 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
One of the primary conversations these days in the field of networking is whether it is better to onload network functions onto the CPU or better to offload these functions to the interconnect hardware.
Onloading interconnect technology is easier to build, but the issue becomes the CPU utilization; because the CPU must manage and execute network operations, it has less availability for applications, which is its primary purpose.
Offloading, on the other hand, seeks to overcome performance bottlenecks in the CPU by performing the network functions, as well as complex communications operations, such as collective operations or data aggregation operations, on the data while it moves within the cluster. Data is so distributed these days that a performance bottleneck is created by waiting for data to reach the CPU for analysis. Instead, data can be manipulated wherever it is located within the network by using intelligent network devices that offload functions from the CPU. This has the added advantage of increasing the availability of the CPU for compute functions, improving the overall efficiency of the system.
The issue of CPU utilization is one of the primary points of contention between the two options. How you measure CPU utilization and what type of benchmark you use for the test can provide highly misleading results.
For example, a common mistake is to use a common latency test or message rate test to determine the CPU utilization; however these tests typically require the CPU to constantly look for data (that is, polling data on the memory), which makes it seem as though the CPU is at 100 percent utilization, when actually it is not working at all. Using such a test to determine CPU utilization will produce a false result. In the real world, CPUs do not constantly check for data.
So what is the proper way to measure CPU utilization? Ideally, a data bandwidth test or another test that does not use data polling can be used to determine CPU utilization. Alternatively, if a message rate test is used, the test must be configured to avoid data polling loops in order to produce realistic results. Ultimately, the best option is to compare the number of CPU instructions that were actually executed against the number of CPU instructions that could possibly have been executed during the duration of the test. This produces an accurate percentage of CPU utilization.
Another important element to consider is the type of overhead that is being measured. For example, if the test is designed to measure the impact of the network protocol on CPU utilization, the test should only test data transfers between two servers, and not include additional overheads such as MPI, which is in the software layer. If the purpose is to measure the overhead of a software framework, such as MPI, an MPI test should be used, but in that case, the proper MPIs with the proper offloads must be used, if they exist. Not all MPIs support various hardware-based offloads, so it is important to beware of the test conditions.
So now that it’s clear how to measure CPU utilization accurately, the question remains: Which is better, offloading or onloading? We have conducted multiple data throughput tests between servers connected with EDR InfiniBand and the proprietary Omni-Path alternative.
The tests included send-receive data transfers at the maximum data speed supported by each interconnect (~100Gb/s) while measuring the CPU utilization (Table 1). At the data speed of 100Gb/s, InfiniBand only consumed 0.8 percent CPU utilization, while Omni-Path required 59 percent CPU utilization for the same task. Therefore, the CPU availability for the application in the InfiniBand case is 99.2 percent, while for Omni-Path, only 40.4 percent of the CPU cycles are available for applications. Furthermore, we have measured the CPU frequency in each of the cases, since the CPU can reduce its frequency to save power when it is not required to perform at full speed. For the InfiniBand case, the CPU frequency was able to drop to 59 percent of is nominal frequency to enable power saving. For the Omni-Path case, on the other hand, the CPU was performing at full speed, so no power saving could be achieved.
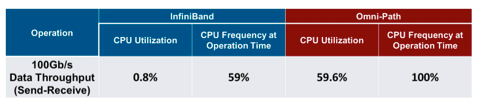
Table 1 – CPU Utilization Comparison
The tool that was used to review the CPU stats was the Intel Performance Counter Monitor toolset. The tool provides a richer set of measurements that provide a detailed system status. Utilizing this tool, we found that Omni-Path did not actually reach the 100G speed, but fell a little short at 95Gb/s. The AFREQ stats reported the CPU frequency that was dynamically set during the test. We were also able to view the number of iterations and active cycles used per the different interconnect protocols (Table 2).

Table 2 – Intel Performance Counter Monitor Tool stats
Moreover, when InfiniBand is implemented on intelligent devices within the Co-Design architecture, it can further reduce overhead on the CPU by offloading MPI operations as well. Of course, to measure this, the test must be sure to include the software layer in the benchmark such that an accurate real-world result is received. We plan to perform various further tests at different applications levels in the future to demonstrate the significant advantages of InfiniBand.
Ultimately, InfiniBand implements offloading specifically in order to reduce the overhead on the CPU, and, as the testing herein indicates, it works exactly as it was designed. If someone shows results that indicate otherwise, it is worthwhile to investigate the circumstances of the testing to better understand how the results were achieved. In all likelihood, the results are misleading and do not accurately reflect real-world conditions.

























































