 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
The devastation incurred by the landfall of Hurricane Sandy on the northeast coast of the United States just over one year ago exemplifies the need for further advances in accuracy and reliability in numerical weather prediction. High resolution numerical weather simulations carried out on hundreds of thousands of processors on the largest supercomputers are providing these very insights.
The National Center for Atmospheric Research (NCAR) Weather Research and Forecasting (WRF) model has been employed on the largest yet storm prediction model using real data of over 4 billion points to simulate the landfall of Hurricane Sandy. Using an unprecedented 13,680 nodes (437,760 cores) of the Cray XE6 Blue Waters supercomputer at the National Center for Supercomputing Applications at the University of Illinois, the team of Peter Johnsen from Cray, Inc., Mark Straka from NCSA, and Mel Shapiro, Alan Norton, and Tom Galarneau from NCAR achieved an unprecedented level of performance for any weather model. The model used approximately 4 billion grid points at an extremely fine resolution of 500 meters. Forecast data was written and analyzed by the NCAR team members using the NCAR VAPOR visualization suite.
The landfall of Hurricane Sandy along the New Jersey shoreline late on October 30th, 2012 produced a catastrophic storm surge extending from New Jersey to Rhode Island. The research highlighted here demonstrates the capability of the NCSA/Cray Blue Waters supercomputer to conduct a cloud-resolving WRF-ARW simulation of an intense cyclone over a relatively large domain at a very-fine spatial resolution.
The Blue Waters system is a Cray XE/XK hybrid machine composed of 362,240 AMD 6276 “Interlagos” processors and 4224 NVIDIA GK110 Kepler accelerators all connected by the Cray Gemini 3-D (24^3) torus interconnect. It provides sustained performance of 1 petaflop on a range of real-world science and engineering applications. Our motivation was to reduce time to solution as much as was under our control without major source code restructuring. The WRF version 3.3.1 source code was modified from the public distribution chiefly with concerns for reducing the I/O burden per MPI task and limiting the necessary information to a single MPI rank.
Topology Considerations Are Vital
Domain configuration and process layout using MPI rank ordering features of the Cray XE6 job scheduler (ALPS) form a cornerstone in efficiently using the XE6 3D torus interconnect and allowing WRF to scale this successfully. We used the Cray grid_order utility to generate improved placement of the ranks for the primary communication pattern in the WRF solver, which is nearest neighbor halo exchanges. Reducing the number of neighbors communicating off-node is the primary goal. Using an alternate placement allows us to get 3 communication partners for most MPI ranks on the same node, instead of only 2, as would be with the default placement. At very high scales, this strategy improves overall WRF performance by 18% or more.
We found the most effective way to run WRF on the AMD Bulldozer core-modules was to exploit WRF’s “hybrid” MPI/OpenMP structure, utilizing 2 OpenMP threads per MPI rank. This puts 16 MPI ranks on each XE6 node.
The optimized placement we’ve employed also has the benefit of sending smaller east-west direction exchanges off-node and keeping as many larger north-south messages on-node as possible, resulting in 75% fewer bytes being sent over the network. We verified empirically the long-known tactic of decomposing WRF’s domain with many fewer MPI ranks in the X direction than the Y, as this leads to longer vectors on the inner compute loops.
Our simulations yielded an average Tflop count of 32.454 Tflops per second, per simulation time step. Parallel efficiency was still above 60% even on 13,680 XE6 nodes. Over 12 million off-node halo exchange messages totaling 280 GB were processed every WRF time step.
I/O Considerations at Scale
On the Blue Waters system, the Lustre file system was used for all file activity.
Two techniques were used to handle the large I/O requirements for the Sandy simulation –
- Parallel NetCDF (PnetCDF), jointly developed by Northwestern University and Argonne National Laboratory, was used where practical. The MPICH library from Cray has a tuned MPI-IO implementation that aligns parallel I/O with the Lustre file system. This format is required when post-processing tools are used.
- WRF has a multi-file option where each subdomain, or MPI rank, reads and writes unique files. This was used for very large restart files and some of the pre-processing steps. The Blue Waters Lustre file system was able to open and read 145,920 restart files in 18 seconds for a 4560 node case.
Additionally, use of WRF’s auxiliary history output options to select only the output fields of greatest interest, thus reducing the volume of output considerably, was of great utility in our work.

Scalability of Hurricane Sandy run. Sustained performance in Tflops/second (y-axis, left) and parallel efficiency over base run on 8,192 cores (y-axis, right) are shown.
Forecast Analysis and Validation
The following figures show a comparison of the maximum radar reflectivity (a surrogate for precipitation) from the simulations at 3-km and 500-m horizontal resolution. In both simulations, a broad region of heavy precipitation is located on the west and southwest side of Sandy, and is organized in a region where warm moist northeasterly flow intersects a northwesterly surge of cold continental air (not shown).

Comparison of (a) 3-km and (b) 500-m horizontal resolution ARW simulations of maximum radar reflectivity (shaded according to the color bar in dBZ) verifying at 1500 UTC 29 October 2012.
The 500-m simulation is superior to that at 3-km because it shows the fine-scale linear structure of the convective precipitation bands, consistent with the available observations (not shown). The next images show a zoomed-in view of maximum radar reflectivity and 300-m wind speed within the inner-core of Sandy at 1800 UTC 29 October 2012. This zoomed perspective allows for examination of the full detail of the simulation, noting that the resolution of the simulation (7000×7000 grid points) exceeds the resolution of standard computer monitors by a factor of seven. Here we note the utility of ultra-advanced computational capability to represent the full range of scales spanning the storm-scale circulations down to fine-scale turbulent motions and individual cloud and precipitation systems.
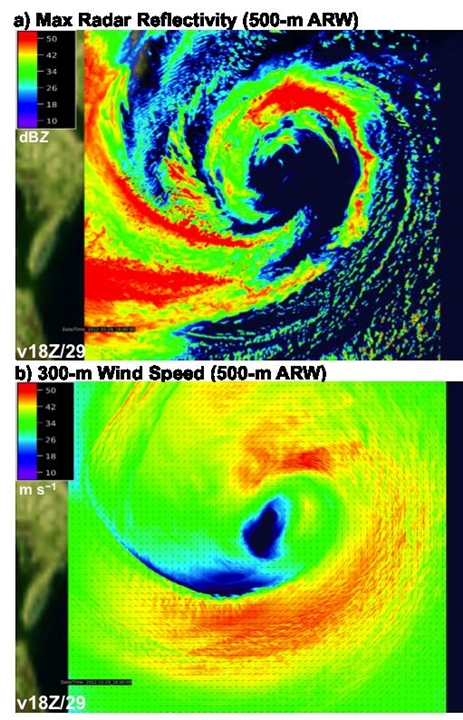
500-m ARW simulation of (a) maximum radar reflectivity (shaded according to the color bar in dBZ) and (b) 300-m wind speed (shaded according to the color bar in m s−1) verifying at 1800 UTC 29 October 2012.
The model accuracy for predicting such key output fields as rainfall, pressures, wind speeds, and storm track was graphically validated against actual atmospheric measurements from the storm using NCAR’s VAPOR software suite. Given recent advances in accessing and displaying large volume geophysical datasets as exemplified by the VAPOR software, it is now possible to view the full temporal evolution of numerical simulations and predictions of atmospheric and other geophysical systems. Examples of the advanced visualizations of Hurricane Sandy with VAPOR can be found at:
https://www.vapor.ucar.edu/sites/default/files/movies/sandy_SC13_web_0.mp4
The results of this research will be presented at the Supercomputing conference this month in November. See the conference agenda here:
http://sc13.supercomputing.org/schedule/event_detail.php?evid=pap255
Cutting Edge Forecasting
NOAA has initiated the ten-year Hurricane Forecast Improvement Project (HFIP), which is evaluating a variety of modeling approaches, exploring the feasibility of real-time fine-scale hurricane projections. Its enhanced Hurricane WRF model (HWRF) is already being run in real time at a somewhat smaller scale. In a collaborative effort involving NOAA’s Hurricane Research Division and Environmental Modeling Center, Cray , NCSA, and NCAR, this code is already being run on Blue Waters to conduct performance studies at scale with grid nesting never before possible. Results are already promising that coming years’ hurricane seasons will be able to incorporate much finer detailed real-time forecasts generated by these simulations. The team is also exploring high resolution simulations with the Office of Naval Research ONR using the COAMPS model.
Research Team:
Peter Johnsen is a performance engineer and meteorologist with Cray, Inc. Peter’s expertise is optimizing environmental applications on HPC systems.
Mark Straka specializes in performance analysis of scientific applications on the Blue Waters system at the National Center for Supercomputing Applications.
Melvyn Shapiro, Alan Norton, and Thomas Galarneau are research meteorologists with the National Center for Atmospheric Research and are studying many weather phenomena, including Hurricane Sandy’s unique nature.


























































