 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetToday’s commodity servers, as well as systems designed specifically for numerically intensive algorithms (“supercomputers”), are ill suited for many applications in the world of big data analytics. Such applications often use graph manipulation algorithms and data structures, and are best addressed by architectural extensions not found in commodity systems. Convey Computer Corporation’s hybrid-core system takes a heterogeneous approach to solving graph-type problems, and the resulting performance is characterized by results on the Graph500 Benchmark (www.graph500.org). Let’s take a look at architectural features that accelerate graph problems, and how Convey has implemented these features in its reconfigurable computing system.
Big Data Analytics and Graph Algorithms
Many analytics applications utilize graph algorithms and data structures to allow discovery of relationships between data elements in a large database. Generally, modeling these relationships in software and hardware is “reasonably” easy. (Let’s say the core graph manipulation algorithms are fairly easy, the implementation as it pertains to a several petabyte database may not be so easy!) Data structures can be constructed that contain information about specific nodes in a graph, connections and relationships to other nodes, and so on.
Certainly graph problems aren’t new. However, using graph algorithms to traverse graphs that have billions of nodes and edges and require many terabytes of storage is new (and “different”). And computer architectures that effectively execute these algorithms are also new; as the National Science Foundation states: “Data intensive computing demands a fundamentally different set of principles than mainstream computing.” [1]
Desirable architectural features
What types of architectural features are desirable in a computer system that executes graph algorithms? Following are some of the features that can give the most performance for the least cost/space/power:
Balance between compute elements and memory subsystem performance. Most data-intensive problems require minimal compute resources (especially in terms of floating operations), and require more memory subsystem performance. Ideally, as in a reconfigurable or hybrid-core computing system, the compute elements can be changed on the fly to adapt to the application’s compute needs.
High bandwidth, highly parallel memory subsystem. Attainable memory bandwidth (not peak) should be as high as possible. In addition, many thousands of simultaneous outstanding requests should be supported to support parallelism and mitigate latency.
Massive multi-threaded capability. A combination of compute and memory requirements, the ability to support tens or hundreds of thousands of concurrent execution threads is desirable. More parallelism reduces time-to-answer, improves hardware utilization, and increases efficiency.
Hardware-based synchronization primitives. With high degrees of parallelism comes the challenge of synchronizing read/write access to memory locations. Data integrity demands that a read-modify-write operation to a memory location is an indivisible operation. When the synchronization mechanism is “further away” from the operation, more time is spent waiting for the synchronization, with a corresponding reduction in efficiency of parallelization. Ideally, synchronization is implemented in hardware in the memory subsystem.
_______________________
[1] http://www.nsf.gov/funding/pgm_summ.jsp?pims_id=503324&org=IIS
The Graph 500 benchmark
Recognizing the need for a benchmark suite that will more accurately measure performance on graph-type problems, a steering committee of HPC experts from academia, industry, and national laboratories created the Graph500 benchmark. Currently the benchmark constructs an undirected graph and measures the performance of a kernel that executes a breadth-first search of graph.[2][3]
The kernel of the breadth-first search portion of the benchmark (Figure 2) contains multiple constructs that are common to many graph-type algorithms—specifically a high degree of parallelism, and indirect (or “vector of indices”) memory references.

Figure 2. The kernel of the breadth-first search algorithm extracted from the graph500 release code.
Hybrid-core computing and the Graph 500 benchmark
The Convey hybrid-core systems offer a balanced architecture: reconfigurable compute elements (via Field Programmable Gate Arrays—FPGAs), and a supercomputing-inspired memory subsystem (Figure 3).
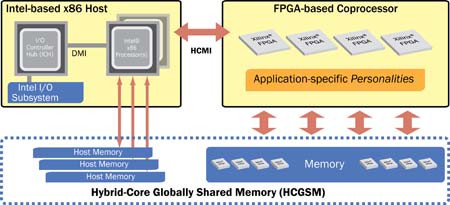
Figure 3. Overview of the Convey hybrid-core computing architecture.
_______________________
[2] http://www.graph500.org/index.html
[3] http://en.wikipedia.org/wiki/Breadth-first_search
The benefit of hybrid-core computing is that the compute-intensive kernel of the Graph500 breadth-first search is implemented in hardware on the FPGAs in the coprocessor. The FPGA implementation allows much more parallelism than a commodity system (the Convey memory subsystem allows up to 8,192 outstanding concurrent memory references). The increase in parallelism combined with the hardware implementation of the logic portions of the algorithm allow for increased overall performance with much less hardware.
In addition to increased parallelism, the memory subsystem of the Convey systems is specifically designed to provide high bandwidth for parallel references that exhibit poor locality (e.g. offers high performance for random accesses). Thus, the vector of indices portion of the code is highly accelerated over architectures that are not well suited for random accesses.
Performance results
The architecture of the Convey hybrid-core systems lends itself exceedingly well to the Graph500 benchmark (Figure 4). While the problem size is considered “small” (which is understandable, given that the benchmark is run on a single node system), the performance-per-watt and performance-per-dollar are well beyond any other system on the list.
Figure 4 is a partial list (problem scale 28-31) of the performance results for the November 2011 release of the Graph500 benchmark. Approximate power requirements allow for an arbitrary metric illustrating power efficiency (MTEPS/kw).
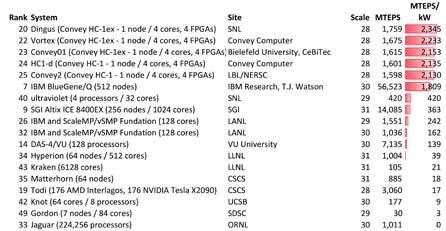
Figure 4. Performance and power on the Graph500 benchmark (for problem size 28-31).[4]
Conclusions
The massive explosion of data available for analysis and understanding is creating a “whole new dimension to HPC,” with demands on existing HPC architectures that cannot be fulfilled by current commodity systems. Future generations of HPC systems will be required to acknowledge some of the architectural requirements of data-intensive algorithms. For example, memory subsystems will need to increase effective bandwidth, more parallelism will be needed, and synchronization primitives will need to be “closer” to the memory subsystem.
By implementing a balanced, hybrid approach, Convey’s hybrid-core family of systems are able to execute problems in the data-intensive sciences much more effectively. The hybrid-core architecture is poised for exascale levels of computing in the data-intensive sciences because it offers reconfigurable compute elements balanced with a supercomputer-inspired memory subsystem.
[4] One entry was removed (#17) because it employed a different BFS algorithm.
For more information, please see http://www.conveycomputer.com/sc11/


























































