 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
High performance computing (HPC) systems are comprised of multiple compute nodes interconnected by a network. Previously these nodes were composed solely of multi-core processors, but nowadays they also include many-core processors, which are called accelerators. Although accelerators provide higher levels of parallelism, their inclusion in HPC systems results in more complex system designs and increases the difficulty of quantifying the runtime behavior of applications that employ them. This is because performance metrics are used to explain application runtime behavior, and there is no consistency in the number or types of metrics exposed by dissimilar computing devices. Furthermore, differences in the designs of devices, i.e., their architectures, can make it impossible to directly compare exposed metrics.
Nevertheless, after identifying the performance metrics exposed by the Kepler and Fermi architectures of the NVIDIA GPUs and the Many Integrated Core (MIC) architecture of the Intel Xeon Phi, we attempted to map them to the performance of the LULESH 1.0 proxy application (a code that has become key to DOE co-design efforts for Exascale). Application execution time and power/energy consumption were compared, and runtime behavior was evaluated in terms of vectorization usage, instructions executed per cycle, and memory access. The results of this comparison, which considered architectural differences when determining the best way to compare some of these metrics, are summarized in our XSEDE16 publication. Here we present selected results, focus on some of the challenges we encountered, and highlight the need for a standard means of comparing devices with different architectures.
Performance Comparison
Given the simplicity of the runtime measurement, one would think it could be measured in a consistent way across different computing devices. However, this is only the case for devices with similar architectures. As shown in Figure 1, on both a standard Intel multi-core processor and the many-core Intel Xeon Phi, the function gettimeofday () is used to collect timestamps prior to and after a code segment to determine its runtime, which is the time elapsed between the timestamps.
In contrast, as illustrated in Figure 2, on NVIDIA GPUs, using CUDA’s event API, this is accomplished by creating two CUDA events that are used to record the timestamps, synchronizing the processing units, and then computing the runtime. Although different, both methods use the same unit of measurement and, thus, the runtimes can be compared directly.
Applying these methods to measure the runtimes of LULESH 1.0 for three different problem sizes, i.e., a 503, 703, and 903 mesh, on the target accelerators resulted in the data presented in Figure 3. As shown, LULESH consistently ran fastest on the Kepler GPU; it ran about seven times faster than on the other accelerators. And, although the Xeon Phi outperformed the Fermi, the differences between their runtimes were less than 20%.
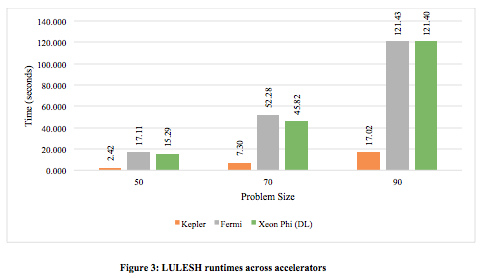
Performance Analysis
But a comparison of application runtimes does not tell the whole story. For example, it is important for hardware designers and application programmers to know why one device outperforms another. This requires understanding how well an application employs device resources. For example, the average number of instructions that a device executes during each clock cycle (IPC) determines the instruction-level parallelism and can help determine the application’s parallel efficiency. But, measuring this requires the use of performance tools and, unfortunately, none supports comparative analysis of different architectures. Accordingly, different tools must be used to collect similar performance data across devices with different architectures. For instance, LULESH’s IPCs were determined using the NVIDIA Visual Profiler (NVVP) on the Fermi and Kepler GPUs, and the Performance API (PAPI) on the Xeon Phi.
NVVP executes an instance of LULESH multiple times to collect performance metrics such as IPC. On the other hand, unlike NVVP, the use of PAPI requires source code modifications and one or more executions of LULESH depending on the number and types of metrics that are being collected; one execution is required to collect the metrics needed to compute IPC.
Unlike the runtime measurements, the GPU and Xeon Phi IPC measurements are not directly comparable. This is because, with NVVP, performance data was collected per streaming multiprocessor of the GPUs (SMX) but, with PAPI, due to restrictions on the amount of data that can be recorded simultaneously, only data for one Xeon Phi thread was collected. Regardless, using knowledge of the device architectures, we were able to compare the IPCs achieved by LULESH on the three accelerators. As can be seen in Figure 4(a), each SMX on a Kepler (and, similarly, a Fermi) GPU distributes work across schedulers (WSi) that launch a group of threads (tj), which execute in parallel on its processing units. In contrast, as shown in Figure 4(b), a Xeon Phi core distributes its work across its four available hardware threads.

Comparing the IPC of a Xeon Phi thread (IPCthread ) directly to that of a GPU SMX (IPCSMX) would be unfair since a Xeon Phi thread does not distribute its work to other processing units. Thus, to compare the IPCs that LULESH achieved on the target accelerators, we used the IPCthread of the Xeon Phi and, since the Xeon Phi has a dual-issue pipeline, multiplied IPCthread by two to compute the IPC of one of its cores, i.e., IPCcore. Table 1 shows the IPCcore of the Xeon Phi compared to the IPCSMX of the Kepler and Fermi GPUs across the three problem sizes.
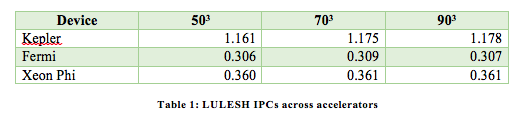
Similar to the runtimes, LULESH achieves the highest IPCs on the Kepler GPU. And, the IPCs of the Fermi and the Xeon Phi are comparable, i.e., they differ by less than 20%, with those of the Xeon Phi being higher than those of the Fermi. In particular, LULESH’s IPCs on the Kepler were up to three times higher than on the Fermi and Xeon Phi, and they increased with the problem size. As a result, it can be concluded that, for the three problem sizes studied, LULESH 1.0 scaled well on the Kepler GPU.
Conclusion
In the case of processor design, the needs of applications will continue to drive the introduction of new device architectures. As a result, HPC systems will become more heterogeneous, and application developers will have a wide array of fast computing devices on which to run their applications. However, without a means to compare the performance of devices with different architectures, it will remain difficult to determine whether a program should be launched solely on multi-core processors or should employ accelerators, which accelerators should be employed, and how new accelerators should be designed.
Currently, a methodology to explain why one device outperforms another with a dissimilar architecture is premature. This is due to the limited number of metrics exposed by each device. Since exposed metrics are not directly comparable due to the architectural differences of each device, methods are needed to compare them.
Nonetheless, we executed LULESH 1.0 on the Intel Xeon Phi and the Fermi and Kepler GPUs, collected exposed metrics on each device, and mapped them to application performance. Although we were able to shed some light as to why LULESH’s runtime differs on the target accelerators, comparative analysis of devices with different architectures is still an open and very important problem.
About the Authors
 Esthela Gallardo is a Ph.D. student at the University of Texas at El Paso, where she earned Bachelor of Science and Master of Science degrees in Computer Science. Her dissertation topic involves enhancing the MPI Tool Information Interface (MPI_T) support provided by MPI libraries to enable the automation of MPI performance optimization. This topic was motivated by her internship at the Texas Advanced Computing Center (TACC), where she helped develop a tool that makes use of MPI_T to identify common MPI performance bottlenecks in large-scale applications and provide suggestions to avoid them. Esthela also interned at the Lawrence Livermore National Laboratory where she ported optimizations of the OpenMP version of the LULESH application to a CUDA version and evaluated the changes in performance.
Esthela Gallardo is a Ph.D. student at the University of Texas at El Paso, where she earned Bachelor of Science and Master of Science degrees in Computer Science. Her dissertation topic involves enhancing the MPI Tool Information Interface (MPI_T) support provided by MPI libraries to enable the automation of MPI performance optimization. This topic was motivated by her internship at the Texas Advanced Computing Center (TACC), where she helped develop a tool that makes use of MPI_T to identify common MPI performance bottlenecks in large-scale applications and provide suggestions to avoid them. Esthela also interned at the Lawrence Livermore National Laboratory where she ported optimizations of the OpenMP version of the LULESH application to a CUDA version and evaluated the changes in performance.
 Patricia Teller is a Professor of Computer Science at the University of Texas at El Paso. She attained her Ph.D. in Computer Science at New York University, where she worked in the Ultracomputer Research Lab. Over the past 20 years, her research, and that of her students, has encompassed many topics associated with HPC performance including power/energy consumption, MPI communication, I/O scheduling, emerging technologies, memory subsystems, operating systems, and workload characterization. This work has resulted in over 100 publications as well as support from many sources including the Army Research Laboratory, Defense Advanced Research Projects Agency, Department of Defense, Department of Energy, IBM, National Aeronautics and Space Administration, National Science Foundation, and Sandia National Laboratories.
Patricia Teller is a Professor of Computer Science at the University of Texas at El Paso. She attained her Ph.D. in Computer Science at New York University, where she worked in the Ultracomputer Research Lab. Over the past 20 years, her research, and that of her students, has encompassed many topics associated with HPC performance including power/energy consumption, MPI communication, I/O scheduling, emerging technologies, memory subsystems, operating systems, and workload characterization. This work has resulted in over 100 publications as well as support from many sources including the Army Research Laboratory, Defense Advanced Research Projects Agency, Department of Defense, Department of Energy, IBM, National Aeronautics and Space Administration, National Science Foundation, and Sandia National Laboratories.


























































