visualizations of cultural flows, patterns, and relationships will be based on the analysis of sets of data comparable in size to the largest data sets used in sciences. The data sets will come from a number of sources. The first source is media content — games / visual design / music / videos / photos / art / photos of architecture, space design / blogs / Web pages, etc. In visualizing this content, we should use not only already existing metadata (such as image tags created by the users) but also new metadata that we will generate by analyzing the media content (for instance, using computer vision techniques to detect various image features). The second source is digital traces left when people discuss, create, publish, consume, share, edit, and remix these media. The third source is various Web sites that provide statistics about cultural preferences, popularity, and cultural consumption in different areas. Yet another source is what we can call “meta channels” — blogs which track the most interesting developments in various cultural areas.
My idea of cultural analytics is related to the NEH Digital Humanities Initiative recently announced “Humanities High-Performance Computing” (HHPC) initiative, but there are some important differences. First, I am interested in analyzing and visualizing patterns not only in past culture (the traditional domain of humanities), but in contemporary cultural areas, which so far have been largely ignored by humanities — user-generated media, portfolios by design students from around the world, and recently emerged cultural fields such as motion graphics, Web design, and space design. Second, while people have already been using statistical analysis on texts, I plan to focus on visual media — art images, design, films, videos, computer games, Web sites. Third, building on the exciting work in visualization done today both by scientists and by artists and designers, I want to use this work as an interface for computational analysis.
In this respect, while existing cultural visualizations typically present a single graph and are hard-wired to the particular data they show, our goal is to construct an open cultural analytics research environment that will allow the user to work with different kinds of data and media all shown together: original cultural objects/conversations, cultural patterns over space and time, statistical results, etc. A user should be able to perform analysis of the data herself close to or in real time using visualization as a starting point (like in GIS). The data sets can be assembled beforehand, or harvested from the Web in real time. Ideally, such an environment will be general enough so a user would be able to connect new cultural databases and also to add new visualization/analysis modules.
How did you get involved in this area or research?
Manovich: When I was 18, I realized that my life would be driven by two passions: 1) making art (by this time I was already studying painting for six years); and 2) trying to understand how art and culture work, how we communicate visually, what are the patterns in works of art.
In the early 1980s I encountered the emerging field of computer graphics, and I was immediately drawn to it because I intuitively felt that it was relevant to both of my goals. On the one hand, I wanted to create films, virtual worlds, and images, which would have the level of detail and complexity, which would be hard to achieve by hand. On the other hand, the fact that computers represent images as a matrix of numbers holds the promise that it would be somehow possible to analyze the patterns in visual art algorithmically.
Between 1986 and 1988 I was a Ph.D. student in experimental psychology, and during that time I learned computer vision and I started to play with trying to analyze images. However, when I entered a Ph.D. program in Visual Studies at the University of Rochester in 1989, I quickly realized that I should hide my interests in anything that smelled of science since it would seriously clash with the prevailing paradigms in humanities. So I put my interests on hold and instead focused on thinking and writing about new media.
Today the situation is different. The humanities are finally beginning to be interested in science and digital media. The growing popularity of the term “digital humanities” is one example of this. So in 2005 I realized that I can finally go back and start systematically working on what I wanted to do in the first place: use computers to analyze the patterns in works of art and other cultural objects.
The key difference between my thinking in 1986 and in 2008 is the scale. Given the speed of computers in the middle of the 1980s available to me, at that time I could only imagine analyzing a few images. Today it is feasible to computationally analyze all the images contained in all the museums around the world, all feature films ever made, and all the billions of photographs uploaded on Flickr. Therefore, instead of looking at patterns within a single image we can look at patterns and statistics across very large sets.
Another difference is that today we have a well-developed field of interactive visualization, including lots of exciting work done by artists and designers. (For examples of this work, visit www.infosthetics.com/ or www.visualcomplexity.com.) Thus, rather than only analyzing cultural objects computationally and then looking at the numbers or simple statistical graphs, we can visualize the results in a variety of interesting ways, and play with the visualizations in real time. I would like to see interactive visualization tools become commonplace in humanities.
If slides made possible art history, and if the movie projector and video recorder enabled film studies, what new cultural disciplines may emerge out of the use of visualization and data analysis? What we need is to have as many people as possible start using these tools — and then we will see what will emerge.
What is your vision with regards to links between your work and supercomputing?
Manovich: As I already mentioned, people in humanities usually deal with the past culture as opposed to the present. However, while we certainly can find large data sets in the past — for instance, 800,000 art images available in digital format at Artstor – only in contemporary culture do we find really big data sets that truly justify the use of supercomputers. I am talking, of course, about the phenomenon of user-generated content (or “social media”).
The numbers of people participating in social networks, sharing media, and creating user-generated content are astonishing, at least from the perspective of early 2008. (In 2012 or 2018 they may seem trivial in comparison to what will be happening then.) MySpace, for example, claims 300 million users. Cyworld, a Korean site similar to MySpace, claims 90 percent of South Koreans in their 20s and 25 percent of that country’s total population (as of 2006) use it. Hi5, a leading social media site in Central America has 100 million users and Facebook, 14 million photo uploads daily. The number of new videos uploaded to YouTube every twenty-four hours (as of July 2006): 65,000.(1)
If these numbers seem amazing, consider a relatively new platform for media production and consumption: the mobile phone. In early 2007, 2.2 billion people had cell phones; by the end of 2008 this number is expected to be 3 billion. Obviously, people in an Indian village sharing one mobile phone are probably not making video blogs for global consumption. But this is today. Think of the following trend: Flickr, founded in 2004, had already 2 billion images by November 2007, with a few million images being uploaded daily. The number of cultural objects created by the people in the past and preserved in museums, libraries and archives is fixed. We can’t make it any bigger. Once the idea of using supercomputers to analyze this data becomes popular, soon all this past data will be analyzed. In fact, given the size of this data and the continuously growing computer speed, we can also expect that rather soon a researcher will be able to process all of human cultural heritage (more exactly, the part of it available in digital form) on her laptop or phone — without any supercomputers.
However, given the current trends, we can expect that user-generated media — Web sites, blogs, user-generated photos, videos, maps, and other types of media — will continue to expand at a rapid pace. Similarly, as the numbers of cultural professionals and students in the world keep increasing, professionally produced content will also keep growing. The following are just some of the Web portals, which collect work from around the world: xplsv.tv – motion graphics and animation; Coroflot — over 90,000 design portfolios; Archinect — projects by architecture students; Infosthetics — information visualization projects. Therefore I feel that it is contemporary culture– including works created by both professional and non-professionals — that will keep supercomputers busy in years to come.
Finally, I should add that, in my view, the phenomenon of “social media” means not only the media objects created by normal people and pro-ams, but also conversations between people around these objects. People discuss each other’s photos on Flickr, leave comments on YouTube, write movie reviews, and so on. The size of this “conversation data” also continues to grow. It is important for two reasons. On the one hand, for the first time in history we can empirically study the reception of culture by looking at opinions, comments, and ideas of lots and lots of people. And on the other hand, this already enormous conversation data provides another reason for use of supercomputers for cultural analysis.
How do you think your work will broaden/challenge/alter our understandings of Humanities, Arts, and Social Science Research or Education and what does your work offer the humanistic/scientific/technological/corporate world?
Manovich: In the present decade our ability to capture, store and analyze data is increasing exponentially, and this growth has already affected many areas of science, media industries, and the patterns of cultural consumption. Think, for instance, of how “search” has become the interface to global culture, while at the same time recommendation systems have emerged to help consumers navigate the ever-increasing range of products.
I feel that the ground has been set to start thinking of culture as data (including media content and people’s creative and social activities around this content) that can be mined and visualized. In other words, if data analysis, data mining, and visualization have been adopted by scientists, businesses, and government agencies as a new way to generate knowledge, let us apply the same approach to understanding culture.
Imagine a real-time traffic display (like in car navigation systems), except that the display is wall-size, the resolution is thousands of times greater, and the traffic shown is not cars on highways but real-time cultural flows around the world. Imagine the same wall-sized display divided into multiple frames, each showing different data about cultural, social, and economic news and trends — thus providing a situational awareness for cultural analysts. Imagine a wall-sized computer graphic showing the long tail of cultural production that allows you to zoom to see each individual product together with rich data about it (à la real estate maps on Zillow) while the graph is constantly updated in real-time by pulling data from the Web. These are the kinds of projects I want to create.
I hope that the cultural analytics approach can encourage people to think about contemporary cultural developments on a global scale — setting up more challenging questions than they are used to. For example, given that the U.S. government has recently focused on creating a better set of metrics for innovation initiatives, can we create quantitative measures of cultural innovation around the world (using analysis and visualization of cultural data)? Can we track and visualize the flow of cultural ideas, images and influences between countries in the last decade — thus providing the first ever data-driven detailed map of how cultural globalization actually works? If we feel that the availability of information on the Web makes ideas, forms, images and other cultural “atoms” travel faster than before, can we track this quantitatively, visualizing how the development of the Web speeded up cultural communications over the last decade?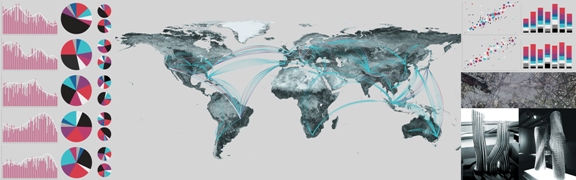
I think that there are many other applications for cultural analytics work besides humanities and social scientists. I am thinking, for instance, of artists and other cultural producers, critics, museums, digital heritage projects, and education. In fact, I believe that everybody involved in culture today — from the individual members of a global “cultural class” to governments around the world, which are competing in knowledge production and innovation — would be potentially interested in what we want to do — measures of cultural innovation, detailed pictures of global cultural changes, real-time views of global cultural consumption, remix, publishing and sharing.
Cultural analytics can provide a new application area for research in large-scale visualization, HCI, data storage, data analysis, and petascale computing as outlined in the NSF’s “Cyberinfrastructure Vision” (2007).
The emphasis of interactive visualization connects cultural analytics with the recent paradigm of visual analytics. I believe that the vision of visual analytics – combining data analysis and data visualization to enable “discovery of the unexpected within massive, dynamically changing information spaces” — is perfectly applicable to cultural data sets.
Finally, since the Software Studies Initiative that I direct is situated inside Calit2, we are able to take advantage of all of the cutting edge research in computer graphics, visualization, and grid computing going on there. Specifically, using the grant we recently received from UCSD, we have started to build a software system that we call a cultural analytics research environment. It will eventually run on the innovative displays currently built at Calit2 VIS Lab and IVL. This will allow us to present different kinds of information next to each other in a way that has not been done before.
One of these systems, completed in 2008 at Falko Kuester’s lab at the UCSD division of Calit2, currently has the world record as the world’s largest resolution display — a wall made from 70 30-inch monitors resulting in a combined resolution of 287 megapixels.This display wall (called HIperSpace) is driven by a number of PCs with state-of-the-art graphics cards. Therefore, the result is not simply in a large passive monitor but rather in a very large “visual computer” which can calculate and display at the same time. (This visual supercomputer can be scaled up to thousands of megapixels and more processors. Its development has been funded by NSF and NIH.) HIperSpace is the reason why I am able to think of being able to map and analyze global cultural patterns in detail. I would not ever think about it if I just worked on my laptop screen.
At the same time, I think that high-performance humanities computing in general, and cultural analyics in particular, is not only about humanists using science research. I believe that cultural analytics can provide new application areas for computer science research in a number of areas such as visualization, computer graphics, HCI, databases, etc. For instance, our team at Calit2, which includes researchers from communication, cognitive science, and computer science, wants to develop new interfaces for such large displays that would be appropriate for interactively working with “cultural data.” We also need to figure out appropriate visualization approaches, the ways in which processing of data and its visualization should be integrated, etc.
(1) For statistics on social networking sites, see for example: Patricia Sellers, “Myspace Cowboys.” Fortune. (29 August 2006.) 26 July 2008; “Facebook Added its 30th Million Subscriber Yesterday.” PPI. (11 July 2007). 26 July 2008; Jackson West, “Will Cyworld Stop Myspace Juggernaut?” GigaOm. (16 April 2006.) 26 July 2008; “YouTube serves up 100 million videos a day online.” USA Today. (17 July 2006). 26 July 2008.
About the Authors
Kevin D. Franklin is the Executive Director of the Institute for Computing in Humanities, Arts and Social Science (ICHASS) and Senior Research Scientist at the National Center for Supercomputing Applications (NCSA). Karen Rodriguez’G is Public Relations Liaison for ICHASS and a doctoral candidate in the Department of History at the University of Illinois at Urbana-Champaign (UIUC). Founded in 2004 at UIUC, ICHASS charts new ground in high-performance computing and the humanities, arts, and social sciences by creating both learning environments and spaces for digital discovery. ICHASS presents path-breaking research, computational resources, collaborative tools, and educational programming to showcase the future of the humanities, arts, and social sciences by engaging visionary scholars from across the globe to demonstrate approaches that interface advanced interdisciplinary research with high-performance computing.

























































