 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
The high performance computing market is going through a technology transition – the Co-Design transition. As has already been discussed in many articles, this transition has emerged in order to solve the performance bottlenecks of today’s infrastructures and applications, performance bottlenecks that were created by multi-core CPUs and the existing CPU-centric system architecture.
How are multi-core CPUs the source for today’s performance bottlenecks? In order to understand that, we need to go back in time to the era of single-core CPUs. Back then, performance gains came from increases in CPU frequency and from the reduction of networking functions (network adapter and switches). Each new generation of product brought faster CPUs and lower-latency network adapters and switches, and that combination was the main performance factor. But this could not continue forever. The CPU frequency could not be increased any more due to power limitations, and instead of increasing the speed of the application process, we began using more CPU cores in parallel, thereby executing more processes at the same time. This enabled us to continue improving application performance, not by running faster, but by running more at the same time.
This new paradigm of increasing the amount of CPU cores dramatically increased the burden on the interconnect, and, moreover, changed the interconnect into the main performance enabler of the system. The key performance concern was how fast all the CPU processes could be synchronized and how fast data could be aggregated and distributed between them.
But the native interconnect latency has also reached the point of being exceedingly small compared to the overall communication patter. Today, InfiniBand switches runs at 90 nanosecond latency and InfiniBand adapters at 100 nanosecond latency. For CPU process communication frameworks, such as MPI collective communications, latency is in the range of tens of microseconds. Even if we continue to see reduction in the interconnect latency of another 10, 20, 40, or 50 nanoseconds, this is clearly negligible compared to the process communication latency. That means that the idea that has been suggested by certain companies to merge the network adapter with the CPU in order to reduce a few nanoseconds is certainly not the right thing for the future of HPC.
It is fair to ask whether this is relevant to the debate between offloading and onloading. The answer is that it is very relevant. In the past, the debate between offloading and onloading was mainly centered around CPU efficiency. An offloading interconnect technology was more complex to design and build, but in return, it offloaded the CPU from managing network activities, which could easily result in 40-50 percent better CPU and system utilization. The onloading interconnect technology is easier to build, but it is nothing more than a simple pipe, and all the network operations still must be managed and executed by the CPU; half of the CPU’s time is wasted from the point of the application. Furthermore, offloading enables technologies like RDMA, which cannot be done with an onloading approach. We have therefore witnessed numerous application performance examples that demonstrate the clear and dominant advantage of offloading solutions over onloading products (for example, DDR InfiniBand vs. Pathscale InfiniPath and QDR InfiniBand vs. QLogic/Intel TrueScale) [see i, ii, and iii].
Nowadays, the offloading architecture has become the critical element in overcoming performance bottlenecks, and it is not just a matter of performance and cost/performance comparisons. Systems cannot continue to scale unless intelligent interconnect and offloading are used.
As the number of processes continues to grow, one can increase the parallelism of solving the complex problems we deal with in science, research, and manufacturing. Therefore, the process communications become more and more critical. It is more than just the network latency of ping pong operations, but also the communication latency of complex, critical communications – collective operations or data aggregation operations. Executing these operations on the CPU/node has reach its performance limit and cannot be accelerated any further. The only solution is actually to perform these operations on the data while its moves within the cluster; that is, they are executed by the interconnect functions (switch, adapter) as the data moves. This approach, which was developed under the global architecture of Co-Design, will take us farther down the path toward exascale computing.
This technology trend will not affect only HPC, but rather will change the world of data analytics, machine learning, and other data-intensive applications and data search-based applications. The CPU core parallelism that saved the day in the mid-2000s has become the bottleneck today, and the new intelligent offloading interconnect solutions are the new saviors. Intelligent interconnect solutions are becoming the new co-processors, and they are therefore becoming a key factor for scalable computing.
Going back to basic application performance and system return on investment, it is expected that the comparison between EDR InfiniBand and Intel Omni-Path would be similar to the previous comparisons between the two different interconnect technology approaches. While only very small setups are available today, one can already see the system performance difference in various HPC application cases, for example WIEN2K, Quantum Espresso, and LS-DYNA.
WIEN2k allows users to perform electronic structure calculations of solids using density functional theory. It is an all-electron scheme including relativistic effects and has been licensed by more than 2000 user groups. Quantum Espresso is an integrated suite of Open Source computer codes for electronic structure calculations and materials modeling at the nanoscale. It is based on density functional theory, plane waves, and pseudopotentials. LS-DYNA is an advanced general-purpose multiphysics simulation software package developed by the Livermore Software Technology Corporation (LSTC). While the package continues to contain ever more possibilities for the calculation of complex, real world problems, its origins and core-competency lie in highly non-linear transient dynamic finite element analysis (FEA) using explicit time integration. LS-DYNA is used by the automotive, aerospace, construction, military, manufacturing, and bioengineering industries.
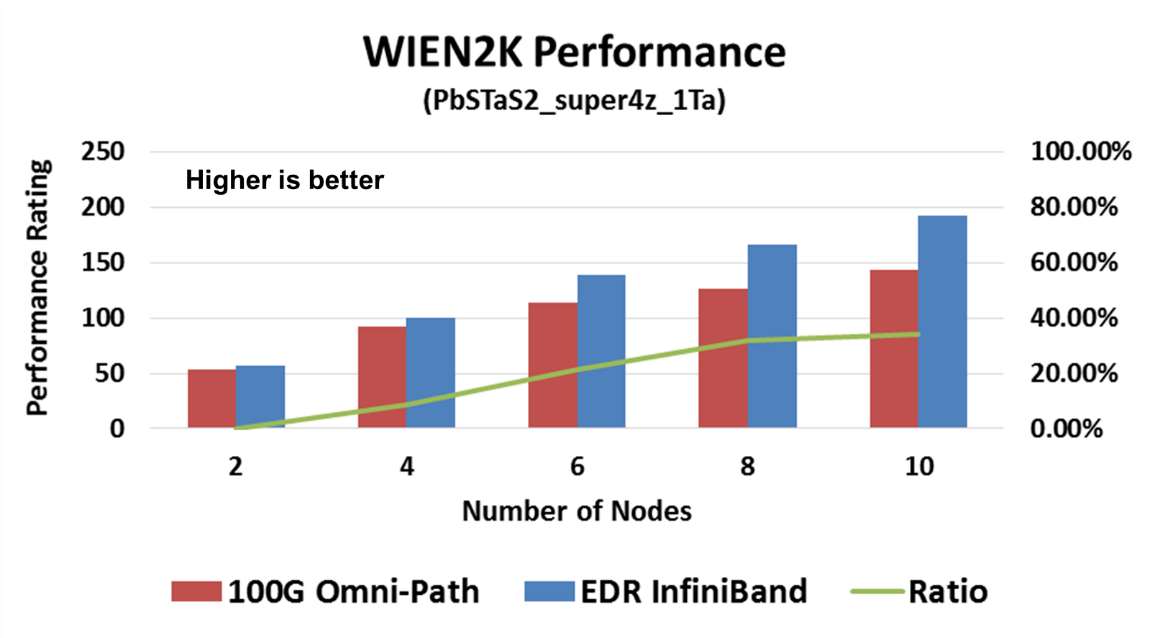
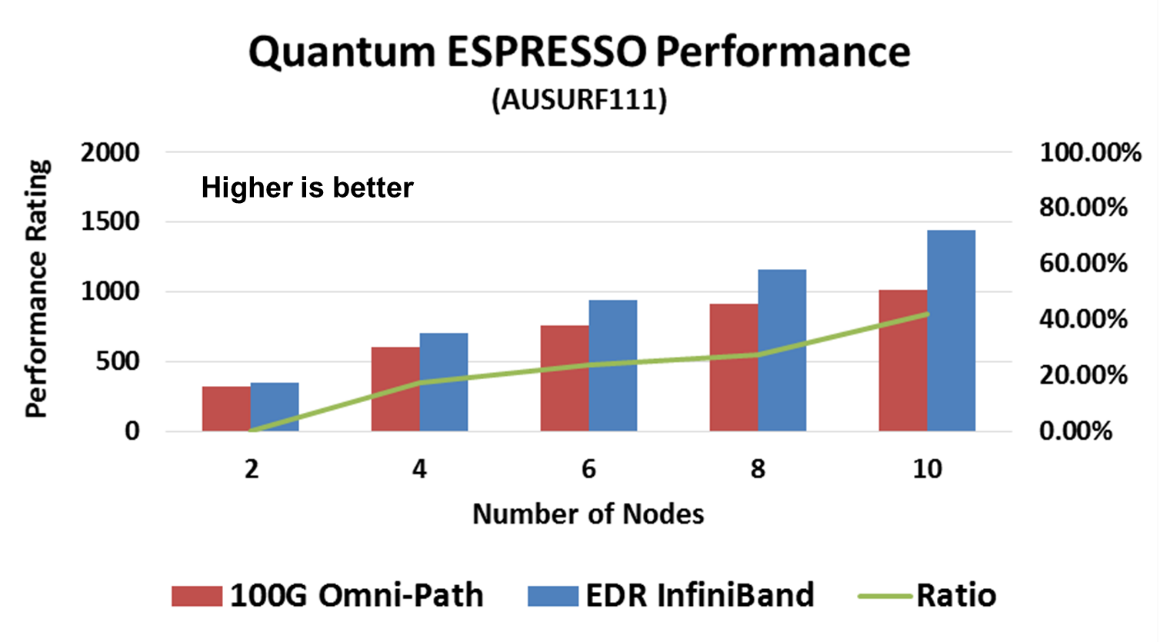
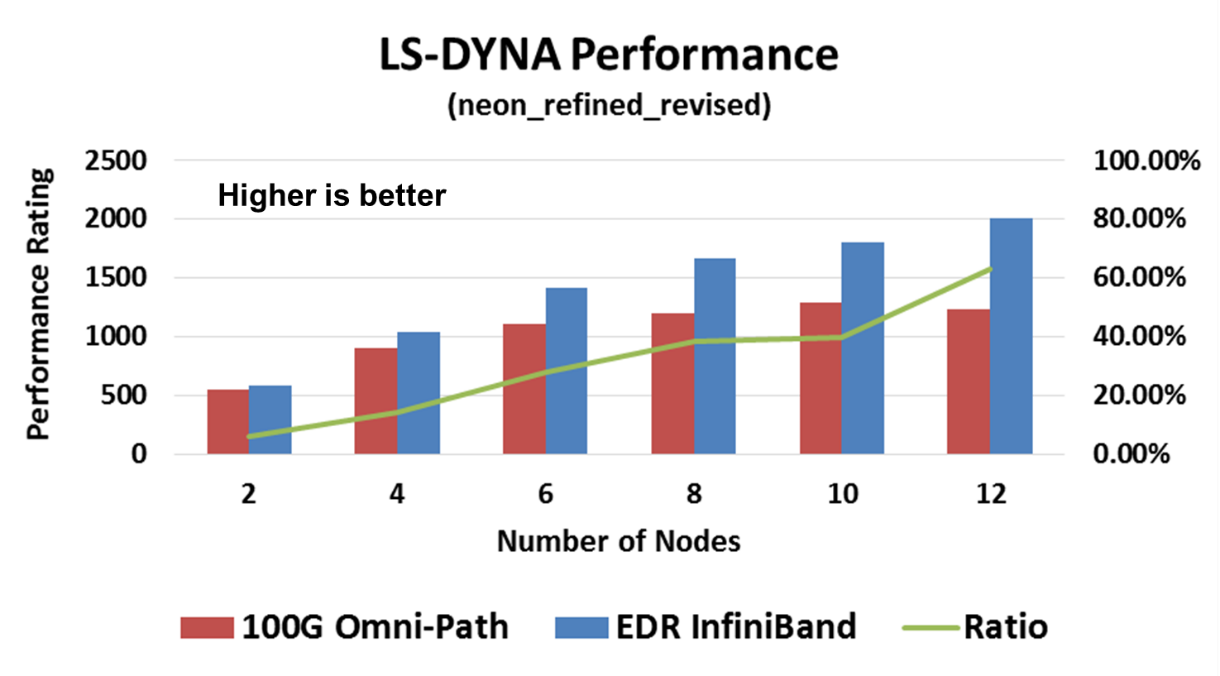
In all three cases, we can see a clear performance advantage of the EDR InfiniBand smart network. It should be noted that the performance difference is of the entire system, ranging from 35% to 63% higher system performance with InfiniBand. It should also be noted that the system scale for these tests is small, and the gap will increase with system size.
Furthermore, as can be seen in the LS-DYNA case, for example, InfiniBand enables higher performance with only six nodes, versus Omni-Path on 12 nodes – InfiniBand delivers higher performance with half of the system size versus Omni-Path.
The system performance difference with smart offloading interconnect is clear, and the case of InfiniBand vs. Omni-Path is no different.
References
[i] http://ieeexplore.ieee.org/xpl/login.jsp?tp=&arnumber=5613096&url=http%3A%2F%2Fieeexplore.ieee.org%2Fxpls%2Fabs_all.jsp%3Farnumber%3D5613096
[ii] http://www.dynalook.com/european-conf-2007/ls-dyna-performance-and-scalability-in-the-multi.pdf
[iii] http://www.eetimes.com/document.asp?doc_id=1278292&page_number=2
























































