 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Technology, like other facets of life, commonly experiences cycles of rapid change followed by periods of relative stability. Computing has entered a stage of increased architectural diversity, as evidenced by the rise of accelerators, coprocessors, and other alternatives, like ARM processors. An international team of researchers explores how these various supercomputing architectures perform on parallelized turbulent flow problems.
In their paper “Direct Numerical Simulation of Turbulent Flows with Parallel Algorithms for Various Computing Architectures,” the authors describe the process of creating efficient parallel algorithms for large-scale simulations of turbulent flows and comparing their performance on AMD, NVIDIA and Intel Xeon Phi parts. They also introduce a new series of direct numerical simulations of incompressible turbulent flows with heat transfer performed with the newly-developed algorithms.
The authors classify modern supercomputers into three categories:
1. Classical ones that run on computing power of central processing units (CPU)
2. Hybrid machines with CPUs and graphics processing units (GPU)
3. Hybrid machines with CPUs and Intel Xeon Phi accelerators of many integrated core (MIC) architecture.
To optimize performance, algorithms need to be customized for each system type.
“The first type, the basic one, requires highly scalable parallel algorithms that can run on thousands of cores,” the authors state. “It also needs efficient shared-memory parallelization with large number of threads to engage modern multi-core nodes: two 12-core Intel Xeon CPUs with Hyper Threading (HT) can execute 48 parallel threads on a dual-CPU node. In addition it needs efficient vectorization since AVX extension operates with vectors of 4 doubles. The second type requires adaptation of algorithms to the streaming processing which is a simplified form of parallel processing related with SIMD (single instruction multiple data) model. This can be a challenge itself. The third type requires much more deep multi-threaded parallelism and vectorization than the first type.”
There is also a fourth type, ARM-based architectures, which like other hybrid types, involve a lot of attention to optimize memory access and load balancing between the CPU and accelerators. However, the main focus of this paper is on GPGPUs from NVIDIA and AMD and on the Intel Phi coprocessor.
The team take a multilevel approach that combines different parallel models. They explain: “MPI is used on the first level within the distributed memory model to couple computing nodes of a supercomputer. On the second level OpenMP is used to engage multi-core CPUs and/or Intel Xeon Phi accelerators. The third level exploits the computing potential of massively-parallel accelerators.”
OpenMP and OpenCL-based extensions were developed to exploit the computing potential of modern hybrid machines. In adapting the computational algorithms to different accelerator architectures, the group came across some interesting findings regarding performance.

Figure 3: Comparison of performance on a mesh with 472114 cells (flow around a sphere) for different devices using a 1st order finite-volume scheme for unstructured meshes
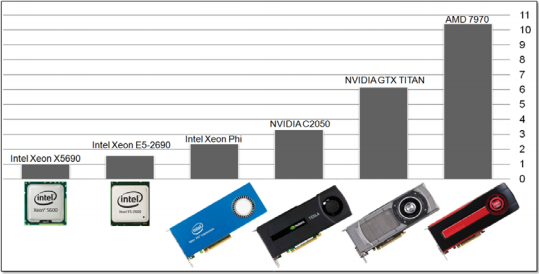
Figure 4: Comparison of performance on a mesh with 679339 cells (flow around a sphere) for different devices using a 2nd order polynomial-based finite-volume scheme for unstructured meshes
Looking at figure 3 and 4 (above) the team stated “it can be noted that for the 1st order scheme (Figure 3) NVIDIA GTX TITAN outperforms AMD 7970 while for the 2nd order polynomial-based scheme which requires much more resources (registers and shared memory usage) AMD one significantly outperforms NVIDIA one. This indicates the insufficiency of register and local memory of NVIDIA architecture that prevents from achieving high occupancy of the device and reduces efficiency.”
Also in Figure 4, it can be seen that the Intel Xeon Phi architecture is less performant than the various GPUs. Although this could be due to the OpenCL implementation, an OpenMP implementations resulted in similar behavior, providing only a 10-20 percent speedup over an 8-core Intel Xeon E5-2690 CPU.
“So the common statement that Intel Xeon Phi is much easier to use than GPU because it can handle the same CPU code is an illusion,” they conclude. “The computing power of this kind of accelerator is much more difficult to get.”
Structured and unstructured mesh algorithms modified for significantly multithreaded OpenMP parallelization demonstrated high internal speedups: up to 200 times faster on Intel Xeon Phi compared to a sequential execution on the same accelerator. However, net performance was not much higher than an 8-core CPU. Surprised by this result, the team speculates it could be related to insufficient memory latency hiding mechanisms that are based on 4-thread hyper threading. A GPU, they note, can have tens of threads switching for latency hiding. They add that poor cache performance could also be a contributing factor.
The paper serves as another reminder that system architectures must be assessed in the context of a specific workloads. For the OpenCL kernels of the algorithm on unstructured meshes, “the different GPUs considered substantially outperform Intel Xeon Phi accelerator,” the team concludes, adding, “the AMD GPU tends to be more efficient than NVIDIA on heavy computing kernels.”
























































