 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetLast week, Amazon Web Services kicked off its first annual customer and partner conference, AWS re: Invent. The cloud giant welcomed nearly 6,000 participants (at $1,099 a pop) to the Venetian Hotel in Las Vegas for three days of cloud-themed activities and keynotes (for $500 more, attendees could take part in AWS Technical Bootcamps).
 The Wednesday morning keynote session with AWS Senior Vice President Andrew Jassy revealed some big announcements, namely a cloud-based data warehouse service, AWS Redshift, and another price cut for the S3 storage service.
The Wednesday morning keynote session with AWS Senior Vice President Andrew Jassy revealed some big announcements, namely a cloud-based data warehouse service, AWS Redshift, and another price cut for the S3 storage service.
During his keynote, Jassy stated that “traditional old-guard data warehousing is really expensive and really complicated to manage.” Responding to these points and to customer requests, AWS set out to design a solution that was scalable, with pay-as-you-go pricing and no upfront costs, with an emphasis on high performance, low cost, and flexible integration. Jassy explained that their new data warehouse service, AWS RedShift, meets this profile at a tenth of the cost of traditional data warehousing products. The service automates deployment and administration and works with popular business intelligence tools, like MicroStrategy, Japsersoft, SAP BusinessObjects, and Cognos.
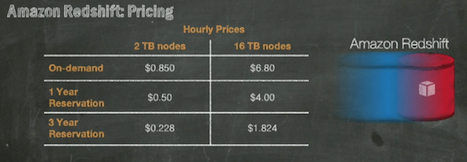
Amazon Redshift is available in two sizes, the hs1.xlarge and hs1.8xlarge instance, which hold 2 TB and 16 TB of compressed data respectively. An Amazon Redshift cluster can be created with 32 hs1.xlarge nodes for up to 64 TB of storage or 100 hs1.8xlarge nodes for up to 1.6 PB of storage. The default maximum cluster size is 40 nodes (640 TB of storage), but users have the option to request a limit increase. The data is stored in columnar format which means the I/O moves much more quickly, improving query times, notes Jassy.
Amazon is no stranger to traditional data warehousing solutions. The company’s retail division operates a warehouse cluster with 32 nodes, 4.2 TB of RAM and 1.6 PB of disk space that costs the company several million dollars per year. As a test case, AWS took 2 billion rows of data and six of their most complex queries and compared the two systems. Using 2 16 TB nodes on Redshift for $3.65/hour – or $32,000 a year – they achieved at least 10x faster performance.
On-demand pricing for the new service will start at $.85 per hour, but with a three-year reserved instance, the cost is less than $.23 an hour. Jassy points to analyst data that puts the cost of a typical data warehouse at $19,000-$25,000 per TB/year, while under Amazon’s reserved pricing model, Redshift costs less than $1,000 per TB/year. The service is currently offered in limited preview with a full launch expected in early 2013.
Jassy also declared that AWS is lowering the price of its Simple Storage Service (S3) by 24-28 percent in the US Standard Region and enacting similar price reductions in all nine regions worldwide. This is the 24th time AWS has reduced its pricing. For the first TB, the service now starts at 9.5 cents per GB/month, down from 12.5 cents per GB/month.
Amazon has the lead time and economies of scale that allow it to basically outbid the competition on price, but that doesn’t mean that its public cloud rivals are giving up or going home. The day before the re: Invent conference started, Google lowered its storage pricing by 20 percent. And then, on Thursday, presumably in response to the AWS decrease, Google lowered its prices again, by an additional 10 percent. Currently Google’s storage pricing sits at .85 per GB/month (for the first TB), 10 cents cheaper than Amazon’s. Google’s reduced availability storage service is also cheaper than Amazon’s. However Google does not have an equivalent to the low-cost Amazon Glacier service.
On Thursday, Amazon.com CTO Werner Vogels revealed two super-sized EC2 Instance Types, and another new service, the AWS Data Pipeline. Amazon’s new Cluster High Memory and High Storage Instances are larger than the new compute instances that Google debuted earlier in the week. The Cluster High Memory instance (cr1.8xlarge), which comes with 240 GB of RAM and 2 x 120 GB solid-state storage drives, is intended for large scale in-memory analytics applications. High Storage instances, available in only one size, High Storage Eight Extra Large (hs1.8xlarge), comes with 117 GB of RAM sitting on 48 TB of disk space provided by 24 2 TB hard drives, connected with 10 Gigabit Ethernet networking.
The AWS Data Pipeline is a lightweight orchestration service for data-driven workflows, aimed at extracting data’s “captive intelligence.” Currently in a limited private beta, the service lets users move data through several processing steps to a targeted destination. It is pre-integrated with AWS data sources and also connects with 3rd party and on-premises sources.
The conference was named re:Invent, and the final day offered attendees a fireside chat with CEO Jeff Bezos and CTO Werner Vogels, in which the pair discuss several keys to invention, one of which is a willingness to fail or be misunderstood. “This allows you ramp up your rate of experimentation,” notes Bezos. The discussion naturally comes around to cloud as the duo discuss how AWS has enabled companies to experiment faster and to be more innovative.
In closing Bezos offers some advice to aspiring entrepreneurs: 1) don’t chase fads (“wait for the wave and pick something you’re passionate about”); and 2) be customer-centric (“start with the customer and working backwards”). “Those two things will take you a long way, Bezos concludes.
Even after the conference has concluded, AWS news continues to roll in. Today the company announced that its AWS Marketplace now supports Windows-based software, including products from Parallels Software, MicroStrategy, and Quest Software. In addition, the AWS Marketplace now includes a Big Data category “for customers who want to analyze large amounts of data and are looking for ways to quickly solve Big Data problems.”
























































