 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Intel’s Many Integrated Core (MIC) architecture was designed to accommodate highly-parallel applications, a great many of which rely on the Message Passing Interface (MPI) standard. Applications deployed on Intel Xeon Phi coprocessors may use offload programming, an approach similar to the CUDA framework for general purpose GPU (GPGPU) computing, in which the CPU-based application is equipped with directives that send the compute-intensive parts of the code and related data from the host system memory to the coprocessor. Unlike GPGPUs, though, Xeon Phi coprocessors can operate as independent IP-addressable manycore nodes allowing MPI processes to be run on them without involving the host CPUs. The so-called symmetric clustering model is attractive because it allows for relatively easy porting of CPU-based applications to clusters with manycore computing accelerators. The end-user can speedup HPC applications without having to restructure the code to implement data offload.
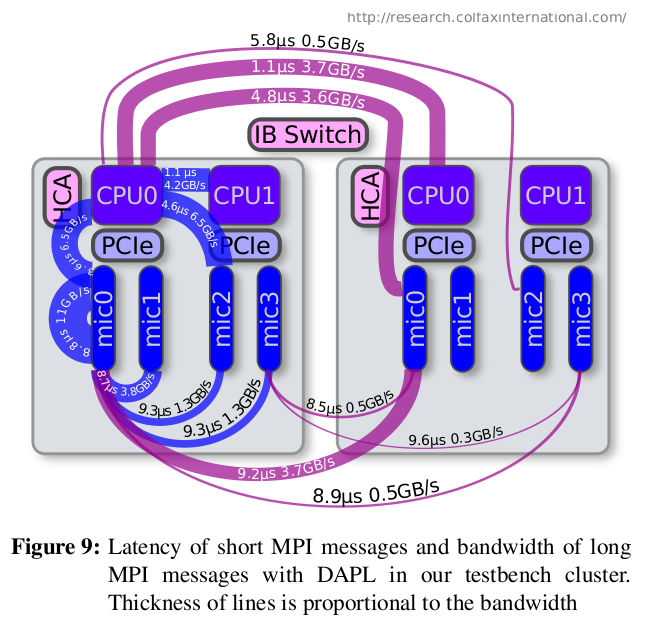 In the symmetric heterogeneous clustering setup, MPI processes are launched directly on coprocessors. Peer-to-peer communication between coprocessors occurs over network fabric virtualized in the operating system. MPI applications written for CPUs may be executed thusly without major code modification, however the convenience comes at the expense of reduced communication efficiency, at least in the absence of specialized networking hardware.
In the symmetric heterogeneous clustering setup, MPI processes are launched directly on coprocessors. Peer-to-peer communication between coprocessors occurs over network fabric virtualized in the operating system. MPI applications written for CPUs may be executed thusly without major code modification, however the convenience comes at the expense of reduced communication efficiency, at least in the absence of specialized networking hardware.
Colfax International researchers Vadim Karpusenko and Andrey Vladimirov address this shortcoming by implementing a Phi-based cluster with InfiniBand interconnects and the appropriate software. They describe the process and the results of their research in a recently published paper, “Configuration and Benchmarks of Peer-to-Peer MPI Communications Over Gigabit Ethernet and InfiniBand in a Cluster with Intel Xeon Phi Coprocessors.”
The authors compare MPI communication performance between coprocessors with the TCP protocol over the Ethernet fabric to the DAPL protocol over the InfiniBand fabric. They measure and discuss the latencies and bandwidths of MPI messages with and without advanced configuration with InfiniBand support. The tuning process for running an MPI application on the InfiniBand-based Phi cluster is also discussed, as is the impact of the InfiniBand protocol on an Asian option pricing application. The researchers also provide a set of recommendations for accommodating non-uniform communication bandwidth across the PCIe bus in high performance computing applications.
The trials were performed on a cluster consisting of two Colfax ProEdge SXP8600p workstations, each with four Intel Xeon Phi 31S1P coprocessors and one of the following networking setups:
1. Intel Gigabit Ethernet adapters installed in the systems and connected to a D-Link Gigabit Ethernet switch.
2. Mellanox InfiniBand ConnectX-3 Single-Port VPI 4X QDR adapters connected to a 36-port Mellanox Infiniscale IV switch.
The systems were outfitted with CentOS 6.5 Linux operating system with kernel 2.6.32-431.e16.x86_64, MPSS 3.1.2, Intel MPI 4.1.1.036, and OFED 1.5.4.1. The researchers relied on the Intel MPI Benchmark (IMB) that shipped with Intel MPI for performance measurements. The Message Passing Interface (MPI), a parallel programming model for distributed or shared memory platforms, can use different network configurations and fabrics for communication, but at this time the Intel MPI Library is the only implementation of MPI with support for Intel Xeon Phi coprocessors in a cluster.
It’s important to note that Xeon Phi coprocessors are Peripheral Component Interconnect Express (PCIe) end-point devices; they do not have Ethernet or InfiniBand ports that plug directly into the network. Instead, the Linux OS on coprocessors and the Manycore Platform Software Stack (MPSS) on hosts work together to virtualize networking on the coprocessor. The research paper details the nature of the peer-to-peer messaging between coprocessors and proposes several possible network configurations.
Several pages are devoted to Ethernet and InfiniBand messaging with the authors explaining how to set up and configure networking in a symmetric heterogenous cluster with MIC architecture and how to execute MPI applications on the configured cluster.
As the researchers suspected, their testing showed that the TCP protocol (Ethernet) was satisfactory for applications utilizing the offload model, but for heterogeneous MPI applications launched directly on coprocessors, peer-to-peer communication over Ethernet is orders of magnitude slower than the actual hardware limits.
The duo further demonstrate that installing InfiniBand controllers and related software on top of the MPSS provides a major improvement of MPI communication between hosts and coprocessors in a cluster, including intra-node communication between CPUs and coprocessors, intra-node communication between coprocessors, and inter-node communication between both types of devices.
The researchers observe that “despite degraded bandwidth in some cases, all communication paths involving Intel Xeon Phi coprocessors with InfiniBand are faster than with Gigabit Ethernet by one or two orders of magnitude.”

























































