 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
The first wave of credible 64-bit ARM processors are coming to market late this year or early next, and as is usually the case, the high-performance computing community is getting first crack at figuring out how these chips might be deployed to run various kinds of simulations more efficiently or cost effectively.
Applied Micro, which has first mover status in the 64-bit ARM server chip race with its X-Gene 1, is teaming up with Nvidia, maker of the Tesla GPU accelerators, at the International Super Computing conference in Leipzig, Germany to promote X-Gene and Tesla as the first of several dynamic duos. Three vendors – Cirrascale, E4 Computer Engineering, and Eurotech – are also previewing hybrid ARM-Tesla systems at the conference, and others will no doubt follow soon as more ARM chips come to market towards the end of this year and into early next year.
Given the ubiquity of Xeon processors in the supercomputing space, Nvidia has to integrate well with rival Intel’s Xeon processors and has to compete against the Xeon Phi parallel X86 coprocessors, too. But Nvidia, like many system buyers, wants a second or third option when it comes to processors, and that is why Nvidia was a founding member of the OpenPower Foundation, which seeks to establish multiple sources of IBM’s Power8 and follow-on processors and to link accelerators tightly to them. Nvidia is also waving the ARM banner high as well, and wants to be the accelerator of choice for ARMv8 platforms.
“GPUs make 64-bit ARM competitive in HPC on day one,” explains Ian Buck, general manager of GPU computing software at Nvidia. “We are clearly seeing viable and compelling ARM64 platforms coming online. It is obvious that there is excitement around ARM, and there are two reasons for that. One is that we haven’t had new, innovative CPUs for a while. Some of the ARM architectures are going up to 24 cores, and they are playing with what is on die, what is off, and Broadcom and Cavium come from the networking world and there are lots of networking angles they can play. The second reason for the excitement is choice. ARM represents choice, and a very diverse one.

While network devices like to have plenty of threads, the chips used in such gear are not generally equipped with lots of floating point math processing capability, says Buck. Nvidia, you can quickly guess, wants its Tesla to be the coprocessor of choice for 64-bit ARM platforms. Having created the CUDA programming environment, which supports 64-bit ARM chips starting with the 6.5 release, and a library of hundreds of third party simulation and analytics workloads to hybrid processor-GPU, Nvidia thinks it is well placed to help customers port their applications to ARM-Tesla hybrids.
“Based on our experience with ARM to date, the porting seems to go fairly quickly if you have well-structured code,” says Buck. “A lot of HPC codes have been around long enough that they don’t have a lot of intrinsics in there, the X86isms, and code seems to move fairly easily. If the code is already GPU-accelerated, then the performance just carries straight over. These ARM64 chips can drive full GPU performance.”
Applied Micro is going to have plenty of competition in the ARMv8 processor space, with AMD, Cavium, and Broadcom all putting forth very strong contenders to go up against the hegemony of Intel’s Xeon processors and its very credible defensive position with Atom chips for modest compute and low-power needs. Intel has a substantial lead in chip manufacturing processes – something between one and two nodes, depending on how you want to count it – and is behaving as if it has a bunch of AMDs on its heels. Never before in its history has Intel been so willing to tweak its processor designs to make them better fit the workloads of supercomputing and hyperscale customers alike, from adding special instructions to Xeons to baking special versions of the Xeons that run hotter or clock higher to actually welding an FPGA into a Xeon chip, as Intel last week announced it was going to do.
This newfound openness is one way Intel is going to counter the onslaught of different 64-bit ARM processors and the various ways their makers will accelerate workloads using GPUs, DSPs, FPGAs, and other specialized circuits. In effect, Intel is adopting the malleable approach of the ARM community to defend against ARM processors.
The initial X-Gene 1 processor from Applied Micro has been sampling since early 2013, and production wafers for the chip were started at the end of March and production chips are due around now. The X-Gene 1 chip is implemented in a 40 nanometer process at Taiwan Semiconductor Manufacturing Corp; it has eight custom ARMv8 cores, designed by Applied Micro itself, on each system-on-chip. The cores on the X-Gene 1 run at 2.4 GHz, and Sanchayan Sinha, senior product manager, tells HPCwire that in terms of single-threaded performance, the X-Gene 1 has about the same level of oomph as a four-core “Haswell” Xeon E3 and about the same memory bandwidth as a “Sandy Bridge” Xeon E5.
Sinha stressed that these were very rough comparisons and that real benchmarks would eventually result in harder figures than these approximations. That is, in fact, what the development systems being shown off at ISC’14 are all about. The company is working with server partners to run the High Performance Conjugate Gradients (HPCG) benchmark, which is being proposed as a follow-on to the more widely used Linpack parallel Fortran matrix math test, on X-Gene 1 systems. Sinha says that Applied Micro and Nvidia will be able to show that an X-Gene 1 plus a Tesla K20 coprocessor will be equivalent to an X86 processor plus the same Tesla K20 floating point motor.
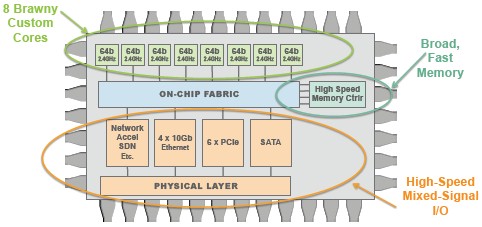
The X-Gene 2 chip is a rev on the initial design and also includes eight ARM cores, but it is implemented in a 28 nanometer process at TSMC. This shrink of the process will allow Applied Micro to crank up the clock speed and add more features to its SoC. One interesting feature that the company has divulged it will add to the X-Gene 2 is support for Remote Direct Memory Access (RDMA) on the network ports on the chip. Specifically, the Ethernet ports on the chip will be able to run RDMA over Converged Ethernet (RoCE), which brings the low-latency access of InfiniBand to the Ethernet protocol. This will make the X-Gene 2 chip not only suitable for HPC workloads that are latency sensitive, but also for database, storage, and transaction processing workloads in enterprise datacenters that also like low latency.
Further out beyond this, Applied Micro has teamed up with TSMC to use its 16 nanometer FinFET 3D transistor process to create X-Gene 3. Little is known about this processor except that it will have at least 16 cores on the SoC.
This early revs of the X-Gene 1 were put on development boards called “Mustang” internally by Applied Micro and known as the X-Gene XC-1 outside of the company. The ARM-based HPC systems that are being previewed by Cirrascale and E4 Computer Engineering are based on production-grade X-Gene 1 chips and the Mustang boards.
The Cirrascale development machine puts two Mustang boards and two Tesla K20 or K20X GPU accelerators in a compact 1U server chassis:

This machine is called the RM1905D in the Cirrascale product catalog, and like other Mustang board it supports a maximum of 64 GB of memory for each X-Gene 1 chip across the processor’s two memory slots. The system has four Ethernet ports: three for data and one for system management. Two of the ports for data exchange run at 1 Gb/sec and the remaining one runs at 10 Gb/sec; the management port runs at 1 Gb/sec. The Mustang board has one PCI-Express 3.0 x8 slot, which is used to link the processor to the Tesla GPU, and the chassis has room to plug in a single SATA-2 drive (a 6 Gb/sec link). Each node in the chassis has a 400 watt power supply.
The feeds and speeds of E4 Computer Engineering’s EK003 were not available at press time, but Nvidia tells HPCwire that the machine will include two X-Gene 1 system boards in a 3U enclosure that has two Tesla K20 GPU coprocessors, and that the development machine will be aimed at seismic, signal and image processing, video analytics, track analysis, Web applications, and MapReduce workloads.
Cirrascale and E4 Computer Engineering plan to ship their development machines in July, according to Nvidia.
Eurotech has a custom motherboard design using the X-Gene 1 chip that has main memory soldered onto the board to give it a very low profile and therefore high density for its ARM-based Aurora system. The compute elements in this new Aurora machine are based on what the company calls its “brick technology,” and will employ direct hot-water cooling of the components in the brick. It will include a combination of ARM processors and Tesla coprocessors. Further details for this Eurotech Aurora system were not yet available at press time, but we will hunt them down. The company expects to ship production machines later this year.


























































