 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Within the HPC vendor and science community, the groundswell of support for HPC and big data convergence is undeniable with sentiments running the gamut from the pragmatic to the enthusiastic. For Argonne computer scientist and HPC veteran Pete Beckman, the writing is on the wall. As the leader of the Argo exascale software project and one of the principal organizers of the workshop series on Big Data and Extreme-scale Computing (BDEC), Beckman and his collaborators are helping to usher in a new era in research computing, where one machine will be capable of meeting the needs of the extreme-scale simulation and data analysis communities.
The BDEC series of international workshops that Beckman is leading along with Jack Dongarra of the University of Tennessee is premised on the need to systematically map out the ways in which the major issues associated with big data intersect and interact with plans for achieving exascale computing. The overarching goal of BDEC is to create an international collaborative process focused on the co-design of software infrastructure necessary to support both big data and extreme computing for scientific discovery. The effort aligns with one of the primary objectives of the National Strategic Computing Initiative (NSCI): “Increasing coherence between the technology base used for modeling and simulation and that used for data analytic computing.”
Beckman maintains that these two worlds need to come together to solve bigger and more exciting science problems, and the base technologies themselves are becoming more closely related. “The convergence is happening,” he says.
The extreme-scale computing community, represented by the top 30-40 systems on the TOP500 list, has been singularly focused on extreme simulation and modeling and computing, very often to the exclusion of other communities and technologies, Beckman notes.
“What we’re finding, what the world is finding, is that the big data community, which also has extremely rich problems and exciting problems in correlating massive amounts of data from astronomy, from genomics, and other areas, has very similar needs to the HPC community, but it’s not currently exactly aligned. So these communities sometimes have to build their own infrastructure or develop their own infrastructure that maybe doesn’t run or isn’t supported easily on the HPC software stack and also with respect to the HPC architecture, the actual hardware, architecture and arrangement of components,” he says.
The divide between these two ecosystems is nicely illustrated in the following slide from a presentation that Beckman delivered with Dan Reed of the University of Iowa at the SC15 BDEC workshop.
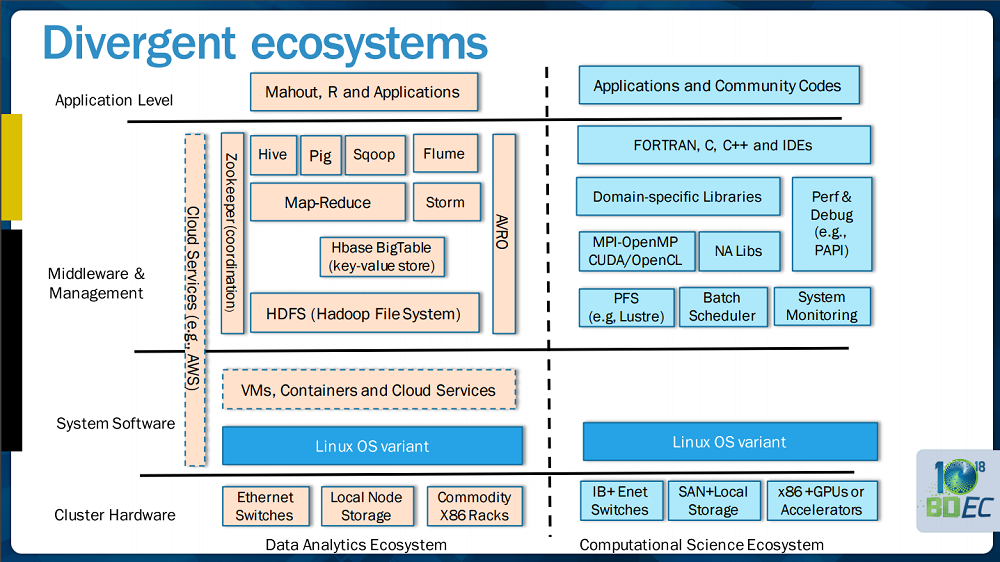
On the left side is represented a whole set of technologies that the big data analysis community has embraced, but can appear as “strange words” to the HPCers, says Beckman.
“Not only do they not make sense to the HPC community, they also require operationally a different way to use the system,” Beckman expounds. “So while the HPC community, for example, is very comfortable submitting a large-scale simulation and expecting it will take eight hours or longer before it starts, the analysis community expects to be able to load very large databases into scalable systems and then make queries all day long, 24/7 all year.”
A question posed on the next slide drives home the dichotomy: “Have you ever requested compute and storage for years of continuous data analysis?”
“That just runs contrary to the way we currently imagine the top ten systems in the world,” says Beckman. “No one expects ten percent of a big machine like that to be given over to continuous database queries on climate data or on astronomy data or on genomics data. What we’re finding is that the low level — and this is where we get into Argo — that there are several places where convergence can happen. There really can be a set of software tools and operating system pieces and schedulers and cloud support that can assist both communities, and that is where we are going — that’s the future.”
Argo is an exascale-focused operating system framework that is being designed from the ground up to support the emerging and future needs of both communities. The project aims to strike a balance between reusing software stack components where it makes sense and adding custom efforts when it matters. “At the heart of our project, at the node, we’re leveraging Linux components, and then adding in those pieces of technology that high-performance computing applications need: special kinds of high-performance computing containers, special kinds of power management components that allow us to adjust the electrical power on each node so that we stay within a power budget, and ways to think about concurrency and millions and millions of lightweight threads.”
There are two dominant drivers pushing these worlds together. One is the cost savings. Labs and their funding bodies in the US and abroad can no longer afford to “pay twice” for the components and technology. Further, as Beckman points out, there are also very good technical reasons to enable both kinds of workloads and workflows on the same system. “We save time and improve capability by being able to do both large-data analysis and simulations simultaneously to solve a big scientific problem,” he says.
“This divergent ecosystem view is what we’re observing in BDEC and is what we believe will be changed in the future,” adds Beckman. “We’ll move to a converged software and hardware architecture that allows scientists to do both.”
To be clear here, what is required to align the two ecosystems, and it’s already underway, is the move from a razor thin operating system to a more fully-featured one. This is a cusp moment when increasingly high performance computing applications are wanting something more, says Beckman. For example, they want to run a background data compression at the same time as they run their application or they want to run some data analysis during application and do in-situ visualization during their application.
“Suddenly the application community is saying, we want an operating system that has important features and can create containers for our workflow components and can manage NVRAM in interesting ways because our new systems all have embedded NVRAM and can do interesting compression and data reduction because our bandwidth to I/O is less that we would like,” says Beckman.
“All of the sudden we are back in the situation where we need a robust high performance operating system that extends what you find [in a standard Linux distro] and provides special features for high performance computing. We’re back into the space where vendors and applications and the community all want to be able to support very rich applications and that’s exactly what the big data community needs as well.”
The logical question here is what do you trade if you have a feature that you don’t use? If you only require the operating system to hand over the memory, and the extra functionality is just sitting there, do you pay for that functionality even if your application doesn’t use it? There’s been a lot of research into this question, Beckman tells me, and most of it has shown that that cost is really quite small. “If an application chooses not to use these advanced features, the fact that the system carries support for it doesn’t really slow the application down much, if at all,” he affirms.
Docker and other container technologies are helping to usher in this new era. The overhead that held back HPC adoption of virtualization (and VM-style cloud computing) is virtually non-existent with the container approach, opening up a whole world of possibilities for the flexible use of systems beyond the minimalist’s bare metal. “What they provide,” says Beckman of these newer lightweight frameworks, “is this very rich programming environment, which makes applications more productive and makes it possible for people to string together very complex workflows.”
Beckman acknowledges the existence of what he says is “a pretty small community” of dissenters who continue to uphold the ideal of a pared-down OS and just want to run their one thing. He believes this viewpoint holds less sway as science domains broadly become more intertwined.
Beckman points to battery storage as an example. In this one domain, there is chemistry at the quantum level happening in the battery; materials questions about how long the actual physical components – the cathode, the anode — can last and how they corrode; and the issue of having this battery in a car and what happens in the event of a crash or fire.
“These are all science questions across multiple scales, all the way from quantum, what’s happening in the chemistry of the battery, up to the collision of one car into another,” says Beckman, “So just solving one science problem where one community says all I want to do is quantum chemistry for my battery sort of misses the bigger picture. We actually have to be able to solve the big data problems. We have to solve simulations that do collision dynamics between cars; we have to solve material aging problems. So we need software stacks that are very rich and very feature-full to provide support for these communities. And when they don’t get that support, they go work on other things. They go design their own computer systems and software stacks.
“We need to understand that our science problems are part of larger whole that we have to solve. Bringing together more tools and more system software facilitates this.”

























































