 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetPart 1: All that Parallelism
There are at least two ways exascale computing can go, as exemplified by the top two systems on the latest (November 2010) TOP500 list (Tianhe-1A and Jaguar). The Chinese Tianhe-1A uses 14,000 Intel multicore processors with 7,000 NVIDIA Fermi GPUs as compute accelerators, whereas the American Jaguar Cray XT-5 uses 35,000 AMD 6-core processors. Four of the top ten supercomputers in the TOP500 list use accelerators (NVIDIA GPUs or IBM PowerXCell in Roadrunner). However, only one of the five announced 10-petaflop+ systems uses accelerators. The IBM Blue Waters at Illinois will have 40,000 8-core Power7 processors; the Fujitsu Kei will have 80,000 8-core Sparc64 processors; IBM will deliver two Blue Gene/Q systems, Mira to Argonne National Lab with 49,000 16-core Power A2 processors, and Sequoia to Lawrence Livermore National Lab with twice as many as Mira. Only Cray’s Titan system at Oak Ridge is using GPUs as accelerators (to be fair, Titan is not fully approved just yet). Many would say that we will need accelerators to reach exascale, but I think those same people would have said we need accelerators to reach or exceed the 10-petaflop scale as well. We should watch these announcements over the coming year. When I first started this article, there were only four such announced systems, and I’m predicting two or more 10-petaflop+ systems before the year is out. If we can jump from 2-petaflop (2009) to 20-petaflop (2012) in three years, perhaps exascale computing by 2018 is achievable.
So we might have to deal with accelerators in some form, or not, but that’s not the subject of this series of articles. All the systems in the TOP500 use thousands, tens of thousands, or at the high end, hundreds of thousands of cores. Moreover, the cores themselves exhibit a high degree of internal parallelism. At exascale, there will be a lot of parallelism, on many levels, and to reach really high performance, we are going to have to program and tune to take advantage of all those levels of parallelism. And that is the subject of these articles.
Levels of Parallelism
I break down the parallelism that we see in really high end computing into six levels. We tend to focus on the node-level or core-level parallelism, since that’s where the biggest numbers come from, but it’s the product of all the parallelism that gives us the total performance, so we need to understand all the levels. You may split the levels differently, and that would make for an interesting academic discussion in itself.
- Node Level: How many nodes in the computer. I’ll mostly use the Jaguar numbers as an example; Jaguar has 18,000 nodes. We could debate what constitutes a node, but I’ll use the common definition that a node is a set of processors or cores that share physical memory and a network interface. All (or almost all) large systems use identical nodes, except for a small number dedicated to IO, storage, or interactive interfacing, so we haven’t had to deal with heterogeneity across nodes, and I expect this to continue. I’m going to go out on a limb by predicting that node count will top out at exascale closer to 100,000, rather than the more aggressive predictions of millions of nodes from other experts.
- Socket Level: How many sockets at each node. Jaguar nodes have two sockets. Systems with accelerators exhibit heterogeneity at this level, with CPU and accelerator sockets. Current systems using GPUs as accelerators have the GPUs plugged into the IO bus (PCI-express) instead of a CPU socket, which seriously affects the bandwidth between the CPU and accelerator. An accelerator like the Convey coprocessor sits on the memory bus, just like another processor, and can be much more tightly integrated. I’m going to ignore other accelerators, such as network interfaces with MPI acceleration capabilities. They can be just as important, but are generally not programmed. We can expect socket parallelism to go up in each node, from 2 or 4 now to 8 or 16 sockets. As mentioned in the introduction, these may include compute accelerators.
- Core Level: How many cores in each socket. Jaguar uses 6-core AMD processors. Core counting is open to debate. Does an Intel Core i7 hyperthreaded six-core processor count as twelve? The operating system certainly thinks there are twelve, and there can be twelve simultaneous active threads, but there are only six sets of functional units. Does each AMD Bulldozer “2-core module” count as two cores, or are they more like a single dual-issue core? Like the hyperthreaded core, the two “cores” on the 2-core module share many resources, such as the instruction fetch and decode logic, and the floating point functional units, yet there are two complete sets of integer functional units. Does each NVIDIA GPU thread processor (CUDA core) count as a core, or only the multiprocessors?) One could argue that if we count each CUDA core as one core, then each lane of an SSE instruction unit should count as one, making that six-core, hyperthreaded Intel Core i7 equivalent to 48 SSE-cores (single precision). With the new AMD Fusion and Intel Sandy Bridge processors, we see heterogeneity at the core level as well, with 64-bit x86 cores and integrated graphics cores on-chip. We should expect core parallelism to increase due to improved silicon densities, but we’re still waiting for through-silicon vias (TSVs) to give enough off-chip bandwidth to feed the beast.
- Vector Level: How wide are the vector or SIMD instructions in each core. Focusing on 64-bit precision, Jaguar uses X86 SSE with 2-wide vectors. If we count an NVIDIA streaming multiprocessor as a single core, then each core has 8-wide (Tesla-10) or 16-wide (Fermi) vector width in hardware, with software vector lengths of 32. We can argue over whether to count hardware SIMD parallelism or software vector length, but recall that the Cray-1 used pipelining, not SIMD parallelism, to implement its 64-long vector instruction set. Intel has taken the next shot (or two) along the vector level on x86 with AVX (and the Larrabee vector instructions), increasing SIMD widths from 2 to 4 (and 8) in double precision. Lengthening the vectors is a tradeoff, whether to use those gates for longer vectors or for more cores. Increasing SIMD or vector parallelism is easy and low cost relative to adding cores, comparing performance per gate, and I expect this trend to continue. For accelerators, such as GPUs, we can expect very long vector operations. These devices are already optimized for regular parallelism, and there’s no reason to believe that won’t continue to be the case.
- Pipeline Level: How many instructions are in a partial state of completion at once. This is hard to measure. If we treat multithreading as a type of pipeline parallelism implemented across threads, NVIDIA Fermi GPUs can support pipeline parallelism factors of close to 50. With multiscalar instruction issue, out-of-order instruction execution, and aggressive speculative execution, any modern high powered processor can have dozens of instructions in some partial state of completion. However, look at the CPU design that Intel used in the Knight’s Ferry vs. the current Intel Core processors. The Knight’s Ferry packs more cores on a single chip by simplifying the core to a dual-issue, in-order control unit. This is another interesting parallelism-level tradeoff, reducing the control unit (pipeline-level parallelism) to increase core count (core-level parallelism). I expect the pipeline-level parallelism for CPUs to decrease, in order to increase core count. GPUs, on the other hand, are already single-issue in-order cores but use a high degree of multithreading to tolerate memory latency, rather than depend on a cache and memory reference locality; expect this design point to continue. For these chips, I expect pipeline-level parallelism to increase, as memory latencies get relatively larger.
- Instruction Level: How many instructions get dispatched or executed at one time. Typical x86 processors can issue up to three instructions per cycle. I expect this number may decrease to two, again to simplify the control unit and pack more cores on a chip. Some processors, such as Intel Itanium and AMD GPUs, use a VLIW design for static instruction-level parallelism, trading a simpler control unit for a more complex software stack (compiler). VLIW advocates believe that this truly is the best way to implement instruction-level parallelism, considering all complexity, power and performance tradeoffs. It will be hard for the HPC world to sustain the costs of processor design, so we’re likely to have to live with whatever the commodity world delivers.
So lots of levels of parallelism, and lots of complexity. You might count the levels differently, such as combining the socket and core levels, since cores in different sockets differ mostly only in relative latency. You might insert an explicit level for heterogeneity, or you might combine the pipeline and instruction levels as a single microarchitectural level. But I’m going to live with the levels as given, and the table below summarizes the numbers: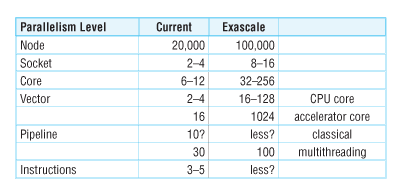
Application Parallelism
Application programming is mostly focused on the higher levels of parallelism, the top four levels of my chart. Large scale parallel programming today is largely dominated by the Single Program-Multiple Data (SPMD) model across distributed memory, using MPI for communication. You can use SPMD (MPI-style) parallelism and map that across nodes, sockets and cores, which has the advantage of a single parallelism model across many levels of parallelism. You can then map your application parallelism seamlessly to a machine with many nodes and low core count, or with fewer nodes and higher core count, but you can’t take advantage of the locality inherent between cores on a single socket or node.
Some applications use OpenMP within a node or socket and MPI across nodes or sockets, to take advantage of lower data communication cost in shared memory. OpenMP doesn’t manage parallelism across a network, but has most of the features you need for shared-memory parallelism, and is even looking to add features to tune for non-uniform memory access costs. Unfortunately, these two programming models, each around 15 years old now, were and are designed by separate committees that seemingly have no mutual interest in interoperability. This is not too hard to understand, given that OpenMP is a language model, whereas MPI is an opaque library (opaque to the language and compiler). Having to deal with two different models is unfortunate, but each deals only with a subset of the total problem.
Finally, many applications are programmed to take advantage of vector instructions, in the form of vectorizable loops. The vectorization technology that served as my personal introduction to advanced compilers (about 35 years ago) is still used today for those SIMD instructions. Moreover, this will be more important in the future. As hardware vector lengths increase, a larger fraction of the total performance will come from vectors. The downside is that there’s no single way to program a parallel operation that can be mapped across vector parallelism, shared memory core or socket parallelism, or node-level parallelism, with the choice made at program compile or execution time.
Compilers, on the other hand, mostly focus on the lower levels of parallelism, particularly instruction-level and pipeline parallelism. One could say that the microarchitectural parallelism is implemented in hardware, not in the compiler, but the compiler has to express the parallelism with the right instruction stream for the hardware to exploit it. Compilers also generate vector instructions, as mentioned above. Automatic parallelization as well as efficient implementation of shared-memory programming models like OpenMP and Cilk require integration into the compiler as well.
The interface between the application and the compiler is the programming language. The bandwidth of that interface is the amount of information that a programmer can give to the compiler. Recent linguistic research implies that the language we use to communicate changes or focuses the way we think; this is true for programming languages as well. Parallelism at the language level is becoming more common. Some languages focus on different levels of parallelism.
OpenMP, as mentioned, is used in shared memory environments, across cores or sockets, and continues to evolve, adding features for unstructured (task) parallelism. Cilk and many other parallel languages also target shared memory parallel systems. These languages usually assume uniform memory access cost, but allow for load balancing and dynamic parallelism. They focus entirely on core- and socket-level parallelism, with uniform (homogeneous) cores. The next C++ standard will likely include some sort of parallel construct, probably assuming shared memory as well. Fortran 2008 has a parallel loop construct, the do concurrent, which allows a compiler to execute the iterations in any order, including in parallel. This is a bit different than a parallel loop expressed in OpenMP, which specifies the mapping between loop iterations and threads more explicitly, and different than array assignments and the forall construct, which allow vector-style parallelism, but not necessarily multicore-style parallelism.
MPI is used mostly to manage parallelism across nodes. Coarrays in Fortran, Unified Parallel C (UPC) and other PGAS languages all target the same parallelism structures as MPI. Programming using these primitives leads one to large scale, static parallelism with explicit locality and infrequent communication. As mentioned, it’s difficult to take advantage of locality between cores on a single socket or node with these.
OpenMP, Cilk, coarrays, UPC, and others are implemented and supported by compilers, but require the application programmer to expose the parallelism and express it using specific syntax. MPI is not a language, but it may as well be. It requires the same application structure as a PGAS program, without the advantage of compiler error checking or optimization.
OpenCL and (to some extent) CUDA target the middle parallelism levels. They can be used to program sockets or cores on a socket. OpenCL could even be used to program sockets or cores on different nodes, but it wouldn’t scale. You’d need some other mechanism to generate symmetric parallelism across the nodes. They are designed for a master (host) / worker (accelerator) execution model.
Then there are myriads of low-level programming tricks to foil or cause the compiler to generate the right code to take advantage of the instruction-level and pipeline-level parallelism, such as manual loop unrolling, which you still see being used today. These are mostly artifacts of compilers that are not fully optimized, or of cases where the programmer knows more about the program, the data, or the target machine than he or she can express in the language.
To reach exascale computing, we need to productively take advantage of all the levels of parallelism. This has ramifications for applications, languages, and compilers. In my next column, I’ll introduce The Three Ex’s of Exascale, which applications developers and system providers need to consider as we move forward.
About the Author
Michael Wolfe has developed compilers for over 30 years in both academia and industry, and is now a senior compiler engineer at The Portland Group, Inc. (www.pgroup.com), a wholly-owned subsidiary of STMicroelectronics, Inc. The opinions stated here are those of the author, and do not represent opinions of The Portland Group, Inc. or STMicroelectronics, Inc.
























































