 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetAt the cutting edge of HPC, bigger has always been seen as better and user demand has been the justification. However, as we now grapple with trans-petaflop machines and strive for exaflop ones, is evidence emerging that contradicts these notions? Might computers be getting too big to effectively serve up those FLOPS? Are the applications end users really demanding more? If our premises are no longer valid, perhaps we should rethink our HPC game plan.
Public procurement premises
The early machines in a new generation of high-end computers are almost always procured with public money. They are purchased, not simply to drive innovation in the computer industry, but principally to satisfy the perceived needs of researchers and applications developers whose science and engineering codes are straining the limits of existing computers and require more capable ones to succeed.
The rationale goes something like this:
- Progress in field X is crucially important to: the advancement of science, economic competitiveness, or national security (take your pick)
- Applications end users in field X assert that they cannot reach their objectives without better modeling and simulation
- Better modeling and simulation will require some or all of: more elaborate codes, faster execution, more memory, more runs, and longer run times
- These modeling and simulation objectives imply the need for a bigger and faster computer
This rationale has served us well for many decades. In less than 50 years, our highest-end computers have grown in performance from megaflops to tens of petaflops, a factor of more than 10,000,000,000.
Serious money
Reliable figures for the cost of machines at the top of the TOP500 list are hard to come by. Sometimes the numbers cited include development costs, sometimes they don’t. Sometimes the numbers are closer to the cost of materials than they are to a “market price” for a saleable product. Sometimes the numbers are somewhere in between these extremes, representing a discounted price to a favored customer and/or development partner. These caveats notwithstanding, it is clear that being at the top of the TOP500 list involves pretty serious money. A few months ago, Dan Olds writing in The Register, tried to identify “early-life prices” for machines that broke through various FLOP levels. Here are his results:
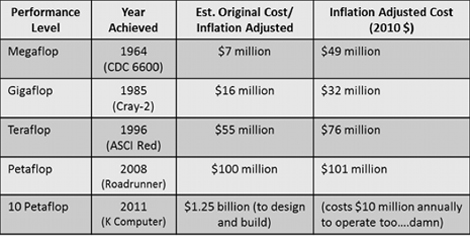
Note that the cost cited for the K Computer does include its development. The latest TOP500 list is topped by an IBM Blue Gene/Q system, named Sequoia, sited at Lawrence Livermore National Laboratory. Its Linpack performance is a bit over 16 petaflops. Sequoia’s cost has not been made public, but based on available information, a reasonable guess appears to be in the range of $210M to $230M. (If anyone has a better guess, please let us know.)

Above, we’ve plotted the cost history of these top computers, including Sequoia. To the data, we’ve added a couple of trend lines. The red trend line take in account all of the systems, while the blue one excludes the CDC 6600 and the K Computer as outliers. From the trends, it seems to be a pretty reasonable guess that by 2020 the top computer will cost $300 to $400 million US dollars, excluding development costs. By 2030, that number will have risen to more than half a billion dollars.
Given current and prospective future global financial constraints, it is not hard to imagine that the procurement premises used to justify public expenditures for top computers may come under much closer scrutiny than we’ve previously experienced. How will those premises fare?
Is bigger better?
Those who advocate for and fund the top machines generally depict them as tools for breakthroughs that could not possibly be achieved by other means – or lesser computers. Thus is born the idea of the “hero run,” where a single applications team uses the entire computer to do something amazing.
Reality differs from this image. Publicly funded high-end computers – including the top machines – are generally placed in environments where they are shared by a number of users. Depending on site policies, there may be anywhere from a few hundred to several thousand users on these machines. Furthermore, these computers are seldom devoted in their entirety to a single application run. When they are, that run is likely to be Linpack benchmark to qualify for the next edition of the TOP500 list.
So, if you do the math, no one really sees the full strength of the top computer. Users just get a slice of the machine, one that is probably equivalent to full use of some computer much lower on the TOP500 list (and much cheaper).
Failure is an Option
With trans-petaflop machines, failure (or “system interrupt”, if you prefer) is not only an option but also a fairly common occurrence. Data on the Mean Time Between Interrupts (MTBI) is not usually made public, but there are ways to infer that that interval is short enough to be a serious issue.
At the recent International Supercomputing Conference (ISC’12), Jack Dongarra gave a talk entitled Reduced Linpack to Keep the Run Time Manageable for Future TOP500 Lists. In it, he discussed the need to modify the Linpack benchmark so that it will execute in less time. The need for such a modification was clearly illustrated in his visuals. The table below provides the Linpack benchmark execution time for the top computer, over the history of the TOP500 list:

Note that recent top machines have taken 20 to 30 hours to complete the benchmark. The trend for Linpack run times, as presented by Dongarra, is illustrated below.


If this trend were to hold, running the benchmark on an exaflop machine would take almost six days. What is usually left unsaid is that 20 to 30 hours may already be in the MTBI range for the top computers. So in an attempt to get a complete measurement before the system encounters an interrupt, the benchmarking sessions may consist of several runs. Under such circumstances, running the current benchmark for six days is clearly out of the question.
What has this got to do with the real world of science and engineering applications? Recall the mantra of the Linpack benchmark: If you can’t run Linpack, you don’t have a prayer of running your real application. So, if Linpack is already in trouble because of MTBI issues, how is your application going to fare?
Thus, because of failure issues which are not broadly discussed, bigger machines may not be faster in terms of time to completion for real applications.
Do applications users care?
The most fundamental premise underpinning the case for public procurements of top machines is that the applications end users care. No matter how difficult these machines may be to use, they are needed and wanted. Science and engineering cannot make breakthroughs without them. However, there are a couple of indicators that contradict this view of users.
At the beginning of its consideration of an exascale initiative, The US Department of Energy’s Office of Science conducted an extensive series of workshops with applications end users from various disciplines. The reports and other documents from this Scientific Grand Challenges Workshop Series show mixed results.
The fundamental question asked was: How does your science require exascale computing for its advancement? The groups of applications users generally avoided answering that question and responded instead with information about how they would make use of an exascale computer if they had access to one. This difference may seem subtle, but it indicates that there was no generally perceived need among applications end users for exascale computing. Would they take it, if offered? Of course!
A more blatant, albeit more anecdotal, indicator came during a Think Tank panel session at ISC’12. The topic for panelist consideration was the end user’s perspective on the TOP500 List – 20 Years Later. Representing this point of view were three distinguished HPC managers – from Germany, Japan the US. From left to right in the photo below, they are:
- Michael Resch – Director, High Performance Computing Center, University of Stuttgart
- Satoshi Matsuoka – Professor, Global Scientific Information and Computing Center & Department of Mathematical and Computing Sciences, Tokyo Institute of Technology
- Dona Crawford – Associate Director for Computation at Lawrence Livermore National Laboratory
That’s me, Gary Johnson, on the right, moderating the panel. To my knowledge, there is no written transcript of the panel, but you can find video of it at the ISC Events Channel on YouTube.

After some discussion of a center manager’s viewpoint on the TOP500 list, I asked the panelists how their applications end users felt about it (the question was posed at about 15:50 minutes into the video). You can evaluate their responses for yourself, but what I heard was that, beyond perhaps some feeling of pride associated with running code on a top computer, the end users didn’t care about where their computer was on the list. Apparently, placement on the TOP500 has little effect on end user behavior. How does this reconcile with the idea that applications end users need top computers to advance their work? It appears that most of them are content to stay put at their “home” center and use whatever computing resources are available, rather than seeking out the biggest and best.
Whither Big Iron…?
Both big computers and competition to build bigger ones are here to stay. So, the comments made here and the questions posed are not meant to cast doubt on the eventuality of exaflop machines and those beyond. Rather, they are meant as a constructive critique of the standard rationale that we use to advocate high-end computing and to convince governments to spend public money on it. While Big Iron may be here to stay, the current “too big to flop” rationale that underpins these machines is clearly under stress.
It is prudent to periodically question one’s premises. If they cease to be valid, the conclusions that flow from them may be dubious. Right now, the premises underpinning the public procurement of top computers appear to have lost much of their validity. Perhaps we, the HPC community, should get out ahead of this situation, rethink our case, and then move forward on more solid ground.
If you have a different interpretation of events or the applications end users’ communal psyche, please let us know. In any case, we’d appreciate hearing your thoughts on how best to move HPC forward.
—–
About the author
 Gary M. Johnson is the founder of Computational Science Solutions, LLC, whose mission is to develop, advocate, and implement solutions for the global computational science and engineering community.
Gary M. Johnson is the founder of Computational Science Solutions, LLC, whose mission is to develop, advocate, and implement solutions for the global computational science and engineering community.
Dr. Johnson specializes in management of high performance computing, applied mathematics, and computational science research activities; advocacy, development, and management of high performance computing centers; development of national science and technology policy; and creation of education and research programs in computational engineering and science.
He has worked in Academia, Industry and Government. He has held full professorships at Colorado State University and George Mason University, been a researcher at United Technologies Research Center, and worked for the Department of Defense, NASA, and the Department of Energy.
He is a graduate of the U.S. Air Force Academy; holds advanced degrees from Caltech and the von Karman Institute; and has a Ph.D. in applied sciences from the University of Brussels.
Related Articles
Number Crunching, Data Crunching and Energy Efficiency: the HPC Hat Trick

























































