 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetIt’s difficult to ignore the momentum of conversations about data-intensive computing and it’s bleed-over into high performance computing, especially as we look toward November’s SC11 event, which puts the emphasis squarely on big data driven problems.
A number of traditional HPC players, including SGI, Cray and others, are making a push to associate some of their key systems with the specific needs of data-intensive computing. Following a conversation this week with Convey Computer’s Director of Marketing, Bob Masson, and Kevin Wadleigh, the company’s resident math libraries wizard, it was clear that Convey plans to be all over the big data map—and that this trend will continue to demand new architectures that pull the zing of FLOPS in favor of more efficient compute and memory architectures.
The duo from Convey talked at length about the inflection point that is happening in HPC. According to Masson, this shift in emphasis to data-intensive computing won’t ever replace the need for numerically-intensive computing, but opens a new realm within HPC—one that is timed perfectly with the steady influx of data from an unprecedented number of sources.
A recent whitepaper (that prompted our chat with Convey) noted that HPC is “no longer just numerically intensive, it’s now data-intensive—with more and different demands on HPC system architectures.” Convey claims that the “whole new HPC” that is gathered under the banner of data-intensive computing possesses a number of unique characteristics. These features include data sizes in the multi-petabyte and beyond range, high ratio of memory accesses to computing, extremely parallelizable read access/computing, highly dynamic data that can often be processed in real time.
Wadleigh put this move in historical context, pointing to the rapid changes in the 1980s as the industry cycled through a number of architectures meant to maximize floating point performance. While it eventually picked its champion, this process took many years—one could even argue decades—before the most efficient and best performing architecture emerged.
He says this same process is happening, hence the idea of the “inflection point” in high performance computing. While again, the power of the FLOP will not be diminished, when it comes to efficient systems that are optimized for the growing number of graph algorithms deployed to tackle big data problems, massive changes in how we think about architecture will naturally evolve. Of course, if you ask Bob or Kevin—that evolution is rooted in some of the unique FPGA coprocessor and memory subsystem designs their company is offering via their so-called Hybrid Core Architecture.
While these are all traits that are collected under the “big data” or “data intensive” computing category, another feature—the prevalence of graph algorithms—is of great importance. Problems packing large sets of structured and unstructured data elements are becoming more common in research and enterprise, a fact that warranted a new set of benchmarks to measure graph algorithm performance.
As the preeminent benchmark for data-intensive computing, the Graph 500, measures system performance on graph problems using a standardized measure for determining the speed it takes the system to transverse the graph. While this could be a short book on its own, suffice to say, the Graph 500 website has plenty of details about the benchmark algorithm—and details about the top performing systems as announced at ISC this past summer. Convey feels confident about its position on the list (after not placing in the top ten for the last list in June) and notes that this year’s Graph 500 champions (TBA at SC11) will either have spent a boatload of money on sheer cores and memory—or will have come up with more efficient approaches to solve efficiency and performance challenges of these types of problems.
Convey claims that when it comes to architectures needed to support this type of computing, standard x86 “pizza box” systems falls way short in terms of a lack of inherent parallelism, memory architecture that is poorly mapped to the type of memory accesses, and a lack of synchronization primitives.
They say that with systems like their Hybrid Core Architecture line, some of these problems are solved, bringing a range of features those with data-intensive computing needs have been asking for. Among the “most desirable” architectural features of this newer class of systems is the need to de-emphasize the FLOPS and concentrate on maximizing memory subsystem performance. Accordingly, they stress their FPGA coprocessor approach to these needs, stating that such systems can be changed on the fly to meet the needs of the application’s compute requirements.
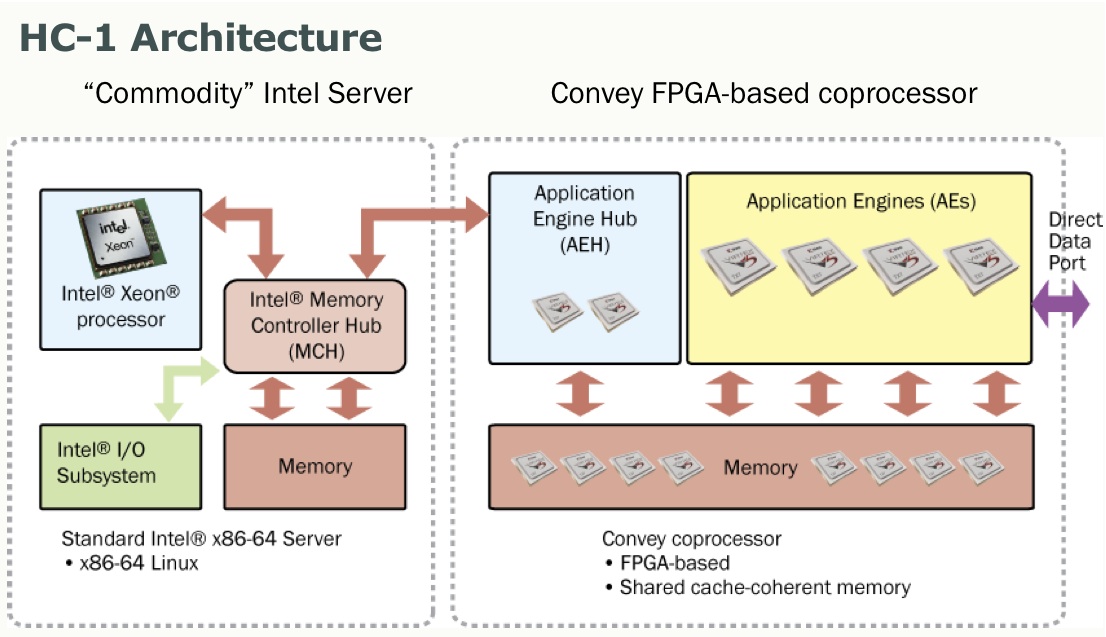
Convey’s high-bandwidth memory subsystem is key to refining the performance and efficiency of graph problems. Their approach to designing a memory system, for instance, that only spits back what was asked for and optimizing aggregate bandwidth, are further solutions. However, even with these features, users need to be able to support thousands of concurrent outstanding requests, thus providing top-tier multi-threading capabilities is critical.
The question is, if HPC as a floating point-driven industry isn’t serving the architectural needs of the data-intensive computing user, what needs to change? According to Wadleigh, who spent his career engaged with math libraries, the differentiator between Convey (and commodity systems, for that matter) is the two-pronged approach of having large memory and a unique memory subsystem. Such a subsystem would be ideal for the kinds of “scatter gather” operations that are in high demand from graph problems.
Wadleigh said that “most memory system today have their best performance when accessing memory sequentially because memory systems bring in a cache line worth of data with 8 64-bit points. Now, as long as you’re using that, it’s great—but if you look at a lot of these graph problems, half of the accesses are to random data scattered around memory, which is very bad when you’re thinking about this for traditional architectures.” He claims that standard x86 systems, at least for these problems, have bad cache locality, bad virtual memory pagetable locality, and these are also bad patterns for distributed memory parallelism.
One other element that Convey stresses is that data-intensive computing systems, at least in terms of their own line, need to have hardware-based synchronization primitives. With the massive parallelism involved, synchronization in read and writes to memory has to be refined. They state that “when the synchronization mechanism is ‘further away’ from the operation, more time is spent waiting for the synchronization with a corresponding reduction in efficiency of parallelization.” In plain English, maintaining this synchronization at the hardware level within the memory subsystem can yield better performance.
With the focus on data-intensive computing at the heart of SC11 and companies with rich histories in HPC, including Convey jockeying for positions across both the Top500 and the Graph 500, it’s not hard to see why the Convey team thinks of this time as an inflection point in high performance computing, and why they think their Hybrid Core architecture is positioned to take advantage of this.

























































