 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Nielsen has collaborated with Intel to migrate important pieces of HPC technology into Nielsen’s big-data analytic workflows including MPI, mature numerical libraries from NAG (the Numerical Algorithms Group), as well as custom C++ analytic codes. This complementary hybrid approach integrates the benefits of Hadoop data management and workflow scheduling with an extensive pool of HPC tools and C/C++ capabilities for analytic applications. In particular, the use of MPI reduces latency, permits reuse of the Hadoop servers, and co-locates the MPI applications close to the data.
John Mansour, vice president, Advanced Solutions Group, at Nielsen became interested in the integration of both Hadoop and HPC technology to enable faster, better, and more powerful analysis of the huge volumes of data collected by Nielsen as part of their Consumer Package Goods (CPG) market research. Nielsen is well-known for the ‘Nielsen ratings’ of audience measurement in Television, Radio, and online content. The company also provides Retail Measurement Services (RMS) that track and report on CPG sales around the world to understand sales performance. The success of Nielsen’s efforts are presented in his talk Bridging the Worlds of HPC and Big-Data at Supercomputing 2015.
Nielsen already utilizes the Cloudera Hadoop infrastructure to ingest and manage a daily deluge of data used in their market research. What Nielsen wanted was to make this infrastructure HPC-friendly so the wealth of scientific and data-analytic HPC codes created since the 1960s could be added to the Nielsen set of computational tools. This required integrating MPI (Message Passing Interface), which is the distributed framework utilized by the HPC community, into the Cloudera Hadoop framework. This integration allows Nielsen the choice of using C/C++ MPI in addition to Spark and Map-Reduce for situations that either require the performance or are a team’s preferred language.
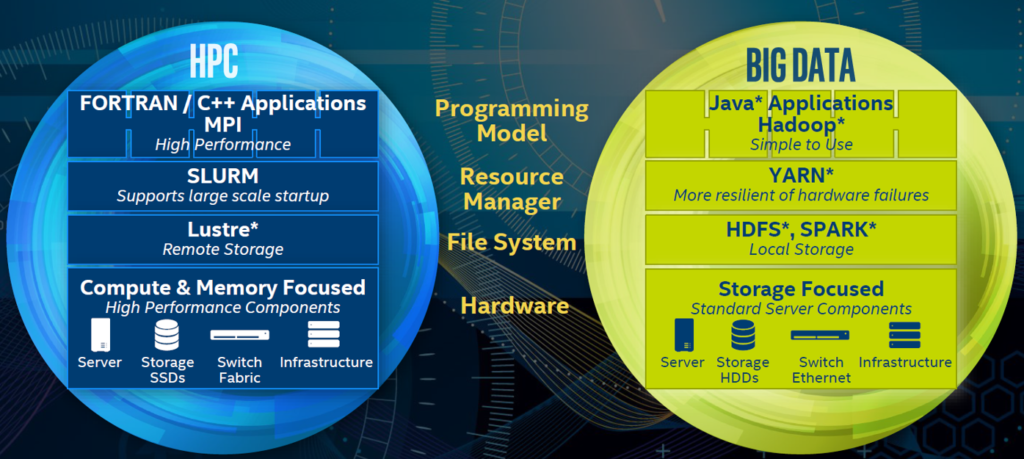
MPI has been designed and refined since the 1990s to remove as much of the communications overhead from distributed HPC applications as possible, while Hadoop and the cloud computing infrastructure in general has been designed to run in a big-way on COTS (Commodity Off The Shelf) hardware where fault- and latency-tolerance is a requirement. A successful integration of the two means that existing MPI and data analytic codes can be ported without having to be re-implemented in another language such as SPARK, and very importantly, the integration can occur without affecting existing operational cloud infrastructure.
The integration, performed in collaboration with Intel, is quite straight-forward from a high-level perspective: simply start a python script that requests resources based on a set of input parameters and writes out a machine file that can be utilized by mpiexec to run the MPI job. The script then starts the MPI run and cleans up resources upon completion.
In actuality, the process is more complicated as it is necessary to ensure the data is in the right place and that errors are correctly handled. Nielsen uses Cloudera’s llama as the application master and yarn as the resource manager.
The performance of MPI in the Nielsen Hadoop framework has been superb and is expected to get even better. In testing with other Hadoop technologies, Nielsen has found MPI to consistently perform better than the others. Speedups come from the use of C/C++, sophisticated numerical libraries such as those offered by the NAG Numerical Algorithms Group and MPI’s design for low-latency communications which help in tightly coupled communications such the reduction operations needed in regressions and machine learning applications. In a future publication Nielsen will provide more detailed performance comparisons but typically see about a factor of between 5 to 10 times in performance compared to SPARK 1.5.1.
All this work to date has been at the proof-of-concept (POC) phase. In particular, high-performance storage I/O has proven to be an issue with significant amounts of runtime – sometimes as much as 85% – being consumed by the data loads. The challenge is that HDFS, which is written in Java, appears to be a bottleneck. Nielsen is experimenting with different technologies including local file systems and new apis such as RecordService and libhdfs3. Unfortunately, there are issues using common MPI data methods like mpiio which present a problem in Hadoop.
In addition to optimizing I/O performance, Nielsen has demonstrated significant performance benefits preloading data into distributed shared memory using BOOST shared memory STL vectors. With a working MPI and ability to integrate existing C/C++ codes, Nielsen has opened the door to a wealth of computational tools and analytic packages. In particular, the NAG library is a well-known, highly-regarded numerical toolkit. For example, NAG offers routines for data cleaning (including imputation and outlier detection), data transformations (scaling, principal component analysis), clustering, classification, regression models and machine learning methods (neural networks, radial basis function, decision trees, nearest neighbors), and association rules plus a plethora of utility functions.
Author Bio:
Rob Farber is a global technology consultant and author with an extensive background in scientific and commercial HPC plus a long history of working with national labs and corporations. He can be reached at [email protected].


























































