 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
One of the undisputed themes at ISC14 was the continued speculation about how the Top500 Linpack benchmark will keep pace with evolving system and application demands. We have been following progress with the HPCG companion metric that Linpack co-founders Dr. Jack Dongarra, Piotr Luszczek (both at the University of Tennessee/Oak Ridge National Lab) and Michael Heroux at Sandia proposed well over a year ago. Following a session today at the close of ISC by Jack Dongarra, we now have a clearer sense of how this tool might round out current rankings.
The goals of the new benchmark are to stress a balance of floating point and communication bandwidth and latency and to tighten the focus on messaging, memory, and parallelization. As the benchmark continues to develop, the team hopes that it will become easier to use and optimize as well as simpler to check results within. The goal is longevity—one of the key strengths of Linpack, which was taken 20 years of development and outreach to promote. Dongarra hopes it will have more relevance to a broad collection of important applications, all defined within a single number.
There are plenty of materials available for delving into the specifics of the benchmark, so we shall leave you to it if interested. For now, we wanted to report the first detailed results of the benchmark we expect to see far more of listed alongside the Top500 results. What one can see below, even without detailed kernel-level research, is how the differences between the systems look less dramatic when other considerations, particularly the local memory system performance and low latency cooperative threading, are given significant weight.
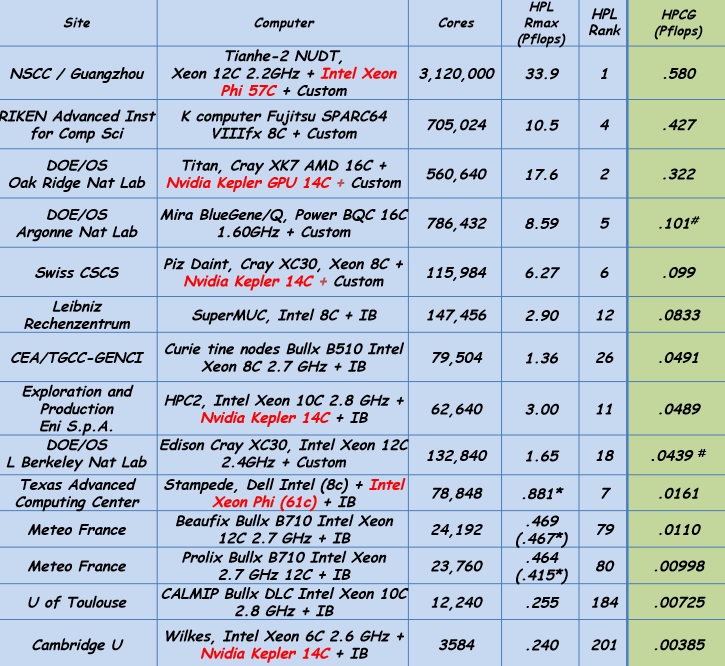
From an initial view, not only do the results appear a bit less dramatic, as noted previously, the differences between machines that today are profound, there does not appear much variation. However, if one considers from an outsider perspective what the original numbers might mean to those who do not follow supercomputer rankings, they might have seemed just as insignificant. The point is, the complementay benchmark is critical to vendors because it reflect their customer requirements. And if those demands are being met, it is vital because it means a more comprehensive approach all around to high end computing. That means scientific and enterprise benefit–it will just be a matter of time and communication to ensure this is accepted. It doesn´t happen overnight, as Dongarra has noted.
High performance Linpack is no longer strongly tied to real application performance, particularly for the growing base of HPC applications that are reliant on partial differential equations, says Dongarra. Further, he adds, designing a system with HPL at the forefront can actually lead to design choices that are not a good fit for the actual application mix and can add extraneous elements to the machine. The drivers for this complementary benchmark are already critical and the issues that make Linpack a faulty metric will become increasingly pronounced.
As Dongarra and team have reiterated since the creation of the new benchmark was announced, this will not replace or diminish the role of the Top500 as an important metric for larger trends in supercomputing. There are many advantages to Linpack, not the least of which is that it allows the community to see long-term trends. Twice per year, the world pays close attention to supercomputing, even if it tends to fall off the mainstream radar otherwise, because of the historical attention that is focused on the world´s fastest supercomputers. Outside of the trend analysis and wider recognition the list brings, Linpack is relatively easy to understand and run, it´s not difficult to check the results for site participants.
Even still, a great deal of the Top500 aspirations are fed by a benchmark that itself is 37 years old (the Top500 is over 20 years). Dongarra admits that it is being used as a marketing tool and that it is not feasible for machines to be based on a singular number. And with those limitations, when one considers the days spent running the actual benchmark, it just no longer adds up for users. And while peak performance numbers are sexy, actual usage of the machines does not live up to the hype with most systems achieving half or three-quarters (best case) of those benchmarked results. In the end, it constrains system choices for those looking to meet the benchmark and that is not useful–especially in the era of increasingly data-intensive problems.
Dongarra says more details will be worked out at SC during a BoF series. At this point, the team is considering a Top 50 while the early kinks are worked out.
For fun, and to honor the longevity of the benchmark, take a look at the Linpack mobile. That’s Jack on the left, and to the right, Cleve Moler, Pete Stewart, and Jim Bunch. Cool fellows then and now….

Note – Please forgive any temporary punctuation or formatting errors. Your author is traveling post-ISC and it turns out that German keyboards are…special.


























































