 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall StreetResearchers are licking their chops with the potential to speed the execution of parallel applications on the largest supercomputers using Vampir, a performance tool that traces events and identifies problems in HPC applications. The scalability breakthrough with Vampir came as the result of work done on Jaguar, the predecessor to Titan at Oak Ridge National Laboratory.
Vampir (Visualization and Analysis of MPI Resources) was developed at the University of Dresden to help troubleshoot problems that develop in parallel HPC applications. The tool, which also now supports OpenMP, Pthreads, and Cuda in addition to MPI, is especially useful in flushing out any of the myriad bugs or other problems that appear when researchers begin running their code on larger parallel clusters.
The potential to smooth the scale-up process is especially important because researchers do not start out running their parallel codes on massive machines. Instead, they start out on departmental clusters or small sets of bigger machines, perhaps 100 processors at a time. There are any number of problems that can appear as researchers begin running HPC applications on larger machines–including the overuse of barriers and I/O chokepoints–and the scale-up process is rarely linear or smooth.
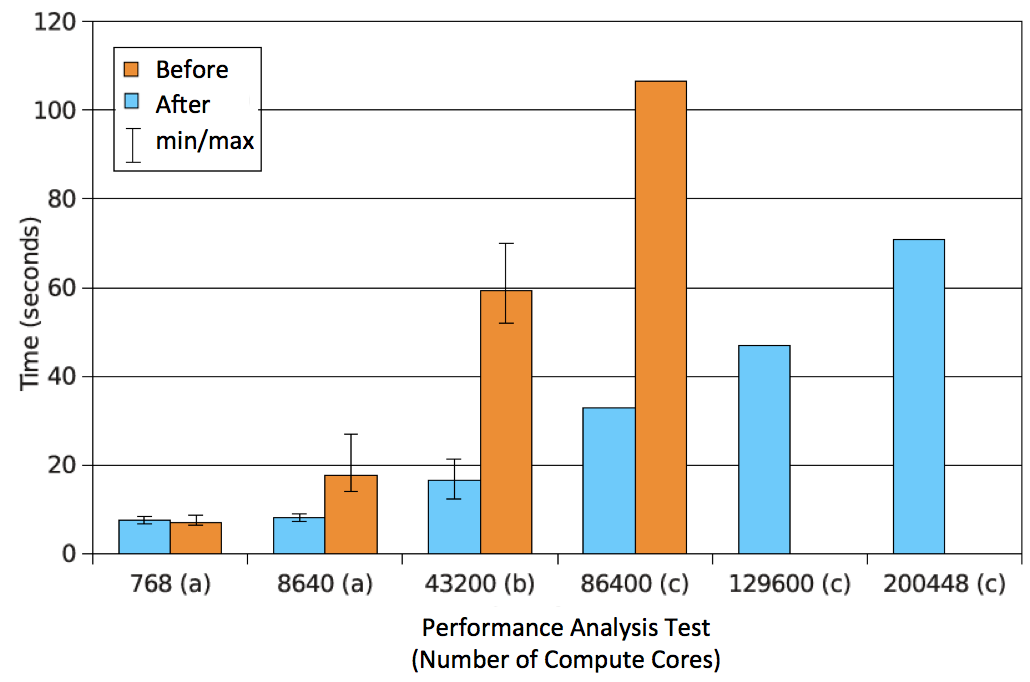 This graph demonstrates how Vampir can increase bandwidth performance and maximum job size.
This graph demonstrates how Vampir can increase bandwidth performance and maximum job size.
There were several issues with scaling Vampir itself that researchers had to overcome, according to a story published recently by the Oak Ridge Leadership Computing Facility website. One hurdle that researchers had to overcome involved how Vampir uses memory. Vampir works by installing itself onto a small portion of memory on each node, which it uses to log events as they occur in the HPC application.
However, if there isn’t enough memory available to capture all the events–either due to a long running application or by setting Vampir to collect a very fine level of detail of events–then the program slows down as huge amounts of data are written to the file system. The team of researchers addressed this problem by modifying the procedure to happen quickly and trouble-free, the ORLCF story notes.
The team successfully ran Vampir at scale on all 220,000 CPU processors on Jaguar in 2012. That was before Jaguar morphed into Titan, which sports nearly 300,000 CPUs (and more than 18,000 GPUs) and is currently the third-fastest supercomputer in the world. Prior to this, Vampir had only proven itself on a machine with 86,400 cores, according to the ORLCF story.
 Terry Jones of Oak Ridge National Laboratory, left, and Joseph Schuchart of Technische Universität Dresden were part of a team that readied the Vampir performance tool to work on extreme-scale supercomputers.
Terry Jones of Oak Ridge National Laboratory, left, and Joseph Schuchart of Technische Universität Dresden were part of a team that readied the Vampir performance tool to work on extreme-scale supercomputers.
“Understanding code behavior at this new scale with Vampir is huge,” ORNL computer scientist Terry Jones told ORLCF. “For people that are trying to build up a fast leadership-class program, we’ve given them a very powerful new tool to trace events at full size because things happen at larger scale that just don’t happen at smaller scale.”
The researchers involved in the work–including people from ORNL, Argonne National Laboratory, and Technische Universität Dresden–published their work in a June paper titled “Optimizing I/O forwarding techniques for extreme-scale event tracing.”
Related Articles
Titan Didn’t Redo LINPACK for June Top 500 List
Top Supercomputer Signals Growth of Chinese HPC Industry
























































