 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetPurveyor of cluster and cloud management software, Bright Computing announced that it is now shipping Bright Cluster Manager 6.0 with advanced cloud bursting capabilities. The overhauled cluster management solution was first announced at SC11, but while at the conference, the company realized there was one feature that they simply had to add, even if it meant holding back the release, and that feature is data-aware scheduling.
 Matthijs van Leeuwen, CEO of Bright Computing, explains this functionality was not easy to implement, but from talking to customers they understood the value-case was significant. Their decision was cemented during a conversation with Amazon that took place at SC11, when the preeminent cloud vendor told them that such a tool would be the “holy grail of cloud bursting.”
Matthijs van Leeuwen, CEO of Bright Computing, explains this functionality was not easy to implement, but from talking to customers they understood the value-case was significant. Their decision was cemented during a conversation with Amazon that took place at SC11, when the preeminent cloud vendor told them that such a tool would be the “holy grail of cloud bursting.”
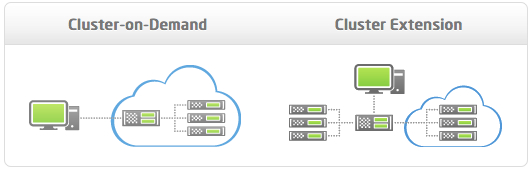
The cloud-ready Bright Cluster Manager, which we initially covered in November, supports two different cloud scenarios. The first, called Cluster On-Demand, allows the user to create a complete, stand-alone cluster inside the Amazon cloud. The second, known as Cluster Extension, is the cloud bursting route. It enables customers to add capacity to their existing on-premise cluster by expanding into the Amazon cloud. To the user, the disparate resources appear and are managed as a unified cluster, while Bright Cluster Manager offloads much of the complexity.
A key component of Bright’s cloud bursting solution is data-aware scheduling. The CEO explains that prior to this new feature, when the user wanted to submit a job to the cloud nodes, they would have to personally monitor all stages of the data transfer: getting the data to the cloud, submitting the job and waiting for it to move up the queue, then running it and waiting for the results, before manually transferring the data back to their workstation or local head node (and monitoring that process as well).
Suffice to say there was a lot of manual activity and monitoring around data transfer, and a lot of waiting and checking.
What Bright has made possible, according to van Leeuwen, is fully-automated and workload management-scheduled data transfers. Now when the user submits their compute job, they specify what data sets are to be transferred, and the location of the input and output files. From that point onwards, Bright Cluster Manager handles all of these requests. It grabs the data, starts transferring it, keeps track of the transfer, then follows the job’s progress up the queue, and ensures the job isn’t run until all the data is available. Once the job is finished, Bright Cluster Manager then transfers the results back to the specified folder.
As data sets get bigger, but still of suitable size for cloud bursting, data-aware scheduling saves time and headaches, notes van Leeuwen. “Let’s say you have a data set that takes several hours or a whole night to transfer; as a user, you don’t need to set an alarm to get up in the middle of the night to check if your data’s transferred so you can finally start your job. Bright takes care of that,” he says.
In the official announcement, Steve Conway, IDC Research Vice President for HPC at IDC, points out that data movement and data management are significant barriers to using HPC in the cloud.
“Cloud latency issues can make it challenging to ensure that the right data are in position when applications need to run on the cloud, and that the data are returned in a timely way afterward,” he states.
“Bright addresses this challenge by designing data aware scheduling directly into the company’s cloud bursting capability. This integrated approach could make it easier for mainstream HPC applications to exploit cloud computing.”
In addition to the data-aware scheduling component, there are a number of other enhancements to this release, including interconnect improvements; the addition of openlava, the open source version of LSF, to the pre-integrated suite of workload managers; and full support for CUDA 4.1. This release also allows customers to load Bright on top of their existing Linux installation, without disrupting their operations.
As a cloud bursting tool, Bright supports all Amazon Web Services instances equally well. The CEO pointed out that not all cloud management providers can make this claim. Amazon’s HPC instances, Cluster Compute and Cluster GPU, rely on Hardware Virtual Machine (HVM) based virtualization as opposed to para-virtualization techniques, and therefore are more difficult to work with. Bright takes care of the additional complexity, and the CEO advises potential users to make sure that the vendor they select supports the instance level they require.
Bright also helps users benefit from the cost-savings potential of Amazon’s Spot Instances, unused EC2 capacity that is sold at a reduced rate. As part of its data management functionality, Bright Cluster will monitor when the spot instances become available so the user no longer has to oversee the process.
Just like with Amazon, when it comes to using Bright Cluster in the cloud, you only pay for what you use. Pricing is by the hour. Says van Leeuwen: “Every Bright Cluster Manager that is shipped is cloud-bursting enabled and all you pay for is the hours that you use it. If you already have a Bright Cluster manager cluster of, say, 16 nodes and for that one important deadline in the year when you need 500 nodes in a week, you only pay for using it for that time.”
For on-site clusters, the company offers a perpetual license, which is good forever, or customers can buy a subscription, which can be renewed every year.
Bright also supports bursting to on-premise nodes, which means that users can make use of spare or idle nodes from within their own department or perhaps from a colleague’s department. “You can add them to your cluster, register them with our bursting server which keeps track of time used and then just pay for time used,” notes van Leeuwen.
While Bright is launching the cloud bursting capability with the Amazon EC2 environment, the underlying code was designed and written with the ability to add other public clouds, and the company is actively pursuing that goal. Bursting to private clouds is also on their radar. From a technology-standpoint, this should be relatively simple the CEO explains, especially if it is carried out with a private cloud solution that is compatible with the Amazon EC2 API, such as Eucalyptus, OpenStack, and CloudStack.
Bright is seeing a lot of interest for its cloud bursting capabilities coming from pharmaceutical companies, genomics outfits, and the oil and gas sector, which the CEO notes has significant data challenges. Although general availability starts today, the company already has some beta users and began shipping to select customers last week.


























































