 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
You may have heard the rumors, but now it’s official: China has built and deployed a 93 petaflops LINPACK (125 petaflops peak) Chinese-made supercomputer at its Wuxi Supercomputer Center, near Shanghai. A few days ago HPCwire received an advance copy of a report on the new system prepared by TOP500 author Jack Dongarra detailing the feeds and speeds and proffering perspective on its strengths and weaknesses.
Originally, Tianhe-2 was on deck to be China’s first 100-petaflopper based on a planned infusion of Intel Xeon Knights Landing CPUs. There was chatter that China could even be standing up two 100-petafloppers in time for the ISC TOP500 list publication, but the US embargo regulations restricting the sale of US processor technology into China pushed back the timeline. It was this trade restriction that spurred China to refocus efforts on its native chip technology. At the 12th Asian Connections workshop in Wuhan, China, in April, Beihang University Professor Depei Qian, who is helping steer the nation’s supercomputing roadmap as part of the 863 project, stressed the need for “self-controllable HPC technologies” on account of a “lesson learnt from the embargo regulation.”
During ISC 2016 this week, we expect more details on the fully-realized Tianhe-2 to be revealed as well as an update on the nation’s exascale plans now that Tianhe-3 has been named as the targeted first exascale system. (Recall that China has announced it will stand up an exaflops (peak) machine by 2020.)

The new machine, the Sunway TaihuLight system, achieved 93 petaflops out of a theoretical peak of 125 petaflops, giving it an efficiency of 74.51 percent. The run made use of 165,120 nodes using 1.2 PB total memory (7.2 TB of the memory of each node). The time to completion was 3.7 hours at an average power consumption of 15.37 MW. This gives it an energy efficiency of 6 gigaflops-per-watt, counting the processor, memory and interconnect network. The 28 MW cooling system from Climaveneta uses closed-coupled chilled water cooling with a customized liquid water-cooling unit.
As the new TOP500 champ, Sunway TaihuLight steals the top spot from Tianhe-2, which sat in the spot for three full years (and six list iterations), since China knocked the US Oak Ridge Titan machine off its perch in June 2013. Notably, China also stole list system share and performance share from the US (more on that to come).
The computational heart of Sunway TaihuLight is the SW26010 processor, which was designed by the Shanghai High Performance IC Design Center.
Each processor chip has four of these:
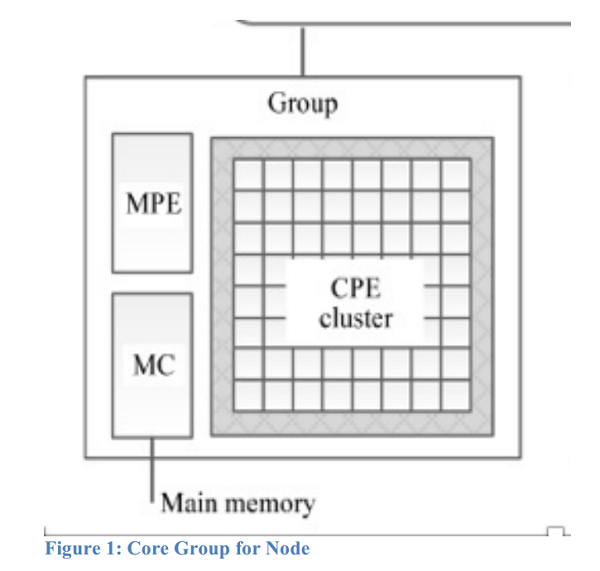
Which come together like this:
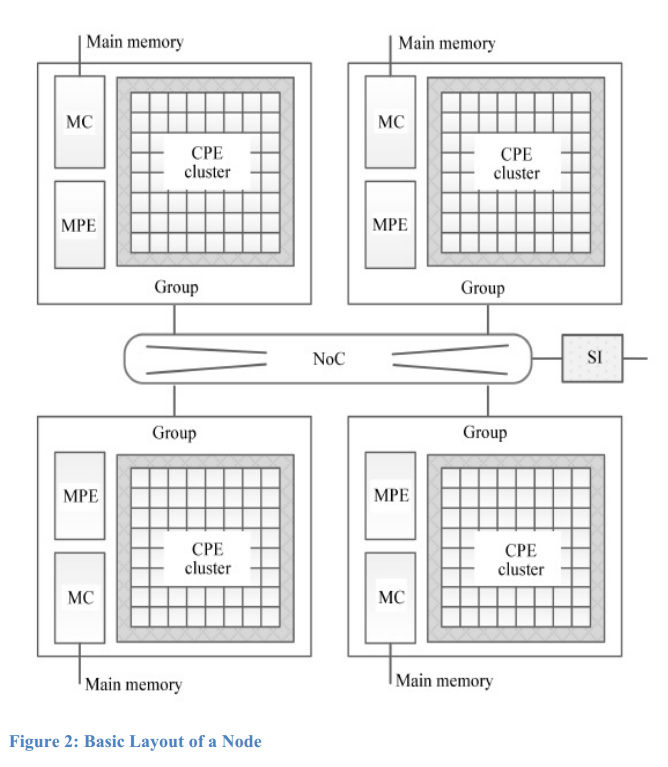
The first figure depicts one core group (CG) connected to a Network on Chip (NoC). Each CG is composed of a Management Processing Element (MPE) and 64 Computing Processing Elements (CPEs) arranged in an 8 by 8 grid.
The second figure shows the domestically-made multicore SW26010 processor (which is one compute node of Sunway); it consists of 4 CPEs and 4 MPEs for a total of 260 cores. There are 4 Memory Controllers (MC), and a Network on Chip (NoC), which is connected to the System Interface (SI). Each of the four MPE, CPE, and MC have access to 8GB of DDR3 memory. In the complete system, there are 40,960 nodes and 10,649,600 cores and 1.31 PB of memory.
As detailed in the report, “The MPE’s and CPE’s are based on a RISC architecture, 64-bit, SIMD, out of order microstructure. Both the MPE and the CPE participate in the user’s application. The MPE performance management, communication, and computation while the CPEs mainly perform computations. (The MPE can also participate in the computations.)”
It continues: “Each core of the CPE has a single floating point pipeline that can perform 8 flops per cycle per core (64-bit floating point arithmetic) and the MPE has a dual pipeline each of which can perform 8 flops per cycle per pipeline (64-bit floating point arithmetic). The cycle time for the cores is 1.45 GHz, so a CPE core has a peak performance of 8 flops/cycle * 1.45 GHz or 11.6 Gflop/s and a core of the MPE has a peak performance of 16 flops/cycle * 1.45 GHz or 23.2 Gflop/s. There is just one thread of execution per physical core.”
“The MPE’s and CPE’s are based on a RISC architecture, 64-bit, SIMD, out of order microstructure. Both the MPE and the CPE participate in the user’s application. The MPE performance management, communication, and computation while the CPEs mainly perform computations. (The MPE can also participate in the computations.)
The custom-built Sunway interconnect uses PCIe 3.0 connections between nodes as part of the Sunway Network. The network employs three different levels: the central switching network at the top, the super node network in the middle, and the resource sharing network at the bottom. The bisection network bandwidth is 70 TB/s, with a network diameter of 7. MPI communication between nodes is 12 GB/second with latency of around 1 us.
The complete system spans 40 cabinets, each with 4 Supernodes, which comprise 256 Nodes. Doing the multiplication, this comes out to 40,960 nodes total and 10,649,600 cores. Each node has a peak floating point performance of 3.06 teraflops.
The system software includes Sunway Raise OS 2.0.5 based on Linux as the operating system. Dongarra’s report also mentions basic compiler components, such as C/C++, and Fortran compilers, an automatic vectorization tool, and basic math libraries. Sunway OpenACC supports OpenACC 2.0
The Chinese supercomputing leadership is targeting the new Sunway machine at four key areas: advanced manufacturing (CAE, CFD), earth system modeling and weather forecasting; life science, and big data analytics.
China has been called out in the past for putting hardware ahead of software development. China announced that is has (at least) three applications that are on the finalist list for the Gordon Bell Award, which will be announced at SC16. The accepted submissions include a fully-implicit nonhydrostatic dynamic solver for cloud-resolving atmospheric simulation; a highly effective global surface wave numerical simulation with ultra-high resolution; and a large scale phase-field simulation for coarsening dynamics based on Cahn-Hilliard equation with degenerated mobility. The report from Dongarra notes that all three applications have scaled to about 8 million cores, just under 80 percent of the total system.
In his report on the system, Dongarra acknowledged the magnitude of the accomplishment, pointing out the significance of the 93 petaflops LINPACK reaching 74 percent of peak and achieving a 6 gigaflops-per-watt. “The Sunway TaihuLight is twice as fast and three times as efficient as the system it displaces in the number one spot,” he wrote. “The fact that there are sizeable applications and Gordon Bell contender applications running on the system is impressive and shows that the system is capable of running real applications and not just a stunt machine.”
However, as we know LINPACK does not tell the whole story. On the HPCG benchmark, Sunway TaihuLight reported only .371 petaflops, which is .3 percent of peak. Compare this with 0.580 petaflops on Tianhe-2 (1.1 percent of peak) and .322 petaflops on Titan (1.2 percent of peak). RIKEN’s K computer reports 0.460 HPCG performance, 4.1 percent theoretical peak.
“The HPCG performance at only 0.3% of peak performance shows the weakness of the architecture with slow memory and modest interconnect performance,” wrote Dongarra. “So for many “real” applications the performance will be no where near the peak performance rate.”
It’s a point the distinguished University of Tennessee professor has made before. At the 12th Asian Connections workshop, he cautioned that “peak and HPL may be very misleading” and that most applications will not achieve near this high-water mark.
There is also a question of China being behind the US in process technology. We are still waiting for that spec to be made public, but it was at one point expected that the next-generation Shenwei would be manufactured on 28-nm process technology. We will update that information as well as memory bandwidth and fabric I/O as it becomes available.
In concluding his report, Dongarra pointed to China’s strengths in standing up another number one system: “As the first top one system of China that is completely based on homegrown processors, the Sunway TaihuLight system demonstrates the significant progress that China has made in the domain of designing and manufacturing large-scale computation systems. The fact that there are sizeable applications and Gordon Bell contender applications running on the system is impressive and shows that the system is capable of running real applications and not just a stunt machine.”


























































