 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Greg Diamos, senior researcher, Silicon Valley AI Lab, Baidu, is on the front lines of the reinvigorated frontier of machine learning. Before joining Baidu, Diamos was in the employ of NVIDIA, first as a research scientist and then an architect (for the GPU streaming multiprocessor and the CUDA software). Given this background, it’s natural that Diamos’ research is focused on advancing breakthroughs in GPU-based deep learning. Ahead of the paper he is presenting, Diamos answered questions about his research and his vision for the future of machine learning.
HPCwire: How would you characterize the current era of machine learning?

Diamos: There are two strong forces in machine learning. One is big data, or the availability of massive data sets enabled by the growth of the internet. The other is deep learning, or the discovery of how to train very deep artificial neural networks effectively. The combination of these two forces is driving fast progress on many hard problems.
HPCwire: There’s a lot of excitement for deep learning – is it warranted and what would you say to those who say they aren’t on-board yet?
Diamos: It is warranted. Deep learning has already tremendously advanced the state of the art of real world problems in computer vision and speech recognition. Many problems in these domains and others that were previously considered too difficult are now within reach.
HPCwire: What’s the relationship between machine learning and high-performance computing and how is it evolving?
Diamos: The ability to train deep artificial neural networks effectively and the abundance of training data has pushed machine learning into a compute bound regime, even on the fastest machines in the world. We find ourselves in a situation where faster computers directly enable better application level performance, for example, better speech recognition accuracy.
HPCwire: So you’re presenting a paper at the 33rd International Conference on Machine Learning in New York today. The title is Persistent RNNs: Stashing Recurrent Weights On-Chip. First, can you explain what Recurrent Neural Networks are and what problems they solve?
Diamos: Recurrent neural networks are functions that transform sequences of data – for example, they can transform an audio signal into a transcript, or a sentence in English into a sentence in Chinese. They are similar to other deep artificial neural networks, with the key difference being that they operate on sequences (e.g. an audio signal of arbitrary length) instead of fixed sized data (e.g. an image of fixed dimensions).
 HPCwire: Can you provide an overview of your paper? What problem(s) did you set out to solve and what was achieved?
HPCwire: Can you provide an overview of your paper? What problem(s) did you set out to solve and what was achieved?
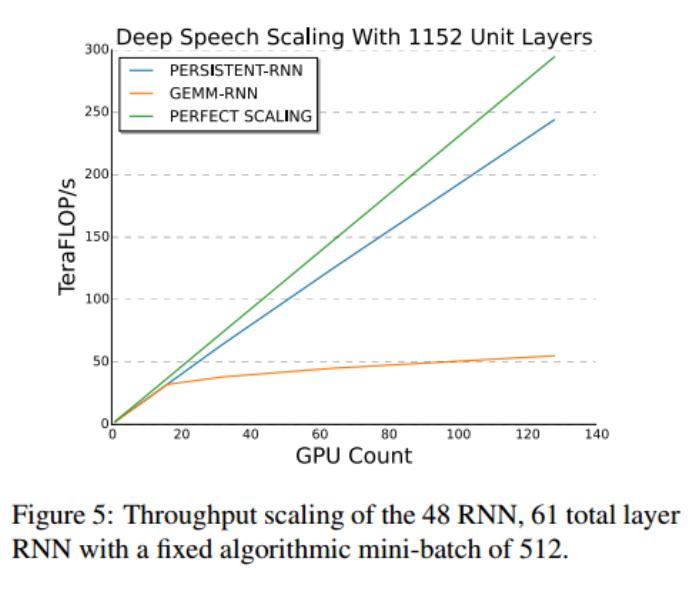
Diamos: It turns out that although deep learning algorithms are typically compute bound, we have not figured out how to train them at the theoretical limits of performance of large clusters, and there is a big opportunity remaining. The difference between the sustained performance of the fastest RNN training system that we know about at Baidu, and the theoretical peak performance of the fastest computer in the world is approximately 2500x.
The goal of this work is to improve the strong scalability of training deep recurrent neural networks in an attempt to close this gap. We do this by making GPUs 30x more efficient on smaller units of work, enabling better strong scaling. We achieve a 16x increase in strong scaling, going from 8 GPUs without our technique to 128 GPUs with it. Our implementation sustains 28 percent of peak floating point throughput at 128 GPUs over the entire training run, compared to 31 percent on a single GPU.
HPCwire: GPUs are closely associated with machine learning, especially deep neural networks. How important have GPUs been to your research and development at Baidu?
Diamos: GPUs are important for machine learning because they have high computational throughput, and much of machine learning, deep learning in particular, is compute limited.
HPCwire: And a related question – what does the scalability offered by dense servers all the way up to large clusters enable for deep learning and other machine learning workloads?
Diamos: Scaling training to large clusters enables training bigger neural networks on bigger datasets than are possible with any other technology.
HPCwire: What are you watching in terms of other processing architecture (Xeon Phi Knights Landing, FPGAs, ASICs, DSPs, ARM and so forth)?
Diamos: In the five year timeframe I am watching two things: peak floating point throughput and software support for deep learning. So far GPUs are leading both categories, but there is certainly room for competition. If other processors want to compete in this space, they need to be serious about software, in particular, releasing deep learning primitive libraries with simple C interfaces that achieve close to peak performance. Looking farther ahead to the limits of technology scaling, I hope that a processor is developed in the next two decades that enables deep learning model training at 10 PFLOP/s in 300 Watts, and 150 EFLOP/s in 25 MWatts.
HPCwire: Baidu is using machine learning for image recognition, speech recognition, the development of autonomous vehicles and more, what does the research you’ve done here help enable?
Diamos: This research allows us to train our models faster, which so far has translated into better application level performance, e.g. speech recognition accuracy. I think that this is an important message for people who work in high performance computing systems. It provides a clear link between the work that they do to build faster systems and our ability to apply machine learning to important problems.
Relevant links:
ICML paper: Persistent RNNs: Stashing Recurrent Weights On-Chip: http://jmlr.org/proceedings/papers/v48/diamos16.pdf
Video about Greg’s work at Baidu: https://www.youtube.com/watch?v=JkXbTOt_JxE























































