 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Not long after revealing more details about its next-gen Power9 chip due in 2017, IBM today rolled out three new Power8-based Linux servers and a new version of its Power8 chip featuring Nvidia’s NVLink interconnect. One of the servers – Power S822LC for High Performance Computing (codenamed “Minsky”) – uses the new chip (Power8 with NVLink) to communicate with P100 Pascal GPUs, NVIDIA’s most recent and highest performing GPU.
The other servers – the Power S821LC and the Power S822LC for Big Data – also leverage GPU acceleration technology (K80 or P100) via PCIe interface and have IBM’s Coherent Accelerator Processor Interface (CAPI) for use with Flash storage and FPGAs. All three servers are standard two-socket additions to IBM’s Linux line.
These introductions, said Sumit Gupta, vice president, High Performance Computing and Analytics, IBM, should be seen as proof of IBM’s ongoing commitment to its vision of accelerated computing as the new paradigm, and of cognitive computing (writ large) and big data analytics as the major drivers (See HPCwire article, Think Fast: IBM Talks Acceleration in HPC and the Enterprise).
Also noteworthy is that the new systems are manufactured by partners. “All three of these OpenPOWER systems leverage the strengths and expertise of OpenPOWER partners, from acceleration capabilities to strengths in design and manufacturing. In the spirit of open we hope that our Industry partners who are manufacturing these systems, Wistron, an OpenPOWER partner, and Supermicro, will deliver Power-based servers to their clients through their routes to market in order to proliferate the OpenPOWER ecosystem,” said Gupta.

IBM says the S822LC server with NVLink embedded at the silicon level “enables data to flow 5x faster” than on a comparable x86-based system. It also substantially reduces the programming barrier to aggressive use of GPUs according to Gupta who has written a more detailed blog on the introductions. This is the first Power8-based system delivered with NVLink according to IBM.
“Moving data from the CPU to the GPU [has been the] bottleneck because with most systems most of it is going through this thin pipe, PCIe. With NVLink the GPU has access to up to half a terabyte of memory that sits on the CPU side of that interconnect,” Gupta told HPCWire. NVLink allows improved transfer of data between both processors which fundamentally makes it easier to program.
“When an application starts, all the data is sitting in the system memory, and you’ve got to move chunks of it over to the GPU,” Gupta continued. “NVLink does three things. It improves the performance because we’ve enabled a fatter pipe between the processors. It enables you to move smaller functions. And it makes programming accelerators easier because you have to do less data management.”
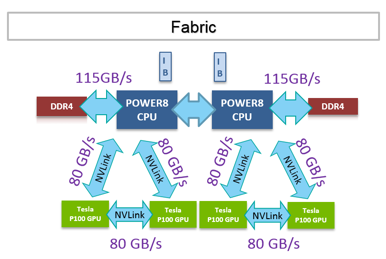
The new Power8 with NVLink processor features 10 cores running up to 3.26 GHz. POWER8 processors in this server have higher memory bandwidth than x86 CPUs, at 115 GB/s and can have as much as ½ a terabyte of system memory per socket. There are larger caches per core inside the POWER8 processor, and this coupled with the faster cores and memory bandwidth leads to higher application performance and throughput.
The new NVIDIA Tesla P100 GPU accelerator increases floating point performance, delivering 21 teraflops of half-precision, 10.6 teraflops of single-precision, and 5.3 teraflops of double-precision performance. The accelerator includes 16 gigabytes of the HBM2 stacked memory with an on-GPU memory bandwidth of 720 gigabytes per sec (GB/s). The NVIDIA Tesla P100 with NVLink GPU in the SXM2 form factor delivers 14 percent more raw compute performance than the PCIe variant.
Using NVLink, writes Gupta in his blog, provides three major advantages to application acceleration:
- Performance: The new Power8 with NVLink processor and the new Tesla P100 GPU have four NVLink interfaces that enable “5x faster communication than a PCIe x16 Gen3 connection used in other systems.” This enables faster data exchange and application performance, by overcoming the limitation of narrow PCIe data pipe into the GPU.
- Programmability: The CUDA 8 software and the Page Migration Engine in Tesla P100 enable a unified memory space with automated data management between the system memory connected to the CPU and the GPU memory. Coupled with NVLink, unified memory makes programming GPU accelerators much easier for developers. Applications can be easily accelerated with GPUs by incrementally moving functions from the CPU to the GPU, without having to deal with data management.
- More application acceleration: Since NVLink reduces the communication time between the CPU and GPU, it enables smaller pieces of work to be moved to the GPU for acceleration. This means that more parts of an application can be GPU accelerated.
In making the announcements, IBM continued ratcheting up its ‘we’re-better-than-Intel’ rhetoric. Its broad application targets encompass all things big data and analytics, as well as deep learning and cognitive computing.
“The big advantage we are seeing for Power8 in the market has been around data analytics, databases, and high performance computing for machine learning and deep learning, and artificial intelligence,” said Gupta. “Because we have faster cores, we see much better performance, [for example], on databases compared to Intel-based systems. Applications like kinetica, which is an accelerated (GPU optimized) database for deep learning and machine learning, gets the value of NVLink high speed data connection between CPU and GPU.”
Recognizing the uphill battle in winning x86 market share, IBM in the past has emphasized efforts to penetrate hyperscalers as pivotal to its success (see HPCwire article, Handicapping IBM/OpenPOWER’s Odds for Success).
According to the IBM release: “Early testing with one of the world’s largest Internet service providers (Tencent) based in China has shown that a large cluster of the new Power S822LC for Big Data servers was able to run a data-intensive workload three times faster than its former x86-based infrastructure. Moreover, this result was achieved while reducing the total number of servers used by two-thirds. Given the significant cost benefits of using fewer servers to deliver faster performance, the company is now integrating the new LC servers into its hyperscale data center for big data workloads.”

Gupta maintains there’s a big appetite for new Power8-based servers despite the advancing Power9. “Several businesses, research organizations and government bodies have pre-tested early systems and placed their orders. Among those first in line to receive shipments are a large multinational retail corporation and the U.S. Department of Energy’s Oak Ridge National Laboratory (ORNL),” according to the IBM release.
ORNL will use the new systems as a development platform for optimizing applications to take advantage of the built-in NVLink interface technology. The systems will serve as an early-generation test bed for developing demanding applications for Summit, ORNL’s next generation supercomputer that IBM will deliver in 2017 and which will use the Power9 chip. Arthur S. (Buddy) Bland, OLCF project director, is quoted in the press release saying, “As a long-time user of GPUs, we believe that this will improve the performance of our applications and make it easier for the users to deliver great science.”
Building an ecosystem is hard. For IBM and OpenPOWER, many of the diverse pieces needed are seemingly falling into place. Time will tell.
Link to Gupta’s blog: www.ibm.com/blogs/systems/ibm-nvidia-present-nvlink-server-youve-waiting
Image source: IBM


























































