 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Disk drives keep getting fatter, and the time to rebuild the data on them keeps taking longer and longer. And so the engineers at disk array maker Panasas have been working for the past several years to rework RAID data protection so it is more suitable to large scale parallel file systems. The culmination of this work is the new RAID 6+ feature of the PanFS 6.0 parallel file system, which launched this week concurrent with an update to the ActiveStor arrays that will see much more capacious disk drives added to the machines.
Garth Gibson, chief scientist at Panasas, was one of the co-authors of the original RAID research paper that came out of the University of California at Berkeley, suggesting that with the right data protection algorithms, an array of relatively cheap disk drives could be made more resilient than very expensive and larger disk subsystems commonly attached to high-end systems. The RAID paper is a quintessential example of using a parallel architecture to boost throughput and increase capacity while lowering cost and power consumption compared to monolithic systems. (In this case, 14-inch IBM 3380 mainframe disk drives versus an array of 3.5-inch SCSI disks from Conner Peripherals.) It is fitting that Gibson, who is still very much active in Panasas, has taken another swipe at RAID data protection and has come up with a new RAID 6+ triple parity protection scheme for PanFS 6.0. The update also includes what Panasas calls per-file distributed RAID, which as the name suggests protects at the file level and does not require for a whole disk drive to be rebuilt when there is a failure in a RAID set.
With RAID data protection being around for a long time, and with many variations that dice and slice parity data (used to recover lost disks) in different ways, it might seem strange that Panasas is talking about improving RAID algorithms. But in many cases, RAID controllers are bottlenecks in array performance, or RAID protection is not used and more brute force data replication methods are used instead. Panasas would content that this is wasteful and has invested to make RAID data protection better as it scales across larger and larger arrays.
“We know that unstructured data growth is driving requirements for next-generation storage arrays in the enterprise and in HPC,” explains Faye Pairman, president and chief executive officer at Panasas, and, citing statistics that data growth is expected to increase by 800 percent over the next five years, “four-fifths of that data is going to be unstructured.”
“We think the explosion of data drives a different view on availability and reliability,” notes Pairman, “HPC always leads the way, and there is almost an insatiable desire for more processing and that always drives storage attachment rates. Whether it is traditional HPC or scale-out enterprise with unstructured data, we think that the size of the deployments and the size of the disk drives used today really dictated a need for a different approach to scalability and availability.”
The ActiveStor arrays differ from many network-attached storage arrays in that the architecture of the hardware and the software is such that there are no filers or traffic managers in the datapath between the systems requesting data and the storage blades that are the building block of the ActiveStor machines. The file system is parallel and the data paths are parallel, so a blade can pass data directly from a blade in the ActiveStor array to a cluster node; there is no bottleneck.
The problem with traditional RAID arrays (whether they are based on disk or flash drives or a mix of the two) is that reliability worsens linearly as you scale up the array. The more devices you have, the higher the probability of a failure at any given time. Also, on RAID arrays, if you lose single sectors on a disk drive, you have to rebuild an entire drive. With RAID 5 and RAID 6 protection, the parity data that is used to rebuild missing files using the RAID algorithm is spread across multiple drives and is used to recreate the data when a disk crashes (you basically run the algorithm that spread a file across the drives backwards, adding in the parity data to calculate the missing bits). This is all well and good until you have 4 TB or 6 TB disk drives, which take forever to rebuild, and it is even less practical when you have hundreds to thousands of such fat disks in an array. At any given time, a disk is failing and recovering, and this impacts performance for a RAID group. In some arrays, losing a RAID group means the whole file system is down, and in a worst case scenario, it can take weeks to restore an entire file system. While the file system is down, the system is down, even if only one file is actually the only thing that is corrupted.
“We don’t want to rebuild an entire gigantic array just to recover a number of files,” explains Pairman. “And we are addressing this notion that the system is either all up or all down. Up until now, there was no process to be able to access unaffected files.”
Concurrent with the launch of the new PanFS 6.0 is a set of new hardware, called the ActiveStor 16 arrays. The new arrays employ the UltraStar He6 disk drives from HGST (formerly a unit of Hitachi and now owned by Western Digital). These are the first 6 TB drives on the market, and that 50 percent increase in density is made possible because helium gas is less turbulent than air. The lower turbulence also cuts energy use by the 3.5-inch disk drive by 23 percent.
The ActiveStor arrays have two types of blades, a storage blade and a director blade. As the name suggests, the director blade manages the system and also keeps metadata about where files are stored on the parallel file system. With the ActiveStor 16 update, Panasas is shifting to a faster quad-core 2.53 GHz “Jasper Forest” processor from Intel. (This is a chip made for embedded applications). This director blade also has 48 GB of if own memory used as metadata cache, and this extra CPU and memory capacity helps improve RAID rebuilds as well as small file serving and metadata performance.
The storage blades on the ActiveStor 16 have their components right sized for the fatter 6 TB disks, with a larger 240 GB solid state disk for serving up small files and metadata and optimized to run the RAID6+ protocol. The storage blade has a single-core version of the Jasper Forest Intel processor, and it has 8 GB of its own memory that is used as cache plus two 6 TB drives. A 4U shelf of the ActiveStor 16 arrays has 122.4 TB of capacity and 1.5 GB/sec of bandwidth across its 20 storage blades. Up to 100 shelves, with a maximum of 2,000 disks and 1,000 SSDs, can be lashed together in a single global namespace that spans 12 PB of capacity and delivers 150 GB/sec of bandwidth out of the PanFS file system.
With RAID 6, two copies of the parity data used to reconstruct a failed disk drive are spread across the RAID group. With the RAID 6+ triple parity protection cooked up by Gibson and his colleagues at Panasas, the three copies of the parity data allow for protection against two simultaneous drive failures and single sector errors on multiple drives. This is about 150X more reliable than dual parity approaches in RAID arrays, explains Geoffrey Noer, senior director of product marketing at Panasas. The RAID 6+ algorithm carries about a 25 percent capacity overhead, compared to around 18 percent with most dual parity RAID 6 controllers, according to Noer.
While the RAID 6+ triple parity is important, so is the per-file distributed RAID that is also part of the new PanFS 6.0. With this feature, the rebuilding process scales linearly with the number of directors in the whole parallel file system, and importantly, the more drives you have, the less dramatic the recovery measures have to be. Here is a visual to illustrate how the recovery is less arduous when three drives fail on an array with twenty drives compared to one with only ten drives:
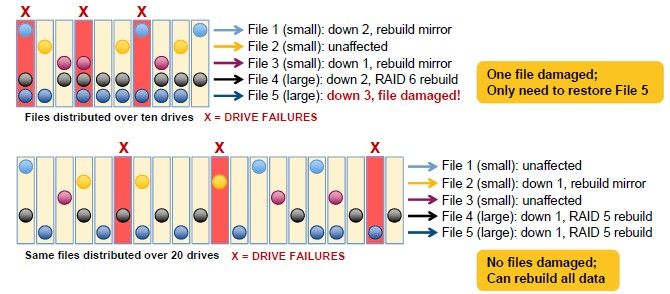
On a traditional RAID 6 array with ten fixed drives and a RAID controller, if you lose three drives, you have to restore all the files. On an ActiveStor array running the PanFS software, as you scale up the drives, the percent of files that need to be restored goes down because data is spread further apart on the increasing number of drives. So, for instance, Panasas says that on an ActiveStor with 40 drives, three disk failures could mean having to restore a few percent of the files, but as you scale up to 2,000 drives the share of files that needs to be restored gets very close to zero. On an array with 1,000 drives, about one in 200 million files will need to be restored after a three disk failure, according to Noer. And, thanks to the Extended File System Availability feature in PanFS, all of the files that are not affected by a three-drive failure event can be accessed normally. The dead files have to be restored from the RAID parity data or from an archive.
“A file system that is ten times larger rebuilds ten times faster,” says Noer, providing a rule of thumb. “This is important because if you have ten times the number of drives, but the rebuild is one tenth of the time, your risk has stayed the same.” When you add in the per-file distributed RAID, then scaling up the file system by a factor of ten actually increases the reliability of the data in the file system by a factor of a thousand.
Here is the pricing on the ActiveStor 14 and 16 arrays:

Panasas is taking orders for the ActiveStor 16 systems now and expects to start shipping the PanFS file system and the new arrays in September. PanFS 6.0 will be available to customers using ActiveStor 11, 12, and 14 systems (there was no 13 generation) who have their systems under current maintenance contracts. PanFS 6.0 ships by default on the ActiveStor 16 arrays.

























































