 Datanami
Datanami EnterpriseAI
EnterpriseAI HPCwire Japan
HPCwire Japan QCwire
QCwire HPC & AI Wall Street
HPC & AI Wall Street
When Dr. John D. McCalpin introduced the STREAM benchmark in 1991, it had already become become clear that peak arithmetic rate was not an adequate measure of system performance for many applications. Since then, CPU performance has continued to outpace memory performance measures, leading to the processor-memory speed gap, known as the memory wall. In an invited talk at SC16, McCalpin will review the history of the changing “balances” between computation, memory latency, and memory bandwidth in HPC systems and will address the implications for the coming generation of systems.
Ahead of his talk at SC16, McCalpin gives us a peak into his activities at TACC, where he holds posts as HPC research scientist and co-director of ACElab, and provides an in-depth commentary on the dynamics between compute and memory in the context of the evolving HPC landscape.
HPCwire: What is the focus of your work at the Texas Advanced Computing Center (TACC)?
Dr. John D. McCalpin: My work at TACC is primarily focused on understanding the performance characteristics of current and forthcoming hardware, and understanding the interactions between the hardware and the applications that we have identified as making up important parts of the workloads for TACC’s HPC-oriented systems. This involves a great deal of “detective work” – designing microbenchmarks to test various hypotheses about how the machines actually work at a low level, and designing tests to understand whether the hardware performance counters are counting what we think they are counting. The hardware performance counters that are useful are then used to track performance characteristics of all jobs run on our systems, which is useful for both finding misconfigured jobs and for finding out which attributes of the system are important for various application areas.
HPCwire: TACC has such a diverse array of HPC machines. I imagine that having access to many different architectures is important to your research.
McCalpin: Diversity is clearly both a blessing and a curse. The good part of diversity is being able to test different system configurations and interconnect fabrics and allocate users to systems that are configured appropriately for their workloads. The bad part of diversity is having to deal with surprisingly large differences in nomenclature and software infrastructure (especially with respect to BIOS options) across vendors – even for identical processors. In addition to being able to test codes on different systems, a very useful tool has been the ability to control CPU frequency and memory frequency independently with recent processors. This allows us to run sensitivity-based performance analyses for a lot more codes than we would be able to analyze manually, and allows us to characterize applications even without subject-area expertise on staff.
HPCwire: Your upcoming talk at SC16 is titled “Memory Bandwidth and System Balance in HPC Systems” – what is your thesis?
McCalpin: My goal in this talk is to help people in the HPC community become aware of the extreme changes in HPC hardware over the last decade, and to argue that major architectural changes are needed to allow performance and price/performance to improve as rapidly as the underlying technology could allow. In some ways 2016-era HPC hardware looks like 2006-era HPC hardware – dominated by 2-socket commodity (x86) servers with a high-performance (typically InfiniBand) interconnect. At a lower level there has been an immense increase in hardware complexity to support the design goal of nearly-constant peak memory bandwidth per core, and it is this complexity that makes our current systems both incredibly difficult to understand and fundamentally ill-suited as starting points for either significant price reduction or significant power reduction.
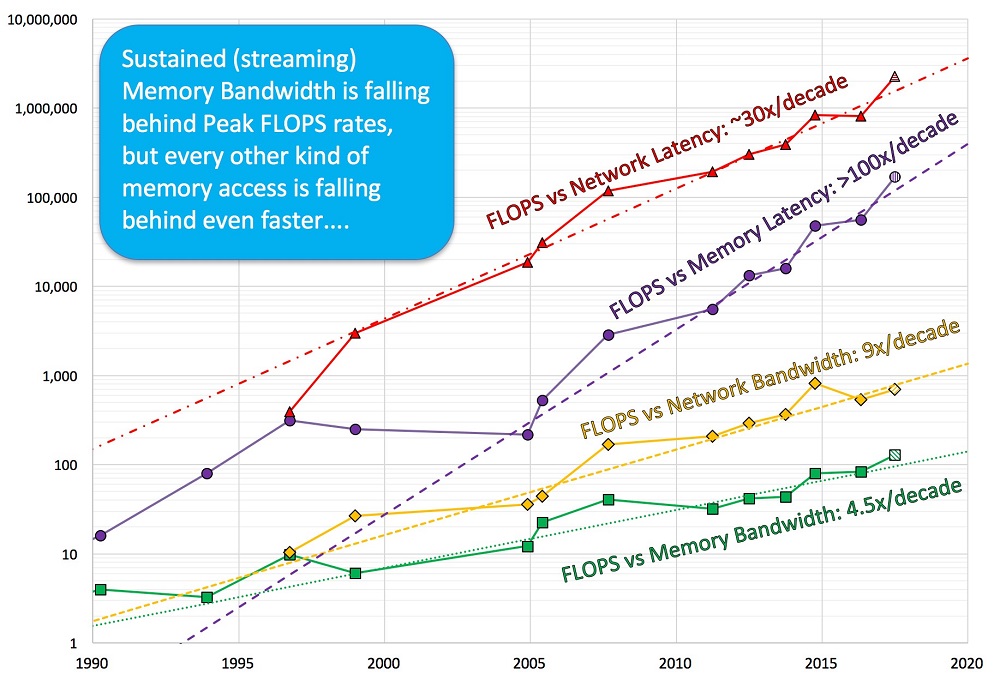
HPCwire: How have the dynamics between compute and memory evolved over time?
McCalpin: This is not an easy topic to summarize, but a few themes are worth noting. The first is that the HPC market has experienced several “disruptive technology” transitions, in which technology that was inferior in performance, but dramatically cheaper, replaced the dominant technology. We saw this happen in the mid-1990’s when RISC microprocessor-based systems displaced the traditional vector systems, and again starting around 2004 when x86-based systems displaced the RISC systems. A second recurring theme is the divergence between the high growth rate of FLOPS per core and the lower (or absent) growth rate in sustained memory bandwidth per core within each era. In the x86-multicore era of the last decade, the number of cores per package has increased and the sustained bandwidth per package has increased at about the same rate, but with constant (or slightly increasing) memory latency. This provides the third theme – the rapidly increasing relative cost of memory latency relative to computation. The approximately constant memory latency also drives the fourth theme – the overwhelming dominance of memory concurrency in determining sustained bandwidth. With sustained processor performance almost flat, compute performance is largely determined by how many cores you are able to use. With memory latency about flat, memory bandwidth per package is largely determined by how many outstanding cache misses you can generate.
HPCwire: In what ways will exascale further challenge system balance?
McCalpin: The traditional design point of “1 Byte/second per FLOP/second” does not look possible for exascale systems with current technology trends – both the purchase price and the power consumption are too high. The straight-line projection for exascale points to systems with extremely high compute capability per unit of bandwidth. These will be effective for a very limited number of applications. In the absence of a solid “general-purpose” design point, a more focused fallback position may be to develop multiple “special-purpose” systems, with architectures and implementations customized for a small number of particular applications of interest. This would allow substituting hundreds of millions of dollars of design and implementation expense for hundreds of millions of dollars of “general-purpose” hardware that is not well-matched to the specific application requirements.
HPCwire: What class of high-performance computer is best positioned to address memory bottlenecks?
HPC has been dominated by clusters of two-socket x86 nodes, which definitely have an easier time of providing bandwidth than larger SMP nodes. There are several reasons to believe that this design point has been pushed about as far as possible, and the introduction of a new layer of high-speed in-package memory will provide strong motivation to switch to single-socket nodes to eliminate off-chip cache coherence traffic. More radical possibilities will also be required (discussed below), but it is less clear how long that more painful transition can be put off.
HPCwire: Are you seeing advances on the algorithm and programming side to minimize data costs?
McCalpin: There has been some improvement in many application areas simply because more complex simulations are naturally more computationally dense, and therefore more likely to be limited by computation and less likely to be limited by memory access. This improvement has been partly deliberate, but also largely accidental – a happy byproduct of moving to more complex problems. Some applications can tolerate high memory access costs, but for applications that are not compute-bound we are significantly burdened by hardware architectures that do not allow data motion to be visible or controlled. This was the right answer in 1990, when arithmetic was much more expensive than memory reference, but in the current technology regime it is only justifiable by compatibility with the huge installed base of code – it would certainly not be the way to design an architecture for current technology balances or for expected technology balances in the remainder of the CMOS era. There have been attempts to provide programming languages and models to address data motion, but these have not been successful – programming languages can’t exploit hardware features that don’t exist, and can’t control behavior that is intended to be invisible. For many of the same reasons, we also tolerate architectures that are not energy-efficient because high per-node purchase prices have kept the energy costs relatively small (typically 5-7 percent of the initial purchase price per year of operation).
HPCwire: You introduced the STREAM Benchmark in 1991 — what is it and what trends have you documented?
McCalpin: The STREAM benchmark is a very simple, self-contained benchmark code (in C or Fortran) that measures the rate at which a system can perform four simple long-vector operations on floating-point numbers. For systems with caches, the standard way to configure the benchmark is to select an array size such that each of the three arrays used is much larger than the available cache(s), so that essentially all of the data accesses result in reads from memory or writes to memory. The benchmark is set up to time each iteration of each kernel and print out the computed memory access rate (reads + writes) for the fastest iteration of each kernel. When users are kind enough to submit results for publication, I add information that allows me to compute peak arithmetic performance and the balance between peak compute rates and sustained bandwidth. STREAM has been instrumental in getting vendors to pay attention to sustained, rather than peak, bandwidths, and the almost 1100 results in the database provide documentation of the trends and transitions I addressed above.
HPCwire: What is the path forward — are there technologies on the horizon that address the system imbalance issues that you’ve outlined?
McCalpin: It is important to note that “imbalance” is a relative term – in this case “relative” to the demands of the applications of interest. There are major application areas that are not yet experiencing performance limitations due to memory latency or sustained memory bandwidth. On the other hand, as the balances shift, applications that used to be completely compute-limited may now be strongly bandwidth-limited on current systems. (An excellent example of this is the local-area weather code WRF – when I reviewed it in 2006 on dual-core Opteron systems the execution-time breakdown was about 30 percent memory access and 70 percent compute, but when I reviewed performance on Xeon E5 v3 processors (c. 2015) this breakdown had reversed to 70 percent memory access time and 30 percent compute time.) Emerging technologies such as stacked DRAM provide the ability to push more data through a chip, but not at low cost and not at low power. Basic physics makes it clear lower cost and lower power can only come from slower, simpler processors distributed across the system in close proximity to the elements of the distributed memory. This approach requires a low-cost, high-performance interconnect fabric that is designed to support low-overhead data motion and synchronization. A much larger challenge is the development of high-productivity programming languages and models that can effectively map to such a massively parallel, heterogeneous, distributed hardware platform.
 Dr. John D. McCalpin is a Research Scientist in the High Performance Computing Group and Co-Director of ACElab at TACC of the University of Texas at Austin. At TACC, he works on performance analysis and performance modeling in support of both current users and future system acquisitions.
Dr. John D. McCalpin is a Research Scientist in the High Performance Computing Group and Co-Director of ACElab at TACC of the University of Texas at Austin. At TACC, he works on performance analysis and performance modeling in support of both current users and future system acquisitions.

























































