 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetAt the HPC Advisory Council European Conference 2012 in Hamburg, in conjunction with the International Supercomputing Conference (ISC’12), Josh Simons, Office of the CTO, VMware, delivered a presentation (video/slides) that should be of particular interest to followers of the HPC cloud space. The session, titled “Achieving ultra-low latency in the Cloud: How low can we go?” tackled the million-dollar HPC cloud question: Are cloud computing and virtualization only useful for running throughput workloads or can latency-sensitive applications be run as well?
 In a blog post penned prior to the event, Simons writes, “This is the question we have been examining within the Office of the CTO at VMware. In this talk, I will present our early results using InfiniBand RDMA in a vSphere virtual environment and discuss the prospects for future performance improvements and functional enhancements.”
In a blog post penned prior to the event, Simons writes, “This is the question we have been examining within the Office of the CTO at VMware. In this talk, I will present our early results using InfiniBand RDMA in a vSphere virtual environment and discuss the prospects for future performance improvements and functional enhancements.”
Even though Simons works for a virtualization company, he does so as an HPC advocate. His 20-year industry background includes tenures at Sun Microsystems and Thinking Machines. Simons kicks off his talk by explaining that he is there “to present some preliminary data about what we can use cloud computing technology for – things other than throughput, embarrassingly-parallel applications, which at this point have been shown pretty definitively [to] run pretty well in a cloud environment.”
In traditional HPC, performance is god. Coding is done as close to the metal as possible, which is why cloud with all its abstractions was met, at first anyway, with some disdain by serious HPCers. At one extreme, you had big-iron, custom-built, painstakingly-tuned systems and on the other end, a volume-based generic computing utility – these were different religions. Still, it was apparent from the start that the embarrassingly-parallel applications (aka data-parallel workloads) were a good fit for cloud. And before cloud was called cloud, HPC was already moving away from big iron, toward commodity scale-out cluster architectures. I would venture to say that cloud is a natural extension of the scale-out cluster architecture, taking the imperative to scale-out a step further.
At any rate, abstracting complexity comes at a cost, and for cloud, it’s the network-dependent apps that get dinged. Which brings us back to the ultimate HPC cloud question: How can we move the needle from embarrassingly-parallel toward more communication-dependent apps? The answer, according to Simons, lies in enhanced interconnect and virtualization technologies, which are the kinds of projects that the VMware rep and his peers are working on.
In his talk, Simons compares the needs of general enterprise IT and HPC, pointing to a “convergence” between the camps, driven by increasingly shared concerns, such as:
- Scale-out management.
- Multi-tenancy and security.
- Low latency communication.
- High utilization.
- Power management.
- Dynamic workloads.
- Application parallelism and resiliency.
Because the enterprise IT space is so much larger than HPC (approximately $800 billion-a-year versus $25 billion-a-year), the fact that these are shared concerns is a “good thing” for the smaller player. As just one example of this symbiosis, the ubiquity of multicore processors in the enterprise space is driving the push toward application parallelism.
 According to the analyst group Forrester, the cloud market will be worth $241 billion by 2020 – but what type of cloud will this be? “It’s whatever the 800 lb gorilla wants it to be,” emphasizes Simons, referring to the mammoth $800 billion general IT space. “Enterprise IT is going to drive the requirements of what cloud looks like,” notes Simons, explaining further that this is what motivated him to join VMware: to help shape a cloud future that is HPC-friendly.
According to the analyst group Forrester, the cloud market will be worth $241 billion by 2020 – but what type of cloud will this be? “It’s whatever the 800 lb gorilla wants it to be,” emphasizes Simons, referring to the mammoth $800 billion general IT space. “Enterprise IT is going to drive the requirements of what cloud looks like,” notes Simons, explaining further that this is what motivated him to join VMware: to help shape a cloud future that is HPC-friendly.
Simons believes that “the bulk of the [HPC] market can ultimately be served by these sorts of [cloudy] technologies.”
“What you’ll see is mainstream cloud and virtualization technologies being more and more applicable starting at the bottom of the [HPC] market and moving up over time,” he contends.
While virtualization gets you into a cloud environment, it can benefit HPC in other ways as well, notes Simons, citing several use cases:
- Heterogenous environments – the ability to customize the environment with any software stack you want to run.
- Dynamic resource management – including live migration.
- Workload isolation – for secure multitenancy and failure protection.
- Dynamic fault tolerance – checkpointing.
- For current virtualization users – unification of IT infrastructure.
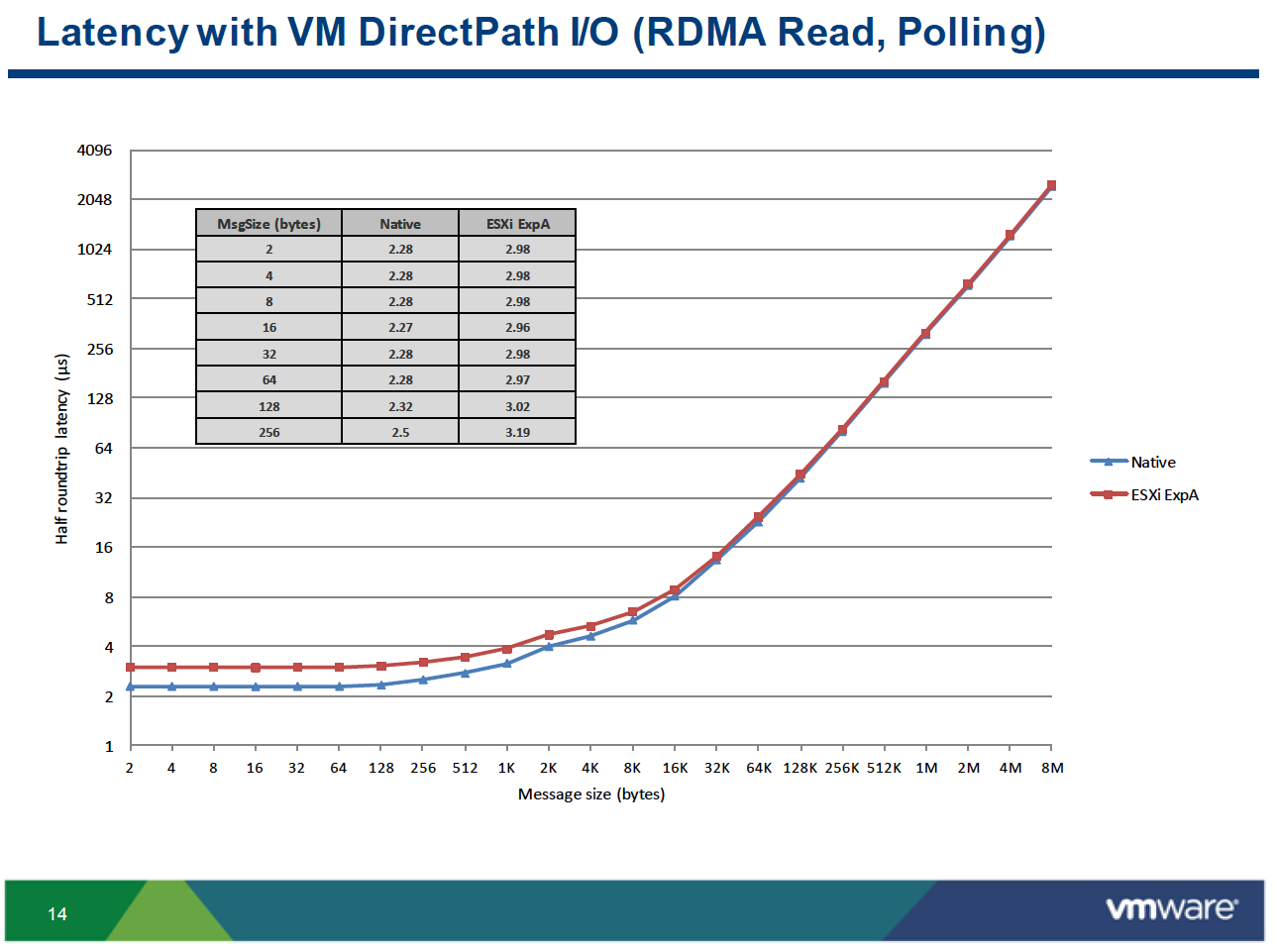
For the heart of his discussion, Simons details the preliminary results of a tech report that VMware published in April, called RDMA Performance in Virtual Machines using QDR InfiniBand VMware VSphere 5. This point-to-point test used two two-socket Westmere-class systems with Mellanox QDR InfiniBand adapters, running Red Hat 6.1 with OFED 1.5.3. Results labeled as “ESXi” used vSphere 5.0, while results labeled as “ESXi ExpA” and “ESXi ExpB” included unreleased patches that will be included in a future vSphere release.
In the paper, the authors write that the remote direct memory access (RDMA) performance experiments “demonstrate that latencies under 2μs and bandwidths of 26Gb/s can be achieved using guest-level RDMA with passthrough mode on VMware’s ESXi hypervisor.”
Simons explains that using an RDMA software stack and an RDMA-capable piece of hardware allows users to step around the kernel on the data-pass, enabling very low latencies. The experiment compares an actual bare metal setup with a virtualized setup that uses a direct analog of the kernal bypass (represented in the figure below by the RDMA box on the right-hand side of the right-hand image).

Click to enlarge.
Looking at InfiniBand bandwidth with VM DirectPath I/O, there were no showstoppers. The results were deemed good, which was expected. The experimenters were much more interested in latency results. They looked at latency with VM DirectPath I/O with RDMA read using polling for completions (see chart below). The blue line (the bottom line) is native: 2.28 microseconds. The red line, above that, is virtual: 2.98 microseconds. This 0.7 overhead is not bad from an absolute perspective, notes Simons, but from a relative percentage perspective, “it’s pretty bad,” he says, adding that of course it always depends on the application. The send/receive test had an overhead of about .4 microseconds, a bit better.
Click to enlarge.
Simons relates that they are pleased with these results as a starting point, and they are confident they can improve on them over time.
“We can look at mircro-benchmarks all day, but what really matters is how this performs on real benchmarks,” he says. To that end, Simons reminds us to take a look at the HPC Advisory Council website, which includes “a whole bunch of really useful use cases and analyses that were done looking at different HPC ISV applications and [provide] a detailed analysis of what their messaging requirements are, what their interconnect requirements are, etc.”
At the end of his talk, Simons includes the following helpful references:
RDMA Performance in Virtual Machines with QDR InfiniBand on vSphere 5
Best Practices for Performance Tuning of Latency-Sensitive Workloads in vSphere VMs
VMware HPC Blog


























































