 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Programmability and portability problems have long inhibited broader use of FPGA technology. FPGAs are already widely and effectively used in many dedicated applications (accelerated packet processing, for example), but generally not in situations that require ‘reconfiguring’ the FPGA to accommodate different applications. A group of researchers from Oak Ridge National Laboratory is hoping to change that.
Presenting at the 30th IEEE International Parallel & Distributed Processing Symposium (IPDPS) being held this week in Chicago, the group will discuss their work which is described in a new paper – OpenACC to FPGA: A Framework for Directive-based High-Performance Reconfigurable Computing. The authors include Seyong Lee, Jungwon Kim, and Jeffrey S. Vetter, all of ORNL.
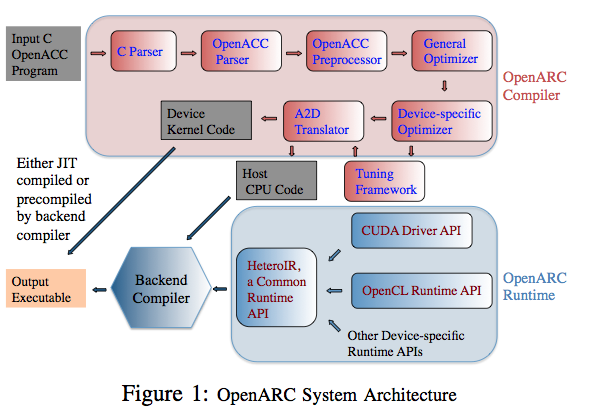
Their directive-based, high-level programming framework takes a standard, portable OpenACC C program as input and generates a hardware configuration file for execution on FPGAs. “We implemented this prototype system using our open-source OpenARC compiler; it performs source-to-source translation and optimization of the input OpenACC program into an OpenCL code, which is further compiled into a FPGA program by the backend Altera Offline OpenCL compiler,” write the authors.
Solving, or at least significantly mitigating, FPGA’s nagging performance and portability issues could open the door for their use us in many different computing environments. The paper singles out exascale computing noting that future exascale supercomputers will need to satisfy numerous criteria: high performance on mission applications, wide flexibility to serve a diverse application workload, efficient power usage, effective reliability, and reasonable cost.
Heterogeneous computing with GPUs and Xeon Phis acceleration is currently the most popular approach to achieving exascale. “However, these exascale architectural criteria must be balanced against the user-driven goals of portable, productive development of software and applications, because many applications, such as climate model simulations, undergo frequent improvement and must execute on dozens of different architectures over their lifetimes. Consequently, some scientists have opted to postpone porting their applications to these heterogeneous architectures until portable programming solutions exist,” they contend.
 FPGAs could have a role to play. They offer many substantial advantages, including performance and energy efficiency for specific workloads relative to these other heterogeneous systems. In fact, say the authors, “chips, primarily from Xilinx and Altera, are often at the forefront of technology available on the market, using the latest process feature sizes, highest performance I/O and transceivers, and most effective memory subsystems. Furthermore, manufacturers offer these reconfigurable systems, such as the Altera Arria 10, in a wide array of configurations that include the tight integration of their custom reconfigurable logic with hard IP processors (e.g., ARM Cortex-A9) into a System- on-a-Chip (SoC).”
FPGAs could have a role to play. They offer many substantial advantages, including performance and energy efficiency for specific workloads relative to these other heterogeneous systems. In fact, say the authors, “chips, primarily from Xilinx and Altera, are often at the forefront of technology available on the market, using the latest process feature sizes, highest performance I/O and transceivers, and most effective memory subsystems. Furthermore, manufacturers offer these reconfigurable systems, such as the Altera Arria 10, in a wide array of configurations that include the tight integration of their custom reconfigurable logic with hard IP processors (e.g., ARM Cortex-A9) into a System- on-a-Chip (SoC).”
To a considerable extent the use of FPGA has been restricted mainly to hardware programmers. This is primarily because programming FPGAs requires substantial knowledge about the underlying hardware and writing applications in very low-level Hardware Description Languages (HDLs), such as VHDL and Verilog. Ultimately, an FPGA programmer had to design algorithms at the Register Transfer Level (RTL) level by describing them using state machines, arbitration, data paths, interfaces to external memory, buffering, etc.
An effective and easy to use high-level programming framework, based on an open source standard, could be a significant game-changer. In the evaluating their new framework, the group used an Altera Stratix V FPGA (57K logic elements, 172,600 ALMs, 690K register, 2,014 M20K memory blocks, and 8GB DDR3 device memory). Eight OpenACC benchmarks were run to demonstrate the benefits of the strategy.
To show the portability of OpenARC, the same benchmarks were run on other heterogeneous platforms, including NVIDIA GPUs, AMD GPUs, and Intel Xeon Phis. “This initial evidence helps support the goal of using a directive-based, high-level programming strategy for performance portability across heterogeneous HPC architectures,” conclude the authors.
The authors note many projects have explored the complexity of mapping source- code-level control and data to FPGAs. However, the additional complexity of synthesizing the logic and balancing the flexible resources offered by the FPGA with those requested by the application often requires an iterative approach, which can lead to long compilation delays and additional complexity.
Introduction of OpenCL was one effort to cope with the problem; its higher level of abstraction hides some of the FPGA programming complexity and enhances portability. Nevertheless, many users still consider the OpenCL programming system as too low of a level of abstraction for their large, complex applications. The paper is quite thorough, identifies and briefly discussers several other efforts intended to ease FPGA programming and portability
Other approaches cited include: “The SRC platforms enables users to program the FPGA effectively with Fortran and C. Handel-C is a subset of C language proposed for C-to-FPGA translation. The Impulse C-to-FPGA compiler translates C language to HDL. Xilinx Vivado (previously AutoPilot) supports compilation from a behavioral description written in C/C++/System C to VHDL/Verilog RTL. Papakonstantinou et al. propose a compiler framework, called FCUDA, which translates CUDA to Xilinx AutoPilot code for FPGA. Programming FPGAs with these high-level languages helped to relieve programmers from the complex details of the RTL design, such as taking care of synthesis, place and route, timing closures, etc.”
The authors cite what they believe are the three most noteworthy aspects of their work, excerpted here:
- “We design and implement an OpenACC-to-FPGA translation framework. To best our knowledge, this is the first work to use a standard and portable directive-based, high-level programming system for FPGAs.
- We propose several FPGA-specific OpenACC compiler optimizations and novel pragma extensions to improve performance.
- We empirically evaluate our OpenACC-to-FPGA compiler framework using eight OpenACC benchmark applications. We show the performance variations with respect to the online and/or offline configurations using Altera FPGA, and demonstrate the portability of our OpenARC system running the same applications on NVIDIA GPU, AMD GPU, and Intel Xeon Phi.”
The authors argue that their preliminary evaluation of the OpenACC benchmarks on an FPGA and a comparison study on GPUs and a Xeon Phi show that the unique capability of an FPGA to generate custom hardware units dedicated to an input program offers a lot of performance tuning opportunities, different from other accelerators. Moreover, “the reconfigurability of existing hardware resources in the FPGA architecture exposes a new type of tradeoffs between the hardware resources versus throughput, such as compute unit replication, kernel vectorization, resource sharing, heterogeneous memory support, loop unrolling, streaming [and] channels.”
They suggest future work should explore using these features to exploit high-performance reconfigurable computing as a possible energy-efficient HPC solution.
The talk will be included in the Proceedings for IPDPS 2016 & IPDPSW 2016 Online (http://www.ipdps.org/ipdps2016/2016_online_proceedings.html.) DOE will also provide public access to these results (http://energy.gov/downloads/doe- public-access-plan.)

























































