 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Steadily advancing neuromorphic computing technology has created high expectations for this fundamentally different approach to computing. Its strengths – like the human brain it attempts to mimic – are pattern recognition (space and time) and inference reasoning. Advocates say it will also be possible to compute at much lower power than current paradigms. At ISC this year Karlheinz Meier, a physicist-turned-neuromorphic computing pioneer and a leader of the European Human Brain Project (HBP), gave an overview that served as both an update and primer.
Moving to neuromorphic computing architectures, he believes, will make emulating brain function not only more effective and efficient, but also eventually accelerate computational learning and processing significantly beyond the speed of biological systems opening up new applications. Sometimes it’s best to start with the conclusions: Meier offered these summary bullets describing the state of neuromorphic computing today (not all covered in this article) at the end of his talk:
 After 10 years of development available hardware systems have reached a high degree of maturity, ready for non-expert use cases
After 10 years of development available hardware systems have reached a high degree of maturity, ready for non-expert use cases- High degree of configurability with dedicated software tools, but obviously no replacement for general purpose machines
- Only way to access multiple time scales present in large-scale neural systems, making them functional
- Well suited for stochastic inference computing
- Well suited for use of deep-submicron, non-CMOS devices
Meier is predictably bullish, citing the already proven power of deep learning and cognitive computing while still using traditional computer architectures by players like Google, Baidu, IBM, and Facebook. Indeed, computer-based neural networking isn’t new. It’s a mainstay in a wide variety of applications, typically assisted by one or another type of accelerator (GPU, FPGA, etc). Notably, NVIDIA launched its ‘purpose-built’ deep learning development server this year, basically an all GPU machine.
Many of these cognitive computing/deep learning efforts on traditional machines are quite impressive. Google’s AlphaGo algorithm from subsidiary DeepMind handily beat the world Go champion this year. But simply adapting neural networking to traditional to von Newmann architectures has drawbacks. One is power – not that it’s bad by conventional standards – but it shows no sign of the being able to approach the tiny 20W or so requirement for the human brain versus megawatts per year for supercomputers.
Also problematic is the time required to train networks. Talking about the AlphaGo victory, which he lauds, Meier said, “What people don’t see or what Google doesn’t tell people is that it took something like a year to train this system on a big cluster of graphic cards, certainly several hundred kilowatts of power over a very long time scale, many, many months. Of course the system looked at many Go games to discover the rules and structure and to play very well.”
Let’s acknowledge the training problem persists in neuromorphic computing as well. That said, neuromorphic, or brain inspired, computing seeks to mimic more directly how the human brain works. In the brain, neurons, the key components of brain processing, are connected in a vast network of networks. Individual neurons typically act in what’s called an integrate-and-fire fashion – that’s when the neuron’s membrane potential reaches a threshold and suddenly fires. Reaching that potential may involve numerous synaptic inputs that together sum to cross the firing threshold.
One of the staggering aspects of the brain is the range of physical size and ‘event’ durations it encompasses. In rough terms from tiny synapses to the whole brain there are seven orders of spatial magnitude, noted Meier, and in terms of time there are eleven orders of magnitude spanning activities from neuron firing to long-term learning. “Typically brains consist of neurons that spike and produce these kinds of action potentials, which are at the millisecond or sub millisecond level. And as you all know the time to learn things is months to years,” he said.
There have been successful efforts to map neural networks onto a supercomputer. One such effort on Japan’s K computer deployed a relatively simple network (~ one percent of the brain) and ran 1500X slower than the brain. This early work on the K computer by Markus Diesmann, another leader in European Human Brain Project (HPB), was the largest neural net simulation to date and an impressive achievement. However, it was a far cry from the efficiency (energy or processing capability) of the human brain.
 “You have to wait four years for a single simulated day. A day is nothing in the life of a brain. If you consider how you learn, real rewiring the structure of the brain, which takes many, many years at the beginning of your life, these time scales are inaccessible on conventional computers. And that will not change if you just go to exascale [on traditional architectures]. One of the ways out is neuromorphic computing,” he said. Neuromorphic architectures “aren’t doing numerical calculations but generic pattern recognition and discrimination processing just as the brain does.”
“You have to wait four years for a single simulated day. A day is nothing in the life of a brain. If you consider how you learn, real rewiring the structure of the brain, which takes many, many years at the beginning of your life, these time scales are inaccessible on conventional computers. And that will not change if you just go to exascale [on traditional architectures]. One of the ways out is neuromorphic computing,” he said. Neuromorphic architectures “aren’t doing numerical calculations but generic pattern recognition and discrimination processing just as the brain does.”
Three of the more prominent neuromorphic systems in operation today are:
- IBM’s TrueNorth uses the TrueNorth chip implemented in CMOS. Since memory, computation, and communication are handled in each of the 4096 neurosynaptic cores, TrueNorth circumvents the von-Neumann-architecture bottlenecks and is very energy-efficient, consuming 70 milliwatts, about 1/10,000th the power density of conventional microprocessors. This spring IBM announced a collaboration with Lawrence Livermore National Laboratory in which it will provide a scalable TrueNorth platform expected to process the equivalent of 16 million neurons and 4 billion synapses and consume the energy equivalent of a hearing aid battery – a mere 2.5 watts of power.
 The SpiNNaker project, run by Steve Furber, one of the inventors of the ARM architecture and a researcher at the University of Manchester, has roughly 500K arm processors. It’s a digital processor approach. The reason for selecting ARM, said Meier, is that ARM cores are cheap, at least if you make them very simple (integer operation). The challenge is to overcome scaling required. “Steve implemented a router on each of his chips, which is able to very efficiently communicate, action potentials called spikes, between individual arm processors,” said Meier. SpiNNaker’s bidirectional links to between chips is a distinguishing feature – think of it as a mini Internet, optimized to transmit ‘biological signal spikes, said Meier. The SpiNNaker architecture acts well as a real time simulator.
The SpiNNaker project, run by Steve Furber, one of the inventors of the ARM architecture and a researcher at the University of Manchester, has roughly 500K arm processors. It’s a digital processor approach. The reason for selecting ARM, said Meier, is that ARM cores are cheap, at least if you make them very simple (integer operation). The challenge is to overcome scaling required. “Steve implemented a router on each of his chips, which is able to very efficiently communicate, action potentials called spikes, between individual arm processors,” said Meier. SpiNNaker’s bidirectional links to between chips is a distinguishing feature – think of it as a mini Internet, optimized to transmit ‘biological signal spikes, said Meier. The SpiNNaker architecture acts well as a real time simulator.
- The BrainScaleS machine effort, led by Meier, “makes physical models of cell neurons and synapses. Of course we are not using a biological substrate. We use CMOS. Technically it’s a mixed CMOS signal approach. In reality is it pretty much how the real brain operates. The big thing is you can automatically scale this by adding synapses. When it is running you can change the parameters,” he said. It’s a local analogue computing approach with four million neurons and one billion synapses – binary, asynchronous communication.
Training the networks – basically programming an application – remains a challenge for all the machines. In essence, the problem and solutions become baked into the structure of the network with training. In the brain this occurs via synaptic plasticity in which the connections (synapses) between neurons are strengthened or weakened based on experience. Neuromorphic computing emulates learning and synaptic plasticity through a variety of techniques.
In his ISC presentation, Meier walked through three examples of neural networks and their training: deterministic supervised; deterministic unsupervised; and stochastic supervised.
“Most of the neural networks in use today are deterministic. You have an input and output pattern, and they are linked by the network – [in other words] if you repeat the experiment you will always get the same result. Of course the configuration of a network has to happen through learning,” said Meier. The supervision involves telling the computer, during learning, whether it has made a right or wrong choice.
You can also have stochastic networks: “You say that reality is a distributions of patterns. What you do in your networks is store a stochastic distribution of patterns, which reflect your prior knowledge, and which is acquired through learning. You can use those stored patterns either to generate distributions without any input or you can do inference,” he explained.
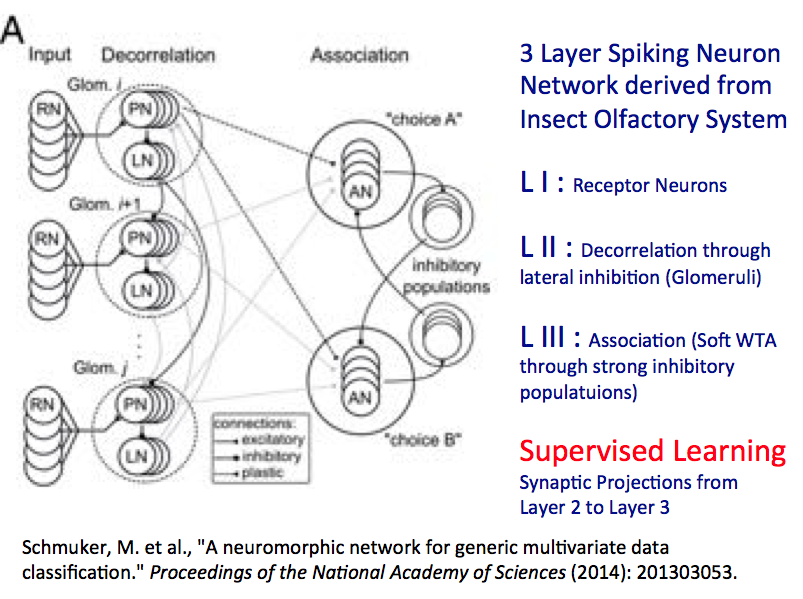 Deterministic Supervised Learning
Deterministic Supervised Learning
Taking an example from nature, Meier showed an instance of deterministic supervised learning in which a neural network mimics an insect’s natural ability to uses its chemical sensors to distinguish between different flowers. “These are circuits that we reverse engineered using neuroscience,” he explained. “We have receptor neurons that respond to certain chemical substances and you have a layer, called a de-correlation layer, which is basically contrast enhancement. You see that in all perceptive systems in biology. On the right side you see association layer to take combined inputs and make a decision based on what kind of flower you have,” said Meier.
It’s basically a data classification exercise. “The trick is to configure the links between those the de-correlation and association layers and this is done by supervised learning (telling the machine if it is correct or incorrect), through things like back propagation, Monte Carlo techniques, you really have to configure the synaptic link. Does it work? Actually it works very nicely,” said Meier.
As a general rule, he said, spiking activity is high at input layers but then drops markedly. “We see in the intermediate layer that connects association with the input layer, there is also spiking activity but it’s rare, it’s sparse. That’s a very important thing and may be one of the reasons nature has invented spikes because it saves energy. Where interesting computation is being done, the firing rate is sparse.”
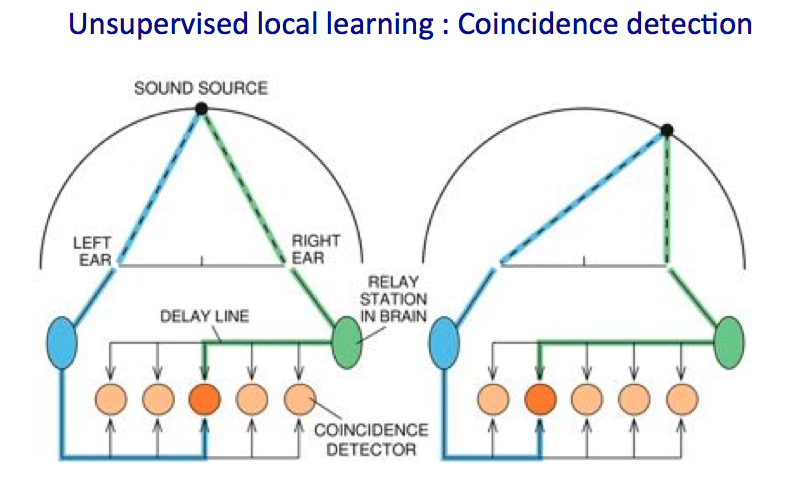 Deterministic Unsupervised Learning
Deterministic Unsupervised Learning
As an example of unsupervised deterministic learning, Meier reviewed how owls find prey in the dark. In biology the model is very straightforward. “Since the mouse is on the right side, it is a short flight path for the sound to right ear and a long path to the left ear. [Detecting this is] is done by a circuit encoding compensating for the short path in air by a long path in the brain. You depict the time coincidence between two input impulses to produce a stronger signal and that is done in a completely unsupervised way,” said Meier. This neural net is fairly straightforward to implement in hardware.
 Stochastic Supervised Learning
Stochastic Supervised Learning
Do you see a duck or a rabbit in the image shown here? It could be a duck or a rabbit but you only see one at a given moment.
“You have this stored distribution of probabilities in your brain and you take samples and jump between two options. This can be implemented with Boltzmann machines, in particular, with spiking Boltzmann machines. One of the machines has a network of symmetrically connected stochastic nodes where the stage of the nodes is described by a vector of binary random variables.”
If you are wondering how a spiking vector be a variable, Meier said, “We have developed a theory [in which] zeros and one are presented by neurons that is either active or in a refractory state. The probability that this network converges to a target is a Boltzmann distribution,” said Meier.
“Here of course it is a neural network where we are connecting weights between neurons. How do you train these things? There is a very well established mechanism where you clamp the visible unit of the input layer to the value of a particular pattern and then you weight the interaction between any two nodes. This is the learning process but it’s slow,” said Meier.
 While a great deal of progress in neuromorphic computing has been accomplished, thorny issues remain. For example, it’s still not clear what the base technology should be – CMOS chips, wafer scale lithographic ‘emulations’ of neurons, etc. – and more options are on the horizon. IBM recently published a paper around phase-change memristor technology that shows promise.
While a great deal of progress in neuromorphic computing has been accomplished, thorny issues remain. For example, it’s still not clear what the base technology should be – CMOS chips, wafer scale lithographic ‘emulations’ of neurons, etc. – and more options are on the horizon. IBM recently published a paper around phase-change memristor technology that shows promise.
The wafer scale integration used for BrainScaleS is probably the most novel and brain-like approach so far. During the post-presentation discussion, questions arose around process and device variability and degradation issues for various technologies.
Meier noted, “There is no degradation in the sense of aging. CMOS systems stay as bad or as good as they are. Nano devices still show some endurance problems. The big challenge for the BrainScaleS system is the static variability arising from the CMOS production process. This is like “fixed pattern noise“ on a CCD sensor. You can calibrate it but for really large systems we have to learn how to implement homeostatic“ adaptation like in biology. Our new digital learning center concept will just be doing that.” (http://www.kip.uni-heidelberg.de/vision/research/dls/)
About memristor technology Meier said, “really cool devices, but people have so far totally ignored the aspect of variability. It’s much, much bigger than CMOS. I don’t see how you can calibrate a memristor in a large circuit. [With CMOS] you can calibrate the synapse on a neuron because there are parameters, and SRAM to store the parameters. You can measure and if it doesn’t work too well and I can fix it by going in and calibrating it. How do you do that with memristors?”
Challenges aside, the IBM-LLNL project and two European systems should help accelerate neuromorphic development. Meier notes that access to SpiNNaker and BrainScaleS is not restricted to Europeans although restrictions for some countries exist due to national technology export law.
“There are plenty of users for the small prototype systems. The SpiNNaker boards are in particular attractive because they can be used by anyone trained in standard software tools. There are more than 100 users. The small scale BrainScaleS system has attracted about 10 users but the use is very different from normal computers so people struggle more. The numbers of external users of the HBP collaboratory (including all platforms) is shown in the attached plot. About 10% of them are using the large scale NM systems,” said Meier. Here are a handful of access points:
- “The large scale hardware systems are now available through a HBP web interface called “collaboratory.” (https://www.humanbrainproject.eu/ncp)
- Smaller scale single (or few) chip systems are available through remote access or purchase/loan: http://www.kip.uni-heidelberg.de/vision/research/spikey/
- For information on SpiNNaker contact Furber at the University of Manchester, U.K.
- Software tools to configure and control the systems are described in the Neuromorphic Guidebook.
 “Clearly the machines we are building at the moment are research devices but they have one important feature, they are really extremely configurable. In particular you can also read out the activity of network because you want to understand what is going on,” said Meier. This will change when putting neuromorphic systems into real-world practice.
“Clearly the machines we are building at the moment are research devices but they have one important feature, they are really extremely configurable. In particular you can also read out the activity of network because you want to understand what is going on,” said Meier. This will change when putting neuromorphic systems into real-world practice.
“Our idea on long term development is to give up on configurability and to give up on monitoring because if you have a neuromorphic chip, for example, that has to detect certain patterns you don’t really want to look as a user on your cell phone, you don’t want to read out any membrane potential or look at all the spike transistors, and look at all the correlations. You just want the thing to work.”
Large-scale systems, similar to those described here, are more likely to be used “to develop circuits that are interesting, that solve interesting problems. Then you export it and you make special dedicated chips optimized to solve this single problem without any configurability or monitoring capability.”
Think neuromorphic FPGAs, said Meier, “You want a dedicated things that can be mass produced and does one thing very well. That’s the way I see it evolving.”
One issue is implementaing local learning (on chip) when the device is in the field, enabling the system to adapt to changing environments. It would open up a new range of applications, agreed Meier, “There’s a study under way now looking at how a car engine changes all the time, its performance changes, and you always want to optimize the efficiency of the engine. It would be really nice to have these local learning capabilities on chip on the system in the field being applied.” There are no technical barriers in theory he said, but still missing technology components.
Nearer term, Meier is optimistic that accelerating learning will occur and that it represents the needed enabler for broader use of neuromorphic computing and for shortening time needed for training. Spike-based systems will play a role here, he believes – “there is very good argument to say the spikes are not only contributing to energy efficiency but also for learning speed. Once you accelerate learning it will be breakthrough for this technology and may change the way you compute fundamentally.”
Slide Source: Prof Karlheinz Meier presenation at ISC2016 (Neuromorphic Computing Concepts, Achievements & Challenges)

























































