 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetAn important problem to solve when bringing HPC applications to the cloud is determining how to make a virtualized set of clusters act like a physical high performance machine that can be accessed in-house.
 Researchers from the Suddhananda Engineering and Research Centre in Bhubaneswar, India developed a job scheduling system, which they call Service Level Agreement (SLA) scheduling, that is meant to achieve acceptable methods of resource provisioning similar to that of potential in-house systems. They combined that with an on-demand resource provisioner to ensure utilization optimization of virtual machines.
Researchers from the Suddhananda Engineering and Research Centre in Bhubaneswar, India developed a job scheduling system, which they call Service Level Agreement (SLA) scheduling, that is meant to achieve acceptable methods of resource provisioning similar to that of potential in-house systems. They combined that with an on-demand resource provisioner to ensure utilization optimization of virtual machines.
The SLA nomenclature is meant to express their addressing of the issues HPC applications could potentially cause with service providers. Computing in the cloud brings along various security requirements that must be strictly adhered to. This can be a problem when traditional workload management and scheduling is not necessarily meant to account for these conditions.
As shown in the diagram below, the SLA scheduler makes constant checks on the cloud resources to ensure both the lack of service violations and optimization of resources.

In a virtualized environment, resources are often provisioned separately. Resource provisioning is perhaps better known by its constituent methods, IaaS, PaaS, and SaaS. The researchers’ goal here was to take advantage of all provisioning methods by placing the SLA scheduler atop them all.
“The Cloud provisioning and deployment model presented in the figure below shows a scenario combining the three different types of resource provisioning to host service requested from customers,” the researchers noted. As they explain, the system is meant to validate and schedule the workloads such that slots in the various systems are filled optimally. “The customers place their service deployment requests to the service portal, which passes the requests to the request processing component to validate the requests. If the request is validated, it is then forwarded to the scheduler.”

Per the architecture diagram above, the SLA scheduling system connects to the service portal on the software side while accessing the provision engines in both the PaaS and the actual physical machines of the Iaas. Workload management is less of a problem in a system where all of the machines in next to each other, as information can be more easily collected and aggregated on where potential overloads are happening.
In a virtualized system, one where potentially the machines working with each other lie miles apart, the workload and connectivity bits are significantly more critical. As HPC applications run in the cloud tend to be of an experimental nature, where results are expected quickly such that further follow-up experiments can be run, it is essential that the scheduler here reduces bottleneck as much as possible.
The results, according to the researchers, of their proposed system are promising, as shown in the table below.
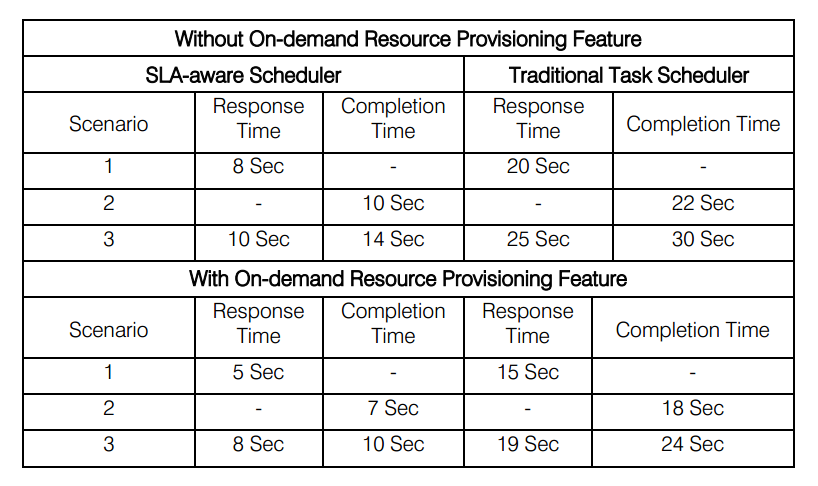
While it might be intuitive that an SLA-aware scheduler might take more time as a result of constantly checking the machines to ensure validation, one must consider that virtual machines would often be programmed to shut down than commit SLA violations, a process that adds significant more time than a simple slowdown.
In the scenario where the researchers tested only HPC applications, the SLA-aware scheduler coupled with the resource optimization measure to levels significantly better than applications run without those implementations, as seen in the diagram below.

As the researchers explained, “The scheduler achieved 100 percent resource utilization in scheduling and deploying the HPC applications as depicted by the first bar. That means the available resources are fully utilized.” That first bar applied to web applications, where parallelization is less important, and is meant to serve as a baseline. “Although the resources were fully utilized, the scheduler could only achieve 80 percent deployment efficiency. This is better result than the 49.67 percent achieved by the equivalent scenario in the fixed group.”
The key here was to vary resource utilization, as noted that the sub-optimal group was ‘fixed,’ meaning there was relatively little workload movement to underutilized resources. When that movement happened, resources were used approximately 60 percent more efficiently.
“By experiments,” the researchers concluded, “the proposed architecture is efficient in monitoring and detecting individual application SLA violation situations. Further one can automatically find the optimal measurement intervals by sampling different ones and checking their net utility values.” By doing this, the research team determined that a scheduling system that accounts for service agreements and actively works to avoid problems is actually more efficient than one that does not. Further, they drove home the importance of resource management and provisioning in creating an efficient virtual HPC environment.























































