 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
This morning Cray unveiled the full details about its next generation supercomputer to follow on the heels of the XC30 family, which serves as the backbone for a number of Top 500 systems, including the top ten-ranked “Piz Daint” machine.
The newly announced XC40 already serves as the underpinnings for the massive Trinity system at Los Alamos National Laboratory, the upcoming NERSC-8 “Cori” machine, and several other early release systems installed at iVEC and other locations. While the announcement of the system is not unexpected since the aforementioned centers have already shared that they are installing “next generation” Cray systems, the meat is in the details. For instance, we knew about a “burst buffer” component on these machine, but knew little about the Cray-engineered I/O caching tier, not to mention what the configuration options in terms of snapping in the new Haswell (and future) future chips, accelerators or coprocessors might be.
Cray’s Jay Gould shed light on the XC40 for us, noting the early successes of the machine and what they hope its trajectory will be at the high end. Gould says that many of the large-scale early ship customers are using the configurability options offered to build high core-count, high frequency systems that take advantage of DDR4 memory options as well as the new DataWarp I/O acceleration offering built into XC40.
While early customers have been eager to take advantage of the cores available with the new Haswell processors, Cray is not offering the full range of SKUs Intel released recently with its Haswell news. While we’re still waiting on a list of what will be available, he did note that there are plenty of core, frequency, and thermal profiles to choose from, which is only part of their story around customization and configurability. With a 2X improvement in performance and scalability proven thus far over the XC30, Gould says that fine-tuning an XC40 for application performance needs is no different than it was with the XC30, and they have sought to make upgrades simple (including the ability to plug in the new Broadwell cards when they arrive) as well as offering new boosts, including DDR4 memory.
Gould said that when they arrived at figure that this offered at the 2X performance improvement over the XC30, this was based on the 16-core, 2.6 Ghz Intel (2693 v3) part, even if it might have gone higher with the 18-core variant. The reason, as you might have guessed, is all about heat. Even with the liquid cooled systems, the 18-core chips were running too hot, although he says that the 16-core chips offer a sweet spot between performance and thermal concerns. Cray is offering a scaled-down version of the XC40 that is air cooled and 16 blades instead of the XC40’s 48 blades in a liquid cooled wrapper that users are already tapping to prove out their applications before moving to a full XC40 machine, although it’s likely the same SKUs for the XC40 will be offered here as well, despite reduced density and better airflow.
But aside from configuration options, there is more to this machine than meets the eye, starting at the blade design level. With the arrival of the new Xeon E5 v3 series, Cray took to rethinking their existing blade design to make sure they could balance all that compute with more memory. They’ve made the shift to higher capacity DIMMs in DDR4, which provides higher memory bandwidth per blade as well as some options around memory, offering up 64-256 GB per node.
The most unique feature of the XC40, however, is a combination of hardware and software. Cray has created a third tier to address high I/O demands called DataWarp. In essence, this is home-cooked application I/O technology designed to address the imbalances that continue to plague large-scale systems that have a performance and efficiency chasm separating the compute nodes, local memory, and the parallel file systems and spinning disks. Currently, a lot of sites end up overprovisioning their storage to address peak I/O activity, which is expensive, inefficient, and can be addressed by the “burst buffer” concept. Cray’s approach involves what you see below with the SSDs on an “I/O blade” that can inserted into a bank of compute nodes, providing ready access to I/O cache at the compute level without putting all the data across the network to meet the file system and storage.
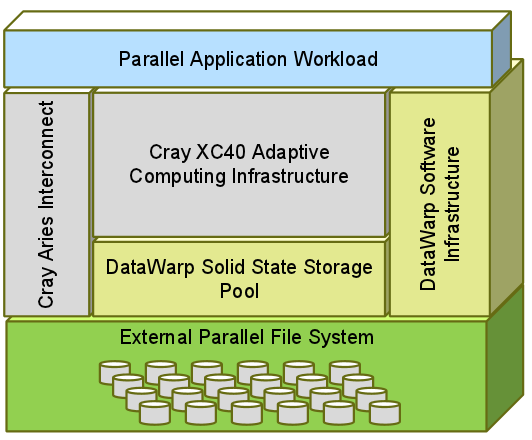
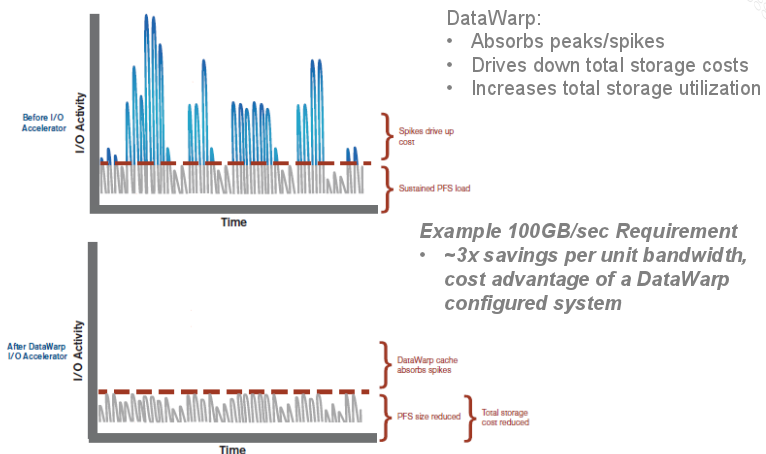
This can be used in the burst buffer sense that Gary Grider, an early user of the system and this feature, described for us in detail not long ago. However, this is just one of the use cases possible with the DataWarp layer, hence Cray’s avoidance of calling it an actual burst buffer in any of its early literature on the system.The point is it pushes “70,000 to 40 million IOPS” per system, which is a 5x performance improvement over a disk-based system for the same price. Getting a proper balance of the compute and memory and the new DataWarp I/O and disk, we can rebalance those tiers and offer the fastest performance,” said Gould.
We’ll be looking forward to following up with more early users to explore in a specific article a few of the other use cases of the DataWarp capability, including NERSC, which is using it for application acceleration as well as checkpoint/restart. We’re also expecting news around a few more deployments of this machine at a few global centers aside from those that are public, including Trinity, Cori, and the iVec system.


























































