 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
Stanford researchers are leveraging GPU-based machines in the Amazon EC2 cloud to run deep learning workloads with the goal of improving diagnostics for a chronic eye disease, called diabetic retinopathy. The disease is a complication of diabetes that can lead to blindness if blood sugar is poorly controlled. It affects about 45 percent of diabetics and 100 million people worldwide, many in developing nations.
Final-year Stanford PhD students Apaar Sadhwani and Jason Su got involved in developing the diagnostic solution as part of a class project and corresponding Kaggle competition that was held last year. Sponsor Amazon provided AWS cloud credits in support of the research.
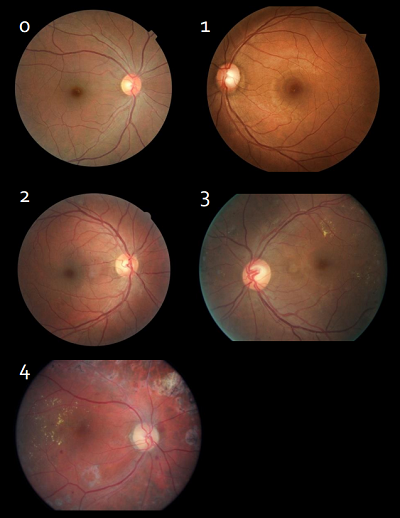
After Kaggle, the duo decided to turn their research project into a cloud-based platform that hospitals and clinics can use to guide the diagnosis of eye diseases. Their approach relies on a convolutional neural net (CNN) that grades the severity of diabetic retinopathy disease states into five categories: 0-4, with 0 being normal and 4 being the most severe.
The researchers have been training their model with a data set of 80,000 images from EYEPACS, a web-based application for exchanging eye-related clinical information, run by the California Health Foundation. “Getting data is the most constraining part of applying deep learning to a medical setting,” said Sadhwani, “but we are working closely with partners to get more data.”
They’ve also had to address a class imbalance in the data set. “We have a lot more 0’s and 1’s than 3’s and 4’s, for example,” said Sadhwani. As the disease progresses to stage four (known as proliferative diabetic retinopathy, or PDR), image data is more rare. A total of about 10,000 stage four images are required for optimal results.
The training problem is run on AWS Elastic Compute Cloud (EC2) with single-GPU and multi-GPU nodes. Some S3 storage and Elastic Block Store (EBS) services are also employed. The training takes about three days to a week for a given model.
Within EC2, the researchers are using Starcluster which lets them build custom clusters among the nodes and network them together. They used a master node to store all their training data and up to 28 different training nodes. All these separate training nodes would access the master node so they wouldn’t have to mirror the data onto each of the nodes.
“With Starcluster and AWS you can bring up different node types independently on demand,” said Su. “So we would run this experiment that would only need a single-GPU node and then after that finished we could shut down that node and save money. Then we would scale it up to a larger resolution image and we would need four-GPU nodes for that – so we’d spin that up, train on that, and come back three days later and shut that off. AWS provides this flexibility for scaling up and scaling down for cost and for trying out different ideas.”
The researchers relied on AWS spot instance pricing to further improve the economics. Their program saves a state every “epoch,” which relates to one pass through the data set, so losing a node did not incur a big setback. With 55 epochs in a run, the most they would lose is 1/55th of their training progress.
They used the g2.2xlarge instance type and the g2.8xlarge instance type for training their final models. They trained two kinds of models, one on low-res images and the final model on high-res images, for which they employed the larger multi-GPU nodes.
Amazon’s GPU instances are based on older Nvidia GRID K520 graphics cards, which at 4 GB per GPU do not have an ideal memory profile for training based on very high-resolution images.
“Typically in deep learning, you have a 256×256 image, or about one-sixteenth of a megapixel and we’re at four megapixels, so memory is a huge part of doing this problem,” said Sadhwani. “Our workaround was to scale to 4-GPU nodes, which effectively had 4 gigabytes of memory each [GPU], but we lose some to overhead because we have to have the model independently at each of the separate GPUs. It would be more advantageous to have a single GPU with a full 16 gigabytes.”
Because their model was dealing with these high-resolution images, they used Torch to split it across the 4-GPU node to fine-tune its parameters. Currently, they are moving to a distributed training model, which enables several different nodes to train essentially the same model but with independent data. This gives them the ability to train one model across many GPUs, rather than a single model on a single GPU node and thus accelerates the training.
The researchers are eyeing clouds with higher-memory GPUs, which could mean holding out for upgraded Amazon instances or moving to the Microsoft Azure cloud with its Tesla K80s.
They are not interested in CPUs. “It would take significantly longer, at least a factor of 50,” said Sadhwani. “The kind of neural networks we are using [convolutional neural nets] harness parallelization a lot. Even if we were not using this special class of network, there is at least a 10x speedup going from CPUs to GPUs, but for this particular variety that speedup is magnified a lot more, in the neighborhood of 100x.”
Diabetic retinopathy is a disease of the blood vessels in the eye. As the sugar level in the blood rises, it causes the walls of the blood vessels to thin and eventually they’ll crack and bleed. The most important thing to look for is tiny dot bleeds, called hemorrhages. They are very small and difficult to locate even with advanced algorithms. The deep learning model must also be trained to ignore or flag likely camera artifacts, which appear in approximately 40 percent of the images, and can obscure identification of disease traits.
To address these challenges, the Stanford team’s approach uses two networks, a lesion detector and a main network. The lesion detector looks at a small part of the image and outputs a number between 0 and 1, a probability. The lesion detector has so far achieved an accuracy of 99 percent for negatives and 76 percent for positives. The purpose of the main network is to characterize details about where the disease-related features are with respect to the important parts of the eye.
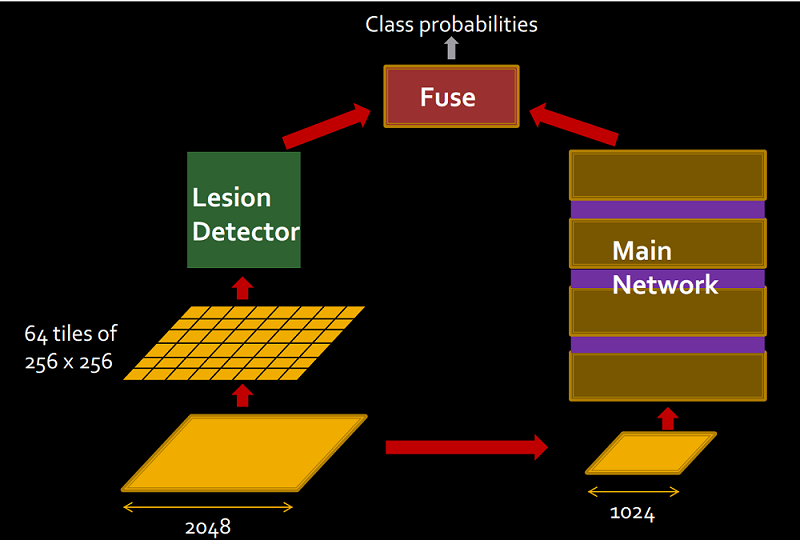
The outputs of these two pipelines are then fused together. This provides a way to combine low-level details about where there are dot hemorrhages with high-level information like which parts of the image should actually be ignored because they are corrupted by artifacts. The fuse network is responsible for integrating all these signals together to deliver a final probability for the disease class.
Right now the team has been working with five classes, but they say that in the clinical setting, these grades are not tracked with such granularity. In terms of intervention, there are really three stages: 0) no action is required; 1) monitor the progress of the disease; and 2) medical intervention such as surgery is required.
“Moving to three-classes would increase the accuracy of our models because it’s a simpler problem and easier to solve,” said Su.
The ultimate goal here is to deliver a digital assistant to radiologists, opthamologists and other clinicians, so they can screen more patients, more frequently.
“Using an automated tool to augment human resources, you can more closely monitor the changes in the disease state as they progress to more effectively treat the disease,” said Su.


























































